理解 TiKV 中的 Stale Read 和 safe-ts
在本文档中,你可以了解 TiKV 中 Stale Read 和 safe-ts 的原理以及如何诊断与 Stale Read 相关的常见问题。
Stale Read 和 safe-ts 概述
Stale Read 是一种读取历史数据版本的机制,读取 TiDB 中存储的历史数据版本。在 TiKV 中,Stale Read 依赖 safe-ts。如果一个 Region peer 上的读请求的时间戳 (timestamp, ts) 小于等于 Region 的 safe-ts,TiDB 可以安全地从 peer 上读取数据。TiKV 通过保证 safe-ts 总是小于等于 resolved-ts 来保证这种安全性。
理解 safe-ts 和 resolved-ts
本章节介绍 safe-ts 和 resolved-ts 的概念和维护方式。
什么是 safe-ts?
safe-ts 是一个由 Region 中的每个 peer 维护的时间戳,它保证所有时间戳小于等于 safe-ts 的事务已经被 peer apply,从而实现本地 Stale Read。
什么是 resolved-ts?
resolved-ts 是一个时间戳,它保证所有时间戳小于该值的事务已经被 leader apply。与 safe-ts 不同,resolved-ts 只由 Region leader 维护。Follower 可能有一个比 leader 更小的 apply index,因此 resolved-ts 不能直接被当作 safe-ts。
safe-ts 的维护
RegionReadProgress 模块维护 safe-ts。Region leader 维护 resolved-ts,并定期通过 CheckLeader RPC 将 resolved-ts、最小的(使 resolved-ts 生效的)apply index和 Region 本身发送给所有副本的 RegionReadProgerss 模块。
当一个 peer apply 数据时,它会更新 apply index,并检查是否有 pending resolved-ts 可以成为新的 safe-ts。
resolved-ts 的维护
Region leader 使用一个 resolver 来管理 resolved-ts。该 resolver 通过接收 Raft apply 时的变更日志来跟踪 LOCK CF (Column Family) 中的锁。当初始化时,resolver 会扫描整个 Region 来跟踪锁。
诊断 Stale Read 问题
本章节介绍如何使用 Grafana、tikv-ctl 和日志诊断 Stale Read 问题。
识别问题
在 Grafana > TiDB dashboard > KV Request 监控面板中,以下面板显示了 Stale Read 的命中率、OPS 和流量:
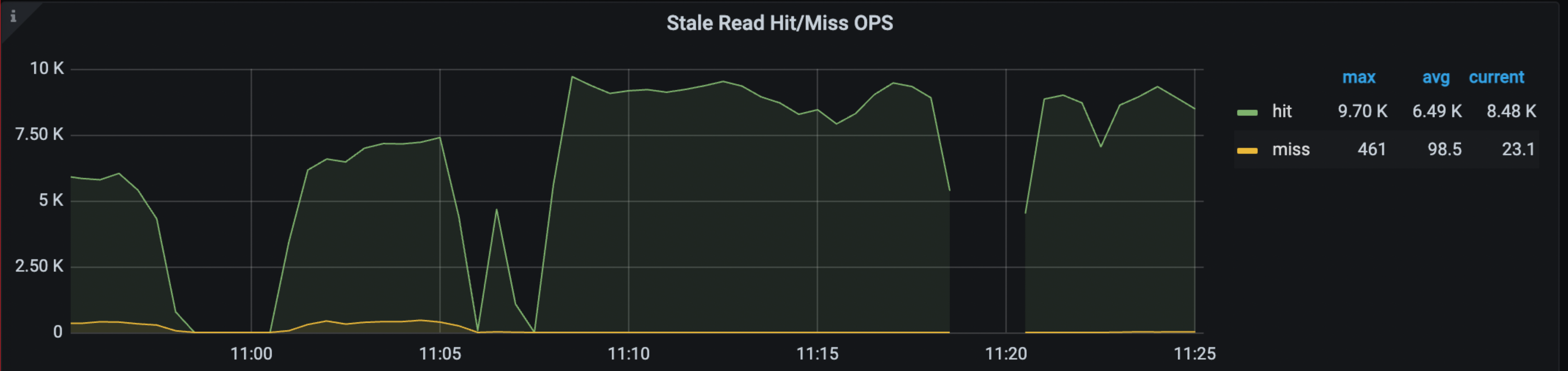
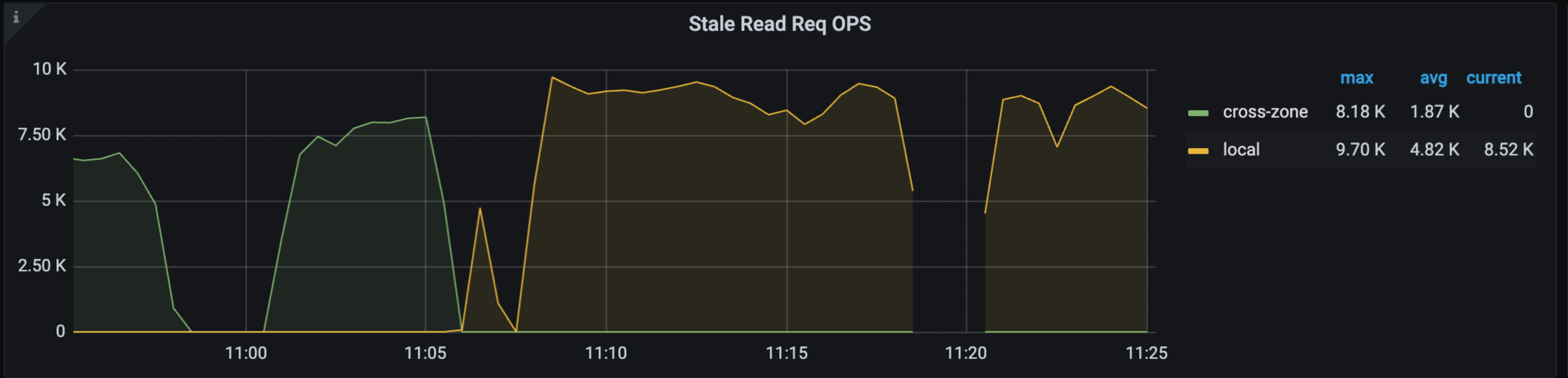
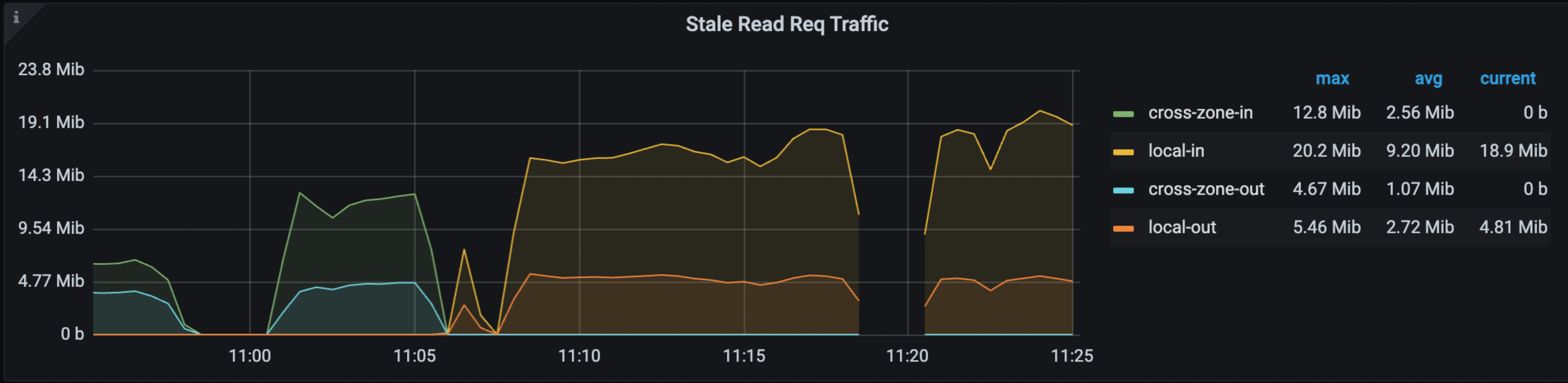
关于上述监控项的更多信息,参考 TiDB 监控指标。
当 Stale Read 问题发生时,你可能会注意到上述监控项的变化。最直接的指标是 TiDB 的 WARN 日志,它会报告 DataIsNotReady 和 Region ID,以及它遇到的 safe-ts。
常见原因
下面是影响 Stale Read 有效性的常见原因:
- 事务提交时间过长。
- 事务在提交前存在太长时间。
- 从 leader 到 follower 推送 CheckLeader 信息的延迟。
使用 Grafana 诊断
在 TiKV-Details > Resolved-TS 监控面板中,你可以识别每个 TiKV 上 resolved-ts 和 safe-ts 最小的 Region。如果这些时间戳明显落后于实时时间,你需要使用 tikv-ctl 检查这些 Region 的详细信息。
使用 tikv-ctl 诊断
tikv-ctl 提供了 resolver 和 RegionReadProgress 的最新详细信息。更多信息,参考获取 Region 的 RegionReadProgress 状态。
下面是一个使用示例:
./tikv-ctl --host 127.0.0.1:20160 get-region-read-progress -r 14 --log --min-start-ts 0
输出结果如下:
Region read progress:
exist: true,
safe_ts: 0,
applied_index: 92,
pending front item (oldest) ts: 0,
pending front item (oldest) applied index: 0,
pending back item (latest) ts: 0,
pending back item (latest) applied index: 0,
paused: false,
Resolver:
exist: true,
resolved_ts: 0,
tracked index: 92,
number of locks: 0,
number of transactions: 0,
stopped: false,
上面的输出结果可以帮助你判断:
- 锁是否阻塞了 resolved-ts。
- apply index 是否太小而无法更新 safe-ts。
- 当存在 follower peer 时,leader 是否发送了更新的 resolved-ts。
使用日志诊断
TiKV 每 10 秒检查以下监控项:
- resolved-ts 最小的 Region leader
- resolved-ts 最小的 Region follower
- safe-ts 最小的 Region follower
如果这些时间戳中的任何一个异常地小,TiKV 就会打印日志。
当你想要诊断一个已经不存在的历史问题时,这些日志尤其有用。
下面是日志的示例:
[2023/08/29 16:48:18.118 +08:00] [INFO] [endpoint.rs:505] ["the max gap of leader resolved-ts is large"] [last_resolve_attempt="Some(LastAttempt { success: false, ts: TimeStamp(443888082736381953), reason: \"lock\", lock: Some(7480000000000000625F728000000002512B5C) })"] [duration_to_last_update_safe_ts=10648ms] [min_memory_lock=None] [txn_num=0] [lock_num=0] [min_lock=None] [safe_ts=443888117326544897] [gap=110705ms] [region_id=291]
[2023/08/29 16:48:18.118 +08:00] [INFO] [endpoint.rs:526] ["the max gap of follower safe-ts is large"] [oldest_candidate=None] [latest_candidate=None] [applied_index=3276] [duration_to_last_consume_leader=11460ms] [resolved_ts=443888117117353985] [safe_ts=443888117117353985] [gap=111503ms] [region_id=273]
[2023/08/29 16:48:18.118 +08:00] [INFO] [endpoint.rs:547] ["the max gap of follower resolved-ts is large; it's the same region that has the min safe-ts"]
诊断建议
处理慢事务提交
提交时间长的事务通常是大事务。这个慢事务的 prewrite 阶段会留下一些锁,但是在 commit 阶段清理掉锁之前需要很长时间。为了解决这个问题,你可以尝试识别锁所属的事务,并找出它们存在的原因,例如使用日志。
下面是一些你可以采取的措施:
在
tikv-ctl命令中指定--log选项,并在 TiKV 日志中通过 start_ts 查找相应的锁。在 TiDB 和 TiKV 日志中搜索 start_ts,以识别事务的问题。
如果一个查询花费超过 60 秒,就会打印一个带有 SQL 语句的
expensive_query日志。你可以使用 start_ts 值匹配日志。下面是一个示例:[2023/07/17 19:32:09.403 +08:00] [WARN] [expensivequery.go:145] [expensive_query] [cost_time=60.025022732s] [cop_time=0.00346666s] [process_time=8.358409508s] [wait_time=0.013582596s] [request_count=278] [total_keys=9943616] [process_keys=9943360] [num_cop_tasks=278] [process_avg_time=0.030066221s] [process_p90_time=0.045296042s] [process_max_time=0.052828934s] [process_max_addr=192.168.31.244:20160] [wait_avg_time=0.000048858s] [wait_p90_time=0.00006057s] [wait_max_time=0.00040991s] [wait_max_addr=192.168.31.244:20160] [stats=t:442916666913587201] [conn=2826881778407440457] [user=root] [database=test] [table_ids="[100]"] [**txn_start_ts**=442916790435840001] [mem_max="2514229289 Bytes (2.34 GB)"] [sql="update t set b = b + 1"]如果你无法从日志中获取关于锁的足够信息,可以使用
CLUSTER_TIDB_TRX表查找活跃的事务。执行
SHOW PROCESSLIST查看当前连接到同一个 TiDB 服务器的会话及其在当前语句上花费的时间。但是它不会显示 start_ts。
如果锁是由于正在进行的大事务而存在的,考虑修改你的应用程序逻辑,因为这些锁会阻碍 resolve-ts 的进度。
如果锁不属于任何正在进行的事务,可能是由于协调器 (TiDB) 在预写锁之后崩溃。在这种情况下,TiDB 会自动解决锁。除非问题持续存在,否则不需要采取任何措施。
处理长事务
长时间保持活跃的事务,即使最终提交了,也可能会阻塞 resolved-ts 的进度。这是因为这些长期存在的事务的 start-ts 用于计算 resolved-ts。
要解决这个问题,你可以:
识别事务:首先识别与锁相关的事务,了解它们存在的原因。你可以使用日志帮助识别。
检查应用程序逻辑:如果长时间的事务持续时间是由于应用程序逻辑导致的,考虑修改应用程序以防止这种情况发生。
处理慢查询:如果事务的持续时间由于慢查询而延长,优先解决这些查询以缓解问题。
解决 CheckLeader 问题
为了解决 CheckLeader 问题,你可以检查网络和 TiKV-Details > Resolved-TS 监控面板中的 Check Leader Duration 指标。
示例
如果你观察到 Stale Read OPS 的 miss rate 增加,如下所示:
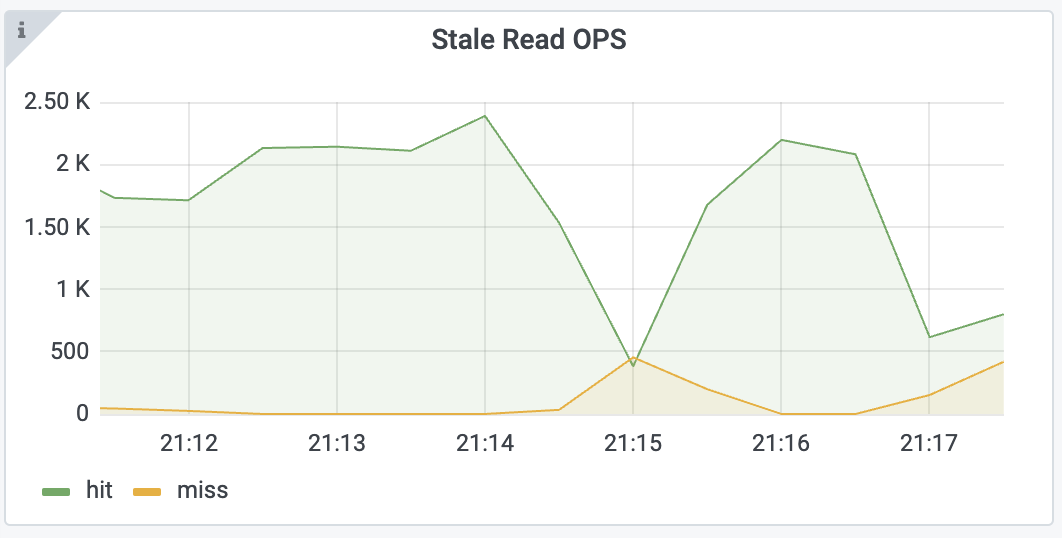
首先,你可以检查 TiKV-Details > Resolved-TS 监控面板中的 Max Resolved TS gap 和 Min Resolved TS Region 指标:
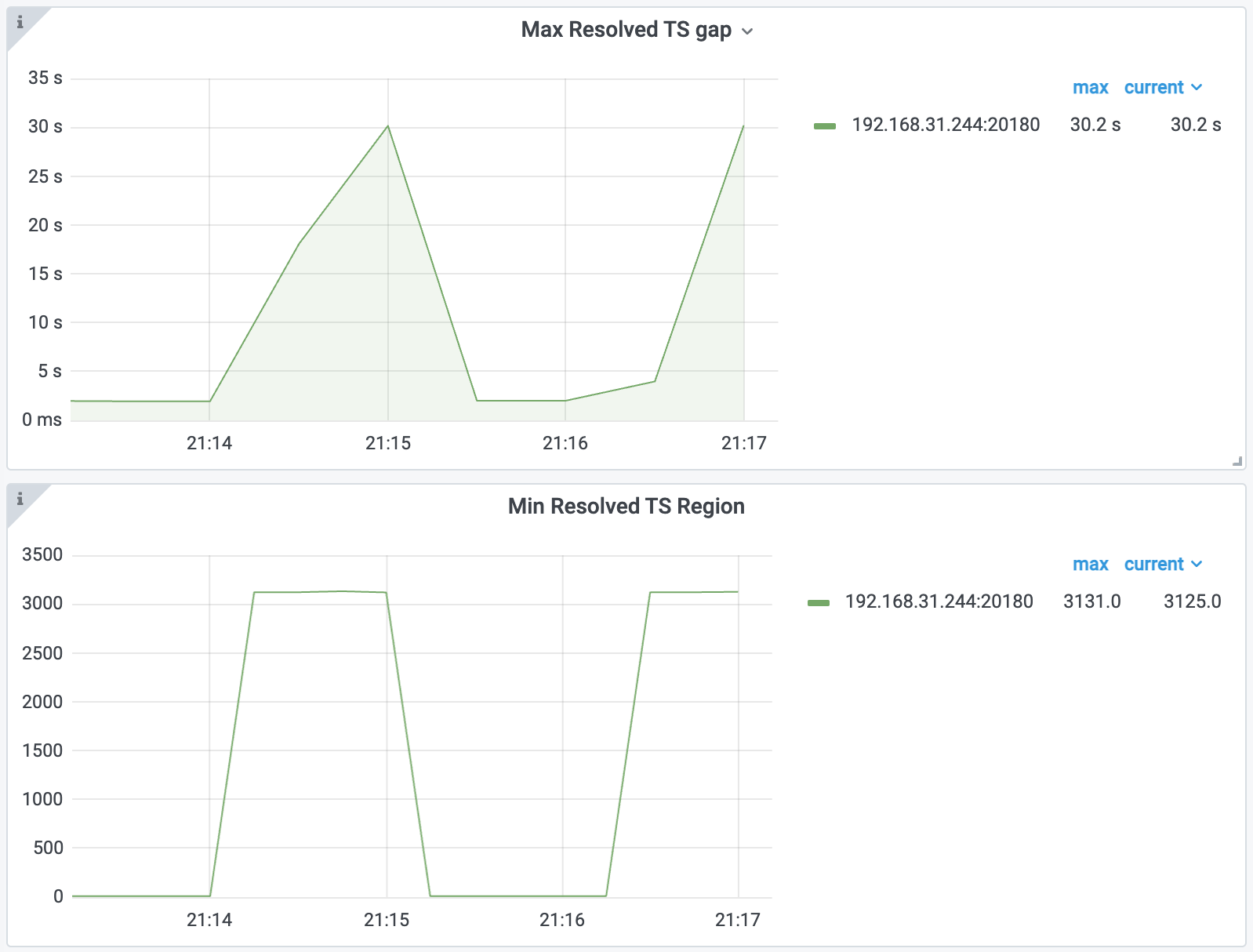
从上述指标中,你可以发现 Region 3121 和其他一些 Region 没有及时更新 resolved-ts。
为了获取 Region 3121 的更多详细信息,你可以执行以下命令:
./tikv-ctl --host 127.0.0.1:20160 get-region-read-progress -r 3121 --log
输出结果如下:
Region read progress:
exist: true,
safe_ts: 442918444145049601,
applied_index: 2477,
read_state.ts: 442918444145049601,
read_state.apply_index: 1532,
pending front item (oldest) ts: 0,
pending front item (oldest) applied index: 0,
pending back item (latest) ts: 0,
pending back item (latest) applied index: 0,
paused: false,
discarding: false,
Resolver:
exist: true,
resolved_ts: 442918444145049601,
tracked index: 2477,
number of locks: 480000,
number of transactions: 1,
stopped: false,
值得注意的是,applied_index 等于 resolver 中的 tracked index,均为 2477。因此,resolver 可能是这个问题的根源。你还可以看到,有 1 个事务在这个 Region 中留下了 480000 个锁,这可能是问题的原因。
为了获取确切的事务和一些锁的 keys,你可以检查 TiKV 日志并搜索 locks with。输出结果如下:
[2023/07/17 21:16:44.257 +08:00] [INFO] [resolver.rs:213] ["locks with the minimum start_ts in resolver"] [keys="[74800000000000006A5F7280000000000405F6, ... , 74800000000000006A5F72800000000000EFF6, 74800000000000006A5F7280000000000721D9, 74800000000000006A5F72800000000002F691]"] [start_ts=442918429687808001] [region_id=3121]
从 TiKV 日志中,你可以获取事务的 start_ts,即 442918429687808001。为了获取关于语句和事务的更多信息,你可以在 TiDB 日志中搜索这个时间戳。找到结果如下:
[2023/07/17 21:16:18.287 +08:00] [INFO] [2pc.go:685] ["[BIG_TXN]"] [session=2826881778407440457] ["key sample"=74800000000000006a5f728000000000000000] [size=319967171] [keys=10000000] [puts=10000000] [dels=0] [locks=0] [checks=0] [txnStartTS=442918429687808001]
[2023/07/17 21:16:22.703 +08:00] [WARN] [expensivequery.go:145] [expensive_query] [cost_time=60.047172498s] [cop_time=0.004575113s] [process_time=15.356963423s] [wait_time=0.017093811s] [request_count=397] [total_keys=20000398] [process_keys=10000000] [num_cop_tasks=397] [process_avg_time=0.038682527s] [process_p90_time=0.082608262s] [process_max_time=0.116321331s] [process_max_addr=192.168.31.244:20160] [wait_avg_time=0.000043057s] [wait_p90_time=0.00004007s] [wait_max_time=0.00075014s] [wait_max_addr=192.168.31.244:20160] [stats=t:442918428521267201] [conn=2826881778407440457] [user=root] [database=test] [table_ids="[106]"] [txn_start_ts=442918429687808001] [mem_max="2513773983 Bytes (2.34 GB)"] [sql="update t set b = b + 1"]
接着,你可以基本定位导致问题的语句。为了进一步检查,你可以执行 SHOW PROCESSLIST 语句。输出结果如下:
+---------------------+------+---------------------+--------+---------+------+------------+---------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+---------------------+------+---------------------+--------+---------+------+------------+---------------------------+
| 2826881778407440457 | root | 192.168.31.43:58641 | test | Query | 48 | autocommit | update t set b = b + 1 |
| 2826881778407440613 | root | 127.0.0.1:45952 | test | Execute | 0 | autocommit | select * from t where a=? |
| 2826881778407440619 | root | 192.168.31.43:60428 | <null> | Query | 0 | autocommit | show processlist |
+---------------------+------+---------------------+--------+---------+------+------------+---------------------------+
输出结果显示,有程序正在执行一个意外的 UPDATE 语句 (update t set b = b + 1),这导致了一个大事务并阻塞了 Stale Read。
你可以停止执行这个 UPDATE 语句的应用程序来解决这个问题。