TableOptimizerHints | This is the hint to control the behavior of TiDB's optimizer. For more information, refer to Optimizer Hints. |
ALL, DISTINCT, DISTINCTROW | The ALL, DISTINCT/DISTINCTROW modifiers specify whether duplicate rows should be returned. ALL (the default) specifies that all matching rows should be returned. |
HIGH_PRIORITY | HIGH_PRIORITY gives the current statement higher priority than other statements. |
SQL_CALC_FOUND_ROWS | TiDB does not support this feature, and will return an error unless tidb_enable_noop_functions=1 is set. |
SQL_CACHE, SQL_NO_CACHE | SQL_CACHE and SQL_NO_CACHE are used to control whether to cache the request results to the BlockCache of TiKV (RocksDB). For a one-time query on a large amount of data, such as the count(*) query, it is recommended to fill in SQL_NO_CACHE to avoid flushing the hot user data in BlockCache. |
STRAIGHT_JOIN | STRAIGHT_JOIN forces the optimizer to do a union query in the order of the tables used in the FROM clause. When the optimizer chooses a join order that is not good, you can use this syntax to speed up the execution of the query. |
select_expr | Each select_expr indicates a column to retrieve. including the column names and expressions. \* represents all the columns. |
FROM table_references | The FROM table_references clause indicates the table (such as select * from t;), or tables (such as select * from t1 join t2;) or even 0 tables (such as select 1+1 from dual; which is equivalent to select 1+1;) from which to retrieve rows. |
WHERE where_condition | The WHERE clause, if given, indicates the condition or conditions that rows must satisfy to be selected. The result contains only the data that meets the condition(s). |
GROUP BY | The GROUP BY statement is used to group the result-set. |
HAVING where_condition | The HAVING clause and the WHERE clause are both used to filter the results. The HAVING clause filters the results of GROUP BY, while the WHERE clause filter the results before aggregation. |
ORDER BY | The ORDER BY clause is used to sort the data in ascending or descending order, based on columns, expressions or items in the select_expr list. |
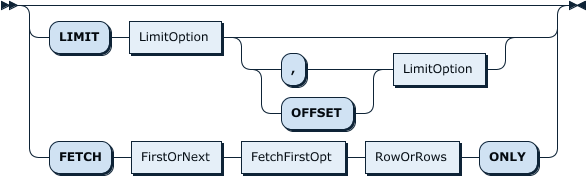
LIMIT | The LIMIT clause can be used to constrain the number of rows. LIMIT takes one or two numeric arguments. With one argument, the argument specifies the maximum number of rows to return, the first row to return is the first row of the table by default; with two arguments, the first argument specifies the offset of the first row to return, and the second specifies the maximum number of rows to return. TiDB also supports the FETCH FIRST/NEXT n ROW/ROWS ONLY syntax, which has the same effect as LIMIT n. You can omit n in this syntax and its effect is the same as LIMIT 1. |
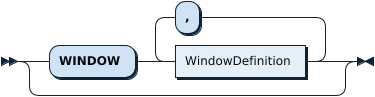
Window window_definition | This is the syntax for window function, which is usually used to do some analytical computation. For more information, refer to Window Function. |
FOR UPDATE | The SELECT FOR UPDATE clause locks all the data in the result sets to detect concurrent updates from other transactions. Data that match the query conditions but do not exist in the result sets are not read-locked, such as the row data written by other transactions after the current transaction is started. TiDB uses the Optimistic Transaction Model. The transaction conflicts are not detected in the statement execution phase. Therefore, the current transaction does not block other transactions from executing UPDATE, DELETE or SELECT FOR UPDATE like other databases such as PostgreSQL. In the committing phase, the rows read by SELECT FOR UPDATE are committed in two phases, which means they can also join the conflict detection. If write conflicts occur, the commit fails for all transactions that include the SELECT FOR UPDATE clause. If no conflict is detected, the commit succeeds. And a new version is generated for the locked rows, so that write conflicts can be detected when other uncommitted transactions are being committed later. When using pessimistic transaction mode, the behavior is basically the same as other databases. Refer to Difference with MySQL InnoDB to see the details. TiDB supports the NOWAIT modifier for FOR UPDATE. See TiDB Pessimistic Transaction Mode for details. |
LOCK IN SHARE MODE | To guarantee compatibility, TiDB parses these three modifiers, but will ignore them. |