Key Visualizer Page
The Key Visualizer page of TiDB Dashboard is used to analyze the usage of TiDB and troubleshoot traffic hotspots. This page visually shows the traffic of the TiDB cluster over a period of time.
Access Key Visualizer page
You can use one of the following two methods to access the Key Visualizer page:
- After logging into TiDB Dashboard, click Key Visualizer on the left navigation menu:
- Visit http://127.0.0.1:2379/dashboard/#/keyviz in your browser. Replace
127.0.0.1:2379with the actual PD instance address and port.
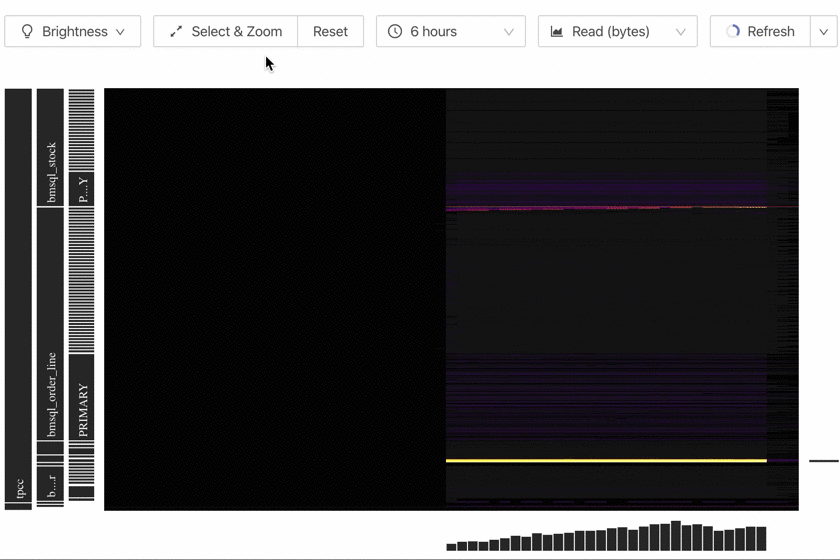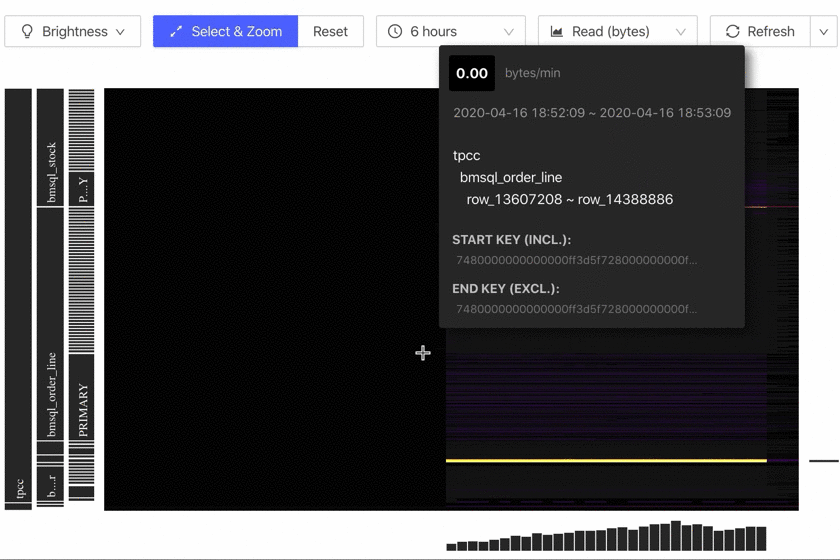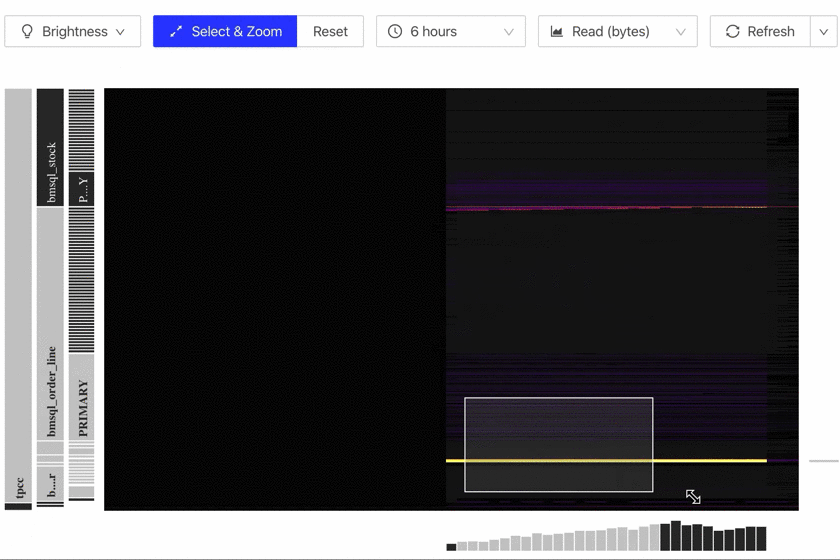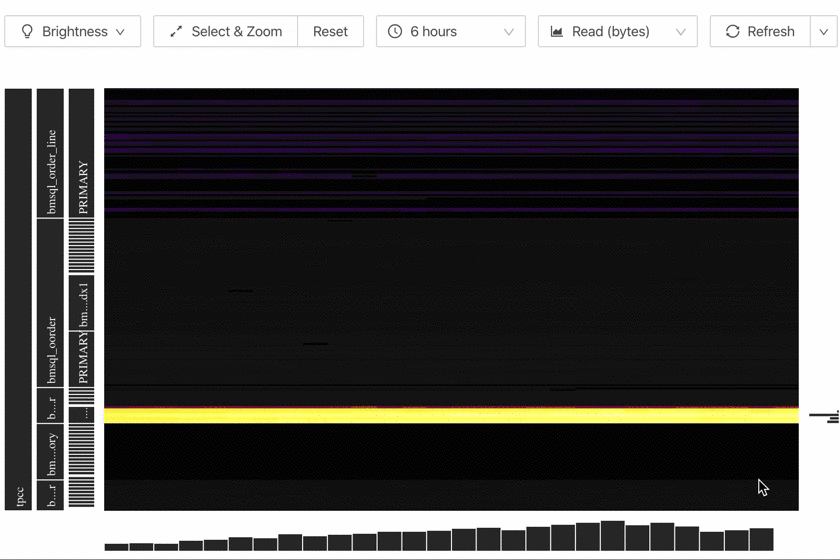
Interface demonstration
The following image is a demonstration of the Key Visualizer page:
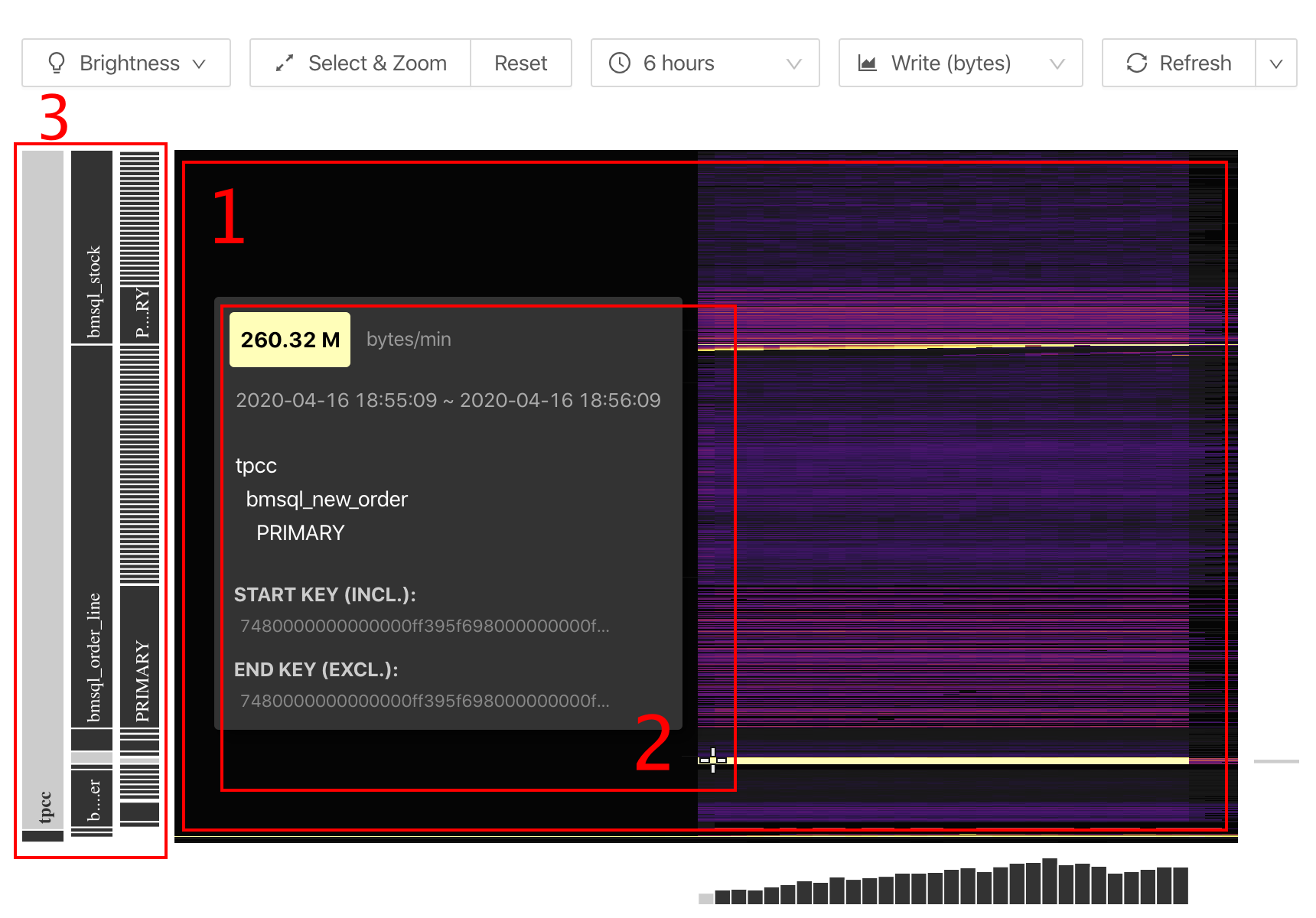
From the interface above, you can see the following objects:
- A large heatmap that shows changes of the overall traffic over time.
- The detailed information of a certain coordinate point.
- Information of tables, indexes, and so on (on the left side of the heatmap).
Basic concepts
This section introduces the basic concepts that relate to Key Visualizer.
Region
In a TiDB cluster, the stored data is distributed among TiKV instances. Logically, TiKV is a huge and orderly key-value map. The whole key-value space is divided into many segments and each segment consists of a series of adjacent keys. Such segment is called a Region.
For detailed introduction of Region, refer to TiDB Internal (I) - Data Storage.
Hotspot
When you use the TiDB database, the hotspot issue is typical, where high traffic is concentrated on a small range of data. Because consecutive data ranges are often processed on the same TiKV instance, the TiKV instance on which the hotspot occurs becomes the performance bottleneck of the whole application. The hotspot issue often occurs in the following scenarios:
- Write adjacent data into a table with the
AUTO_INCREMENTprimary key, which causes a hotspot issue on this table. - Write adjacent time data into the time index of a table, which causes a hotspot issue on the table index.
For more details about hotspot, refer to Highly Concurrent Write Best Practices
Heatmap
The heatmap is the core part of Key Visualizer, which shows the change of a metric over time. The X-axis of the heatmap indicates the time. The Y-axis of the heatmap indicates the consecutive Regions based on key ranges that cover all schemas and tables of the TiDB cluster.
Colder colors in the heatmap indicate lower read and write traffic of Regions in that period of time. Hotter (brighter) colors indicate higher traffic.
Region compression
A TiDB cluster might have up to hundreds of thousands of Regions. It is difficult to display so many Regions on screen. Therefore, on each heatmap, these Regions are compressed into 1,500 consecutive ranges, each range called a Bucket. In the heatmap, because hotter instances need more attention, Key Visualizer tends to compress a large number of Regions with lower traffic into one Bucket, and displays the Region with higher traffic also in one Bucket.
Use Key Visualizer
This section introduces how to use Key Visualizer.
Settings
To use the Key Visualizer page for the first time, you need to manually enable this feature on the Settings page. Follow the page guide and click Open Settings to open the settings page:
After this feature is enabled, you can open the settings page by clicking the Settings icon in the upper right corner:
The settings page is shown as follows:
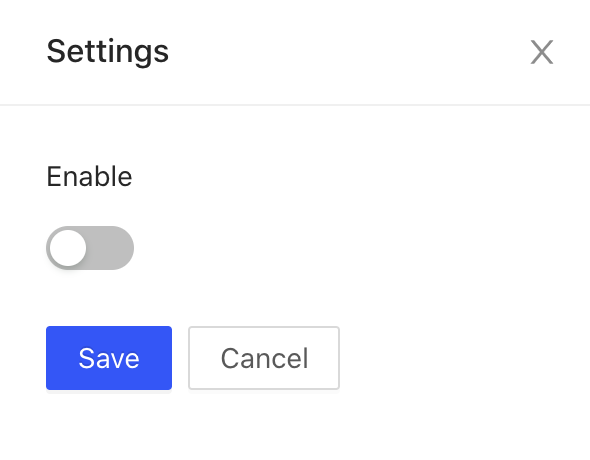
Set whether to start data collection through the switch, and click Save to take effect. After enabling the feature, you can see that the toolbar is available:

After this feature is enabled, data collection is going on at the backend. You can see the heatmap shortly.
Observe a certain period of time or Region range
When you open Key Visualizer, the heatmap of the entire database over the recent six hours is displayed by default. In this heatmap, the closer to the right side (current time), the shorter the time interval corresponding to each column of Buckets. If you want to observe a specific time period or a specific Region range, you can zoom in to get more details. The specific instructions are as follows:
Scroll up or down in the heatmap.
Click and drag one of the following buttons to select the range.
- Click the Select & Zoom button. Then click and drag this button to select the area to zoom in.
- Click the Reset button to reset the Region range to the entire database.
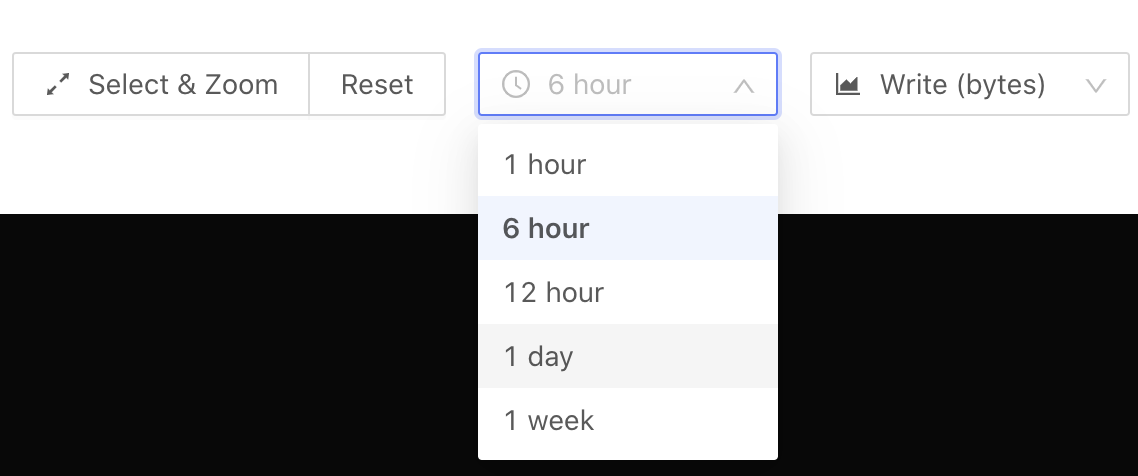
- Click the time selection box (at the position of
6 hourson the interface above) and select the observation time period again.
Adjust brightness
The heatmap uses colors of different brightnesses to indicate the Bucket traffic. Colder colors in the heatmap indicate lower read and write traffic of the Region in that period of time. Hotter (brighter) colors indicate higher traffic. If the color is too cold or too hot, it is difficult to observe in details. In this situation, you can click the Brightness button and then use the slider to adjust the brightness of the page.
Select metrics
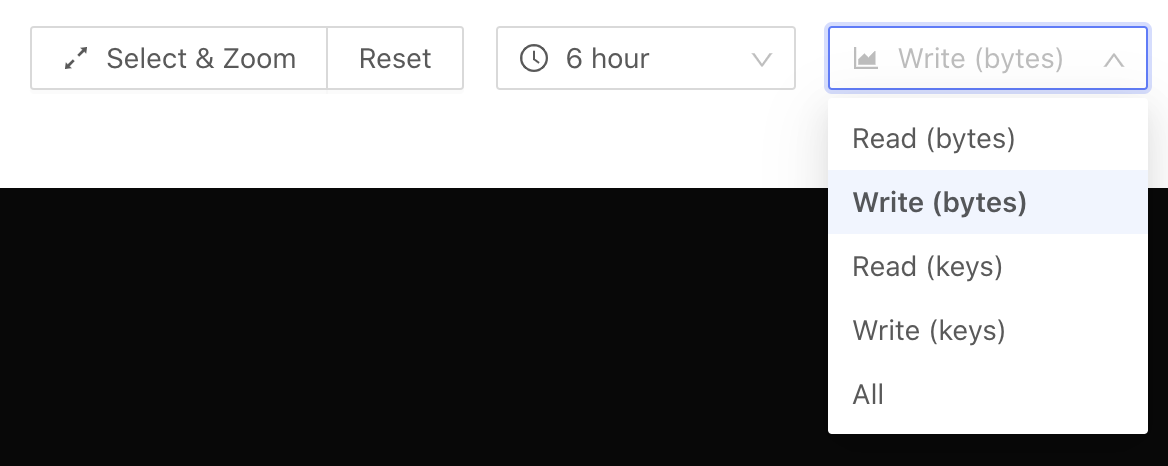
You can view a metric you are interested in by selecting this metric in the metrics selection box (at the Write (bytes) position in the interface above):
Read (bytes): Read traffic.Write (bytes): Write traffic.Read (keys): The number of read rows.Write (keys): The number of written rows.All: The sum of read and write traffic.
Refresh and automatic refresh
To regain a heatmap based on the current time, click the Refresh button. If you need to observe the traffic distribution of the database in real time, click the down arrow on the right side of the Refresh button and select a fixed time interval for the heatmap to automatically refresh at this interval.
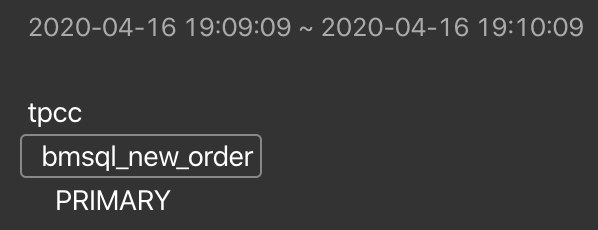
See Bucket details
You can hover your mouse over the Bucket you are interested in to view the detailed information of this Region range. The image below is an example of this information:
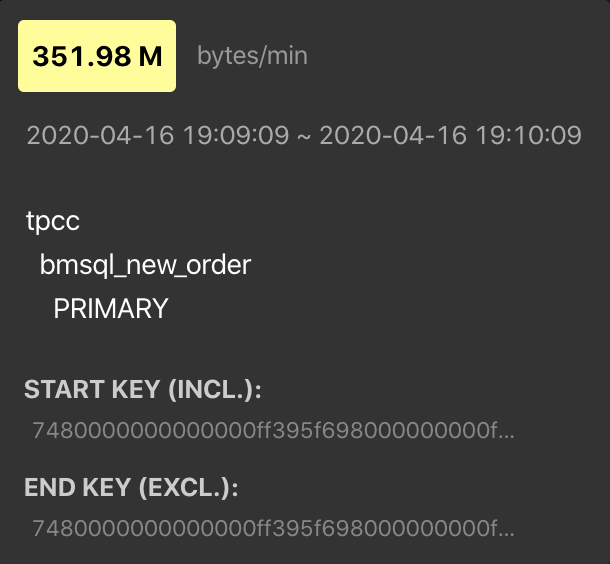
If you want to copy this information, click a Bucket. Then, the page with relevant details is temporarily pinned. Click on the information, and you have copied it to the clipboard.
Common heatmap types
This section shows and interprets four common types of heatmap in Key Visualizer.
Evenly distributed workload

In the heatmap above, bright and dark colors are a fine-grained mix. This indicates that reads or writes are evenly distributed over time and among key ranges. The workload is evenly distributed to all nodes, which is ideal for a distributed database.
Periodically reads and writes

In the heatmap above, there is an alternating brightness and darkness along the X-axis (time) but the brightness is relatively even along the Y-axis (Region). This indicates that the reads and writes change periodically, which might occur in scenarios of periodically scheduled tasks. For example, the big data platform periodically extracts data from TiDB every day. In this kind of scenarios, pay attention to whether the resources are sufficient during peak usage.
Concentrated reads or writes

In the heatmap above, you can see several bright lines. Along the Y-axis, the fringes around the bright lines are dark, which indicates that the Regions corresponding to bright lines have high read and write traffic. You can observe whether the traffic distribution is expected by your application. For example, when all services are associated with the user table, the overall traffic of the user table can be high, so it is reasonable to show bright lines in the heatmap.
In addition, the height of the bright lines (the thickness along the Y-axis) is important. Because TiKV has its own Region-based hotspot balancing mechanism, the more Regions involved in the hotspot, the better it is for balancing traffic across all TiKV instances. The thicker and more bright lines indicate that hotspots are more scattered, and TiKV is better used. The thinner and fewer bright lines indicate that hotspots are more concentrated, and the hotspot issue is more obvious in TiKV, which might requires manual intervention.
Sequential reads or writes

In the heatmap above, you can see a bright line. This means that the data reads or writes are sequential. Typical scenarios of sequential data reads or writes are importing data or scanning tables and indexes. For example, you continuously write data to tables with auto-increment IDs.
Regions in the bright areas are the hotspots of read and write traffic, which often become the performance bottleneck of the entire cluster. In this situation, you might need to readjust the primary key for the application. By doing this, you scatter Regions much as possible to spread the pressure across multiple Regions. You can also schedule application tasks during the low-peak period.
Address hotspot issues
TiDB has some built-in features to mitigate the common hotspot issue. Refer to Highly Concurrent Write Best Practices for details.