Bidirectional Replication
Starting from v6.5.0, TiCDC supports bi-directional replication among two TiDB clusters. Based on this feature, you can create a multi-active TiDB solution using TiCDC.
This section describes how to use bi-directional replication taking two TiDB clusters as an example.
Deploy bi-directional replication
TiCDC only replicates incremental data changes that occur after a specified timestamp to the downstream cluster. Before starting the bi-directional replication, you need to take the following steps:
(Optional) According to your needs, import the data of the two TiDB clusters into each other using the data export tool Dumpling and data import tool TiDB Lightning.
Deploy two TiCDC clusters between the two TiDB clusters. The cluster topology is as follows. The arrows in the diagram indicate the directions of data flow.
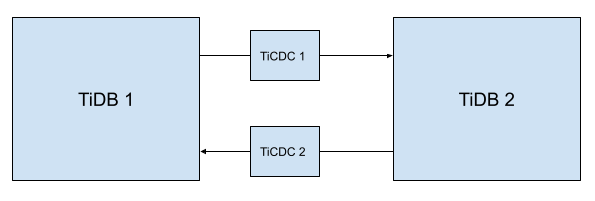
Specify the starting time point of data replication for the upstream and downstream clusters.
Check the time point of the upstream and downstream clusters. In the case of two TiDB clusters, make sure that data in the two clusters are consistent at certain time points. For example, the data of TiDB A at
ts=1and the data of TiDB B atts=2are consistent.When you create the changefeed, set the
--start-tsof the changefeed for the upstream cluster to the correspondingtso. That is, if the upstream cluster is TiDB A, set--start-ts=1; if the upstream cluster is TiDB B, set--start-ts=2.
In the configuration file specified by the
--configparameter, add the following configuration:# Whether to enable the bi-directional replication mode bdr-mode = true(Optional) If you need to track the data source, set a unique data source ID for each cluster using the
tidb_source_idsystem variable.
After the configuration takes effect, the clusters can perform bi-directional replication.
Execute DDL
After the bidirectional replication is enabled, TiCDC does not replicate any DDL statements. You need to execute DDL statements in the upstream and downstream clusters respectively.
Note that some DDL statements might cause table structure changes or data change time sequence problems, which might lead to data inconsistency after the replication. Therefore, after enabling bidirectional replication, only the DDL statements in the following table can be executed without stopping the write operations of the application.
If you need to execute DDL statements that are not in the preceding table, take the following steps:
- Pause the write operations in the tables that need to execute DDL in all clusters.
- After the write operations of the corresponding tables in all clusters have been replicated to other clusters, manually execute all DDL statements in each TiDB cluster.
- After the DDL statements are executed, resume the write operations.
Stop bi-directional replication
After the application has stopped writing data, you can insert a special record into each cluster. By checking the two special records, you can make sure that data in two clusters are consistent.
After the check is completed, you can stop the changefeed to stop bi-directional replication.
Limitations
For the limitations of DDL, see Execute DDL.
Bi-directional replication clusters cannot detect write conflicts, which might cause undefined behaviors. Therefore, you must ensure that there are no write conflicts from the application side.
Bi-directional replication supports more than two clusters, but does not support multiple clusters in cascading mode, that is, a cyclic replication like TiDB A -> TiDB B -> TiDB C -> TiDB A. In such a topology, if one cluster fails, the whole data replication will be affected. Therefore, to enable bi-directional replication among multiple clusters, you need to connect each cluster with every other clusters, for example,
TiDB A <-> TiDB B,TiDB B <-> TiDB C,TiDB C <-> TiDB A.