在公有云上部署 TiDB 的最佳实践
随着公有云基础设施的普及,越来越多的用户选择在公有云上部署和管理 TiDB。然而,要想在公有云上充分发挥 TiDB 的性能,需要关注多个方面,包括性能优化、成本控制、系统可靠性和可扩展性。
本文介绍在公有云上部署 TiDB 的一系列最佳实践,例如减少 KV RocksDB 中的 compaction I/O 流量、为 Raft Engine 配置专用磁盘、优化跨可用区的流量成本、缓解 Google Cloud 上实时迁移维护事件带来的性能影响,以及对大规模集群中的 PD Server 进行性能调优。遵循这些最佳实践,可以显著提升 TiDB 在公有云上的性能、成本效率、可靠性和可扩展性。
减少 KV RocksDB 中的 compaction I/O 流量
RocksDB 是 TiKV 的存储引擎,负责存储用户数据。出于成本考虑,云上提供的 EBS IO 吞吐量通常比较有限,因此 RocksDB 可能会表现出较高的写放大,导致磁盘吞吐量成为负载的瓶颈。随着时间的推移,待 compaction 的字节总量会不断增加从而触发流量控制,这意味着此时 TiKV 缺乏足够的磁盘带宽来处理前台写入流量。
要缓解由磁盘吞吐量受限引起的瓶颈,你可以通过启用 Titan 来改善性能。如果数据的平均行大小低于 512 字节,Titan 并不适用,此时你可以通过提高所有压缩级别 来改善性能。
启用 Titan
Titan 是基于 RocksDB 的高性能单机 key-value 存储引擎插件。当 value 较大时,Titan 可以减少 RocksDB 中的写放大。
如果数据的平均行大小超过 512 字节,可以通过启用 Titan,设置 min-blob-size 为 "512B" 或 "1KB",以及设置 blob-file-compression 为 "zstd" 来减少压缩 I/O 流量:
[rocksdb.titan]
enabled = true
[rocksdb.defaultcf.titan]
min-blob-size = "1KB"
blob-file-compression = "zstd"
提高所有压缩级别
如果数据的平均行大小低于 512 字节,你可以将默认 Column Family 的所有压缩级别设置为 "zstd" 来提高性能,如下所示:
[rocksdb.defaultcf]
compression-per-level = ["zstd", "zstd", "zstd", "zstd", "zstd", "zstd", "zstd"]
为 Raft Engine 分配专用磁盘
在 TiKV 中,Raft Engine 扮演着类似传统数据库中预写日志(WAL)的关键角色。为了达到最佳性能和稳定性,在公有云上部署 TiDB 时,为 Raft Engine 分配专用磁盘至关重要。以下 iostat 显示了写密集型工作负载下 TiKV 节点的 I/O 特征。
Device r/s rkB/s w/s wkB/s f/s aqu-sz %util
sdb 1649.00 209030.67 1293.33 304644.00 13.33 5.09 48.37
sdd 1033.00 4132.00 1141.33 31685.33 571.00 0.94 100.00
设备 sdb 用于 KV RocksDB,而 sdd 用于存储 Raft Engine 日志。注意,sdd 的 f/s 值明显更高,这表示该设备每秒完成的刷新请求数量更高。在 Raft Engine 中,当 batch 中的写入操作被标记为同步时,batch leader 将在写入后调用 fdatasync(),以确保缓存的数据被写入存储。通过为 Raft Engine 分配专用磁盘,TiKV 可以减少请求的平均队列长度,从而确保写入延迟的最优化和稳定性。
不同的云服务提供商提供了多种性能各异的磁盘类型(例如,IOPS 和 MBPS)。根据你的负载情况,选择合适的云服务提供商、磁盘类型和磁盘大小非常重要。
在公有云上为 Raft Engine 选择合适的磁盘
本节介绍在不同公有云上为 Raft Engine 选择合适磁盘的最佳实践。根据性能需求,推荐使用中端或高端这两种磁盘类型。
中端磁盘
对于不同的公有云,推荐的中端磁盘如下:
AWS:推荐使用 gp3 卷。gp3 卷提供 3000 IOPS 和 125 MB/s 的免费吞吐量,无论 gp3 卷的大小如何选择,通常都足以满足 Raft Engine 的需求。
Google Cloud:推荐使用 pd-ssd。IOPS 和 MBPS 随分配的磁盘大小而不同。为了满足性能需求,建议为 Raft Engine 分配 200 GB 的空间。尽管 Raft Engine 并不需要这么大的空间,但这样可以确保最佳的性能。
Azure:推荐使用 Premium SSD v2。类似于 AWS gp3,Premium SSD v2 提供 3000 IOPS 和 125 MB/s 的免费吞吐量,无论 Premium SSD v2 的大小如何选择,通常都足以满足 Raft Engine 的需求。
高端磁盘
如果你希望 Raft Engine 有更低的延迟,可以考虑使用高端磁盘。对于不同的公有云,推荐的高端磁盘如下:
AWS:推荐使用 io2。磁盘大小和 IOPS 可以根据你的具体需求进行配置。
Google Cloud:推荐使用 pd-extreme。磁盘大小、IOPS 和 MBPS 可以进行配置,但仅在 CPU 核数超过 64 的实例上可用。
Azure:推荐使用 Ultra Disk。磁盘大小、IOPS 和 MBPS 可以根据你的具体需求进行配置。
示例 1:在 AWS 上运行社交网络工作负载
在 AWS 上,一个 20 GB 的 gp3 卷提供 3000 IOPS 和 125 MBPS/s 的吞吐量。
为一个写密集型的社交网络应用分配一个专用的 20 GB gp3 Raft Engine 磁盘后,性能提升如下,而成本仅增加 0.4%:
- QPS(每秒查询数)提高 17.5%
- 插入语句的平均延迟降低 18.7%
- 插入语句的 p99 延迟降低 45.6%
| 指标 | 共享 Raft Engine 磁盘 | 专用 Raft Engine 磁盘 | 差异 (%) |
|---|---|---|---|
| QPS (K/s) | 8.0 | 9.4 | 17.5 |
| 平均插入延迟 (ms) | 11.3 | 9.2 | -18.7 |
| p99 插入延迟 (ms) | 29.4 | 16.0 | -45.6 |
示例 2:在 Azure 上运行 TPC-C/Sysbench 工作负载
在 Azure 上,为 Raft Engine 分配一个专用的 32 GB Ultra Disk 后,性能提升如下:
- Sysbench
oltp_read_write工作负载:QPS 提高 17.8%,平均延迟降低 15.6%。 - TPC-C 工作负载:QPS 提高 27.6%,平均延迟降低 23.1%。
| 指标 | 工作负载 | 共享 Raft Engine 磁盘 | 专用 Raft Engine 磁盘 | 差异 (%) |
|---|---|---|---|---|
| QPS (K/s) | Sysbench oltp_read_write | 60.7 | 71.5 | 17.8 |
| QPS (K/s) | TPC-C | 23.9 | 30.5 | 27.6 |
| 平均延迟 (ms) | Sysbench oltp_read_write | 4.5 | 3.8 | -15.6 |
| 平均延迟 (ms) | TPC-C | 3.9 | 3.0 | -23.1 |
示例 3:在 Google Cloud 上为 TiKV 配置专用的 pd-ssd 磁盘
以下 TiKV 配置示例展示了如何为由 TiDB Operator 部署到 Google Cloud 上的集群额外配置一个 512 GB 的 pd-ssd 磁盘,其中 raft-engine.dir 的配置用于将 Raft Engine 日志存储在该磁盘上。
tikv:
config: |
[raft-engine]
dir = "/var/lib/raft-pv-ssd/raft-engine"
enable = true
enable-log-recycle = true
requests:
storage: 4Ti
storageClassName: pd-ssd
storageVolumes:
- mountPath: /var/lib/raft-pv-ssd
name: raft-pv-ssd
storageSize: 512Gi
降低跨可用区网络流量的成本
在跨多个可用区部署 TiDB 时,跨可用区的数据传输可能会增加部署成本。为了降低这些成本,减少跨可用区的网络流量非常重要。
要减少跨可用区的读取流量,你可以启用 Follower Read 功能,该功能允许 TiDB 优先选择在同一可用区内的副本进行读取。要启用该功能,请将 tidb_replica_read 变量设置为 closest-replicas 或 closest-adaptive。
要减少 TiKV 实例中跨可用区的写入流量,你可以启用 gRPC 压缩功能,该功能在网络传输数据之前会对其进行压缩。以下配置示例展示了如何为 TiKV 启用 gzip gRPC 压缩:
server_configs:
tikv:
server.grpc-compression-type: gzip
要减少 TiFlash MPP 任务中数据交换(data shuffle 过程)所带来的网络流量,建议在同一可用区内部署多个 TiFlash 实例。从 v6.6.0 开始,Exchange 数据压缩功能默认启用,以减少 MPP 数据交换导致的网络流量。
缓解 Google Cloud 上的实时迁移维护事件带来的性能影响
Google Cloud 的实时迁移功能允许虚拟机在主机之间无缝迁移而不会导致停机。然而,这些迁移事件虽不频繁,但可能会显著影响虚拟机的性能,其中包括那些在 TiDB 集群中运行的虚拟机。在这些事件发生期间,受影响的虚拟机可能会出现性能下降,导致 TiDB 集群中的查询处理时间增加。
为了检测 Google Cloud 发起的实时迁移事件并减轻这些事件对性能的影响,TiDB 提供了一个监控脚本(该脚本基于 Google 元数据示例)。你可以将此脚本部署在 TiDB、TiKV 和 PD 节点上,以检测维护事件。当检测到维护事件时,该脚本将自动采取以下适当措施,以尽量减少中断并优化集群行为:
- TiDB:通过下线 TiDB 节点并删除 TiDB pod 来处理维护事件(假设 TiDB 实例的节点池设置为自动扩展且专用于 TiDB)。节点上运行的其他 pod 可能会遇到中断,而被隔离的节点将会被自动扩展程序回收。
- TiKV:在维护期间驱逐受影响的 TiKV 存储上的 Leader。
- PD:如果当前 PD 实例是 PD Leader,则会重新分配 Leader。
需要注意的是,此监控脚本是专门为 TiDB Operator 部署的 TiDB 集群设计的,TiDB Operator 为 Kubernetes 环境中的 TiDB 提供了增强的管理功能。
通过使用该监控脚本,并在维护事件期间采取必要的措施,TiDB 集群可以更好地应对 Google Cloud 上的实时迁移事件,确保对查询处理和响应时间的影响最小以及系统的平稳运行。
为具有高 QPS 的大规模 TiDB 集群优化 PD 性能
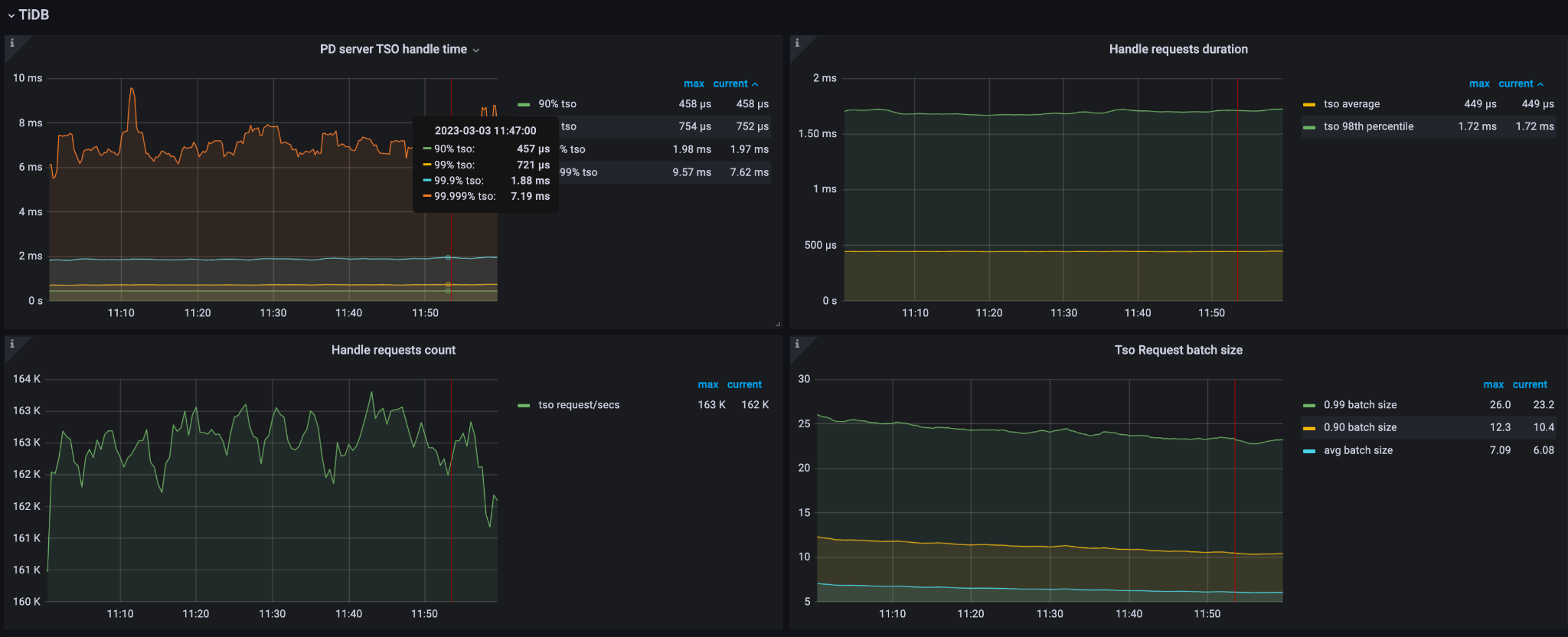
在 TiDB 集群中,一个活跃的 Placement Driver (PD) Server 承担着许多关键任务,例如处理提供 TSO (Timestamp Oracle) 和处理请求。然而,依赖单个活跃 PD Server 可能会限制 TiDB 集群的扩展性。
PD 限制的特征
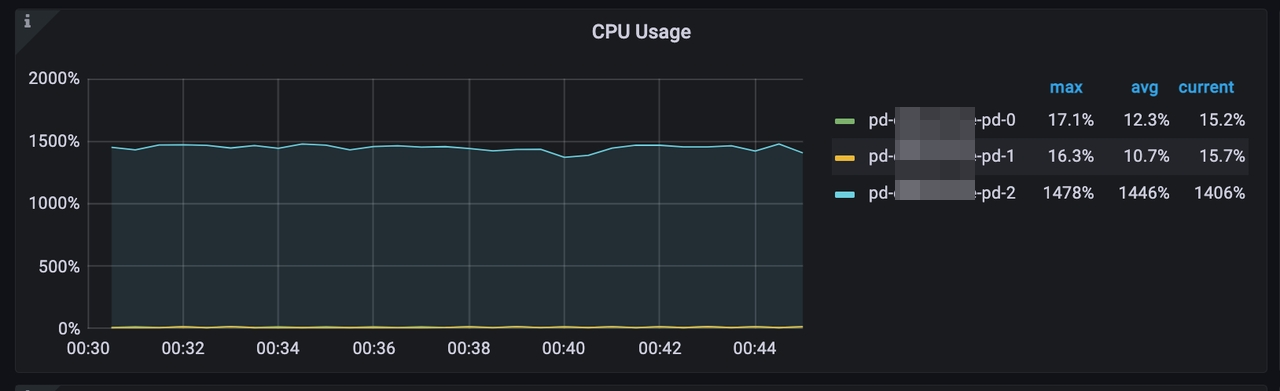
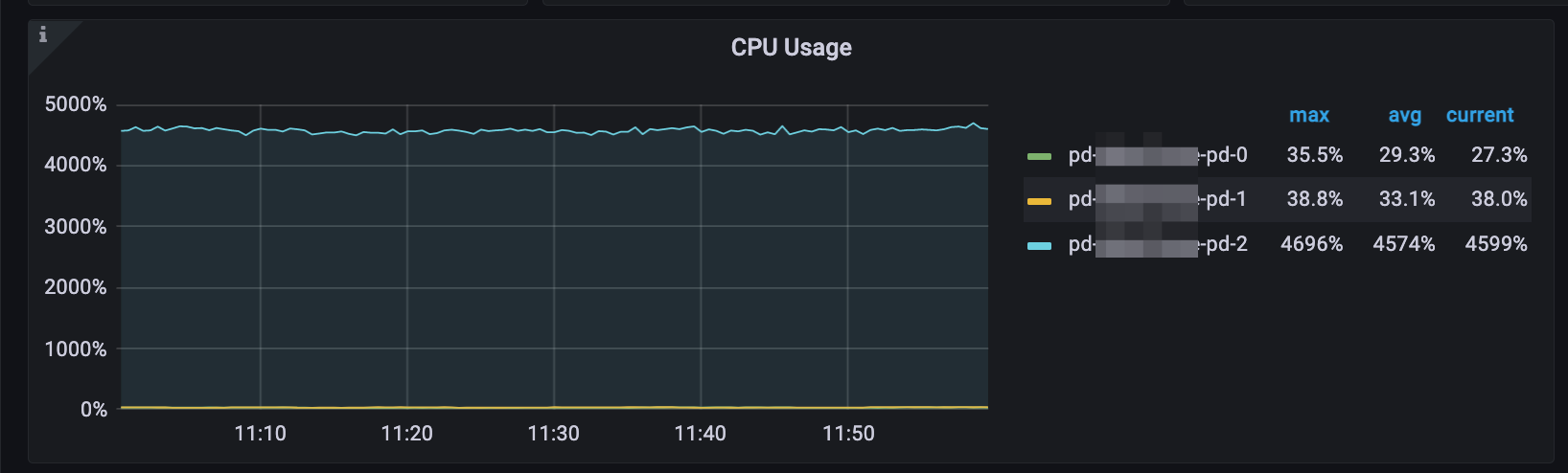
以下图表展示了一个由三个 PD Server 组成的大规模 TiDB 集群的特征,其中每个 PD Server 均配置了 56 核的 CPU。可以看出,当每秒查询数(QPS)超过 100 万次且每秒 TSO 请求数超过 162,000 次时,CPU 利用率达到约 4600%。这一高 CPU 利用率表明 PD Leader 的负载已经相当高且可用的 CPU 资源即将耗尽。
优化 PD 性能
为了解决 PD Server 的高 CPU 利用率问题,可以进行以下调整:
调整 PD 配置
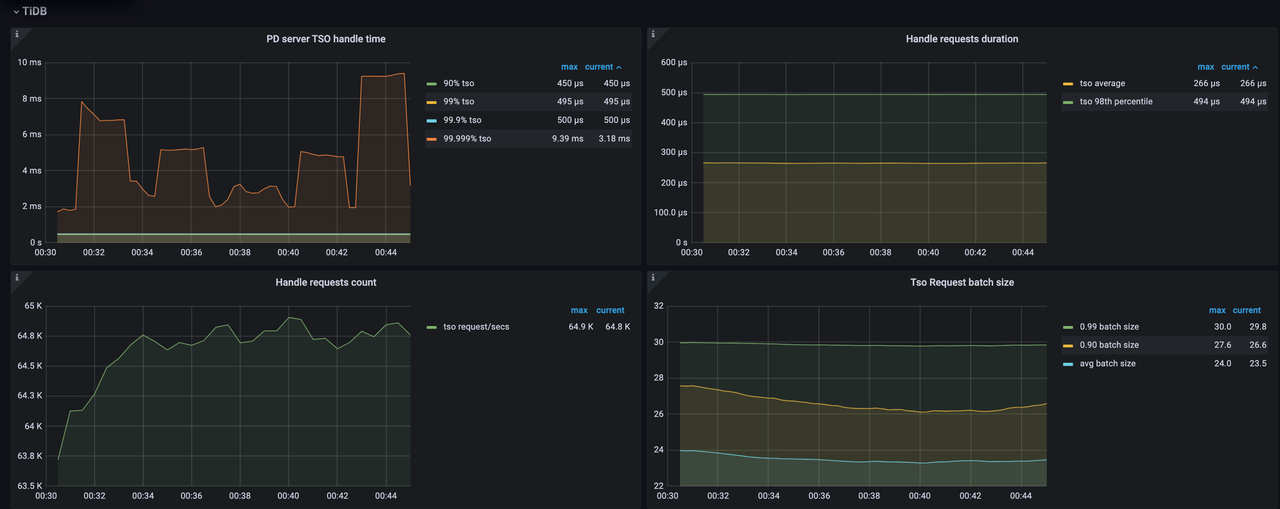
tso-update-physical-interval:此参数控制 PD Server 更新物理 TSO batch 的间隔。通过缩短此间隔,PD Server 可以更频繁地分配 TSO batch,从而减少下一次分配的等待时间。
tso-update-physical-interval = "10ms" # 默认值为 50ms
调整 TiDB 全局变量
除了 PD 配置外,启用 TSO 客户端攒批操作的等待功能可以进一步优化 TSO 客户端的行为。要启用此功能,可以将全局变量 tidb_tso_client_batch_max_wait_time 设置为非零值:
set global tidb_tso_client_batch_max_wait_time = 2; # 默认值为 0
调整 TiKV 配置
为了减少 Region 数量并降低系统的心跳开销,建议将 TiKV 配置中的 Region 大小从 96MB 增加到 256MB。
[coprocessor]
region-split-size = "256MB"
调整后的效果
调整后的效果如下:
- 每秒 TSO 请求数减少到 64,800 次。
- CPU 利用率显著降低,从约 4600% 降低到 1400%。
PD server TSO handle time的 P999 值从 2 ms 降低到 0.5 ms。
以上性能提升表明,这些调整措施成功地降低了 PD Server 的 CPU 利用率,同时保持了稳定的 TSO 处理性能。