统计信息简介
TiDB 使用统计信息来决定索引的选择。变量 tidb_analyze_version 用于控制所收集到的统计信息。目前 TiDB 中支持两种统计信息:tidb_analyze_version = 1 以及 tidb_analyze_version = 2。tidb_analyze_version 在 TiDB v5.2.x 各版本的默认值说明如下:
两种版本中,TiDB 维护的统计信息如下:
Version 2 的统计信息避免了 Version 1 中因为哈希冲突导致的在较大的数据量中可能产生的较大误差,并保持了大多数场景中的估算精度。
本文接下来将简单介绍其中出现的直方图和 Count-Min Sketch 以及 Top-N 这些数据结构,以及详细介绍统计信息的收集和维护。
直方图简介
直方图是一种对数据分布情况进行描述的工具,它会按照数据的值大小进行分桶,并用一些简单的数据来描述每个桶,比如落在桶里的值的个数。在 TiDB 中,会对每个表具体的列构建一个等深直方图,区间查询的估算便是借助该直方图来进行。
等深直方图,就是让落入每个桶里的值数量尽量相等。举个例子,比方说对于给定的集合 {1.6, 1.9, 1.9, 2.0, 2.4, 2.6, 2.7, 2.7, 2.8, 2.9, 3.4, 3.5},并且生成 4 个桶,那么最终的等深直方图就会如下图所示,包含四个桶 [1.6, 1.9],[2.0, 2.6],[2.7, 2.8],[2.9, 3.5],其桶深均为 3。
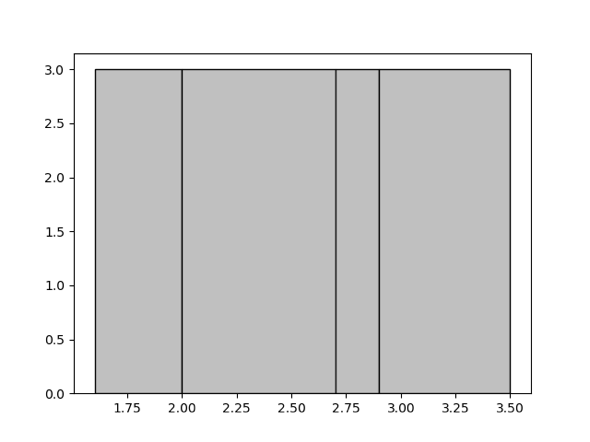
在手动收集统计信息一节中有控制直方图桶数量上限的参数。当桶数量越多,直方图的估算精度就越高,不过也会同时增大统计信息的内存使用,可以视具体情况来做调整。
Count-Min Sketch
Count-Min Sketch 是一种哈希结构,当查询中出现诸如 a = 1 或者 IN 查询(如 a in (1, 2, 3))这样的等值查询时,TiDB 便会使用这个数据结构来进行估算。
由于 Count-Min Sketch 是一个哈希结构,就有出现哈希碰撞的可能。当在 EXPLAIN 语句中发现等值查询的估算偏离实际值较大时,就可以认为是一个比较大的值和一个比较小的值被哈希到了一起。这时有以下两种手段来避免这个情况:
- 修改手动收集统计信息中提到的
WITH NUM TOPN参数。TiDB 会将出现频率前 x 大的数据单独储存,之后的数据再储存到 Count-Min Sketch 中。因此可以调大这个值来避免一个比较大的值和一个比较小的值被哈希到一起。在 TiDB 中,这个参数的默认值是 20,最大可以设置为 1024。 - 修改统计信息的收集-手动收集中提到的
WITH NUM CMSKETCH DEPTH和WITH NUM CMSKETCH WIDTH两个参数,这两个参数会影响哈希的桶数和碰撞概率,可是适当调大来减少冲突概率,同时它会影响统计信息的内存使用,可以视具体情况来调整。在 TiDB 中,DEPTH的默认值是 5,WIDTH的默认值是 2048。
Top-N values
Top-N 即是这个列或者这个索引中,出现次数前 n 的值。TiDB 会记录前 n 个值的具体的值以及出现次数。
统计信息的收集
手动收集
可以通过执行 ANALYZE 语句来收集统计信息。
全量收集
可以通过以下几种语法进行全量收集。
收集 TableNameList 中所有表的统计信息:
ANALYZE TABLE TableNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
WITH NUM BUCKETS用于指定生成直方图的桶数量上限。WITH NUM TOPN用于指定生成 TOPN 数目的上限。WITH NUM CMSKETCH DEPTH用于指定 CM Sketch 的长。WITH NUM CMSKETCH WIDTH用于指定 CM Sketch 的宽。WITH NUM SAMPLES用于指定采样的数目。
收集 TableName 中所有的 IndexNameList 中的索引列的统计信息:
ANALYZE TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
IndexNameList 为空时会收集所有索引列的统计信息。
收集 TableName 中所有的 PartitionNameList 中分区的统计信息:
ANALYZE TABLE TableName PARTITION PartitionNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
收集 TableName 中所有的 PartitionNameList 中分区的索引列统计信息:
ANALYZE TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
增量收集
对于类似时间列这样的单调不减列,在进行全量收集后,可以使用增量收集来单独分析新增的部分,以提高分析的速度。
可以通过以下几种语法进行增量收集。
增量收集 TableName 中所有的 IndexNameList 中的索引列的统计信息:
ANALYZE INCREMENTAL TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
增量收集 TableName 中所有的 PartitionNameList 中分区的索引列统计信息:
ANALYZE INCREMENTAL TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
自动更新
在发生增加,删除以及修改语句时,TiDB 会自动更新表的总行数以及修改的行数。这些信息会定期持久化下来,更新的周期是 20 * stats-lease,stats-lease 的默认值是 3s,如果将其指定为 0,那么将不会自动更新。
和统计信息自动更新相关的三个系统变量如下:
当某个表 tbl 的修改行数与总行数的比值大于 tidb_auto_analyze_ratio,并且当前时间在 tidb_auto_analyze_start_time 和 tidb_auto_analyze_end_time 之间时,TiDB 会在后台执行 ANALYZE TABLE tbl 语句自动更新这个表的统计信息。
在 v5.0 版本之前,执行查询语句时,TiDB 会以 feedback-probability 的概率收集反馈信息,并将其用于更新直方图和 Count-Min Sketch。该功能在当前版本中为实验特性。对于当前版本,该功能默认关闭,不建议在生产环境中开启该功能。
控制 ANALYZE 并发度
执行 ANALYZE 语句的时候,你可以通过一些参数来调整并发度,以控制对系统的影响。
tidb_build_stats_concurrency
目前 ANALYZE 执行的时候会被切分成一个个小的任务,每个任务只负责某一个列或者索引。tidb_build_stats_concurrency 可以控制同时执行的任务的数量,其默认值是 4。
tidb_distsql_scan_concurrency
在执行分析普通列任务的时候,tidb_distsql_scan_concurrency 可以用于控制一次读取的 Region 数量,其默认值是 15。
tidb_index_serial_scan_concurrency
在执行分析索引列任务的时候,tidb_index_serial_scan_concurrency 可以用于控制一次读取的 Region 数量,其默认值是 1。
查看 ANALYZE 状态
在执行 ANALYZE 时,可以通过 SQL 语句来查看当前 ANALYZE 的状态。
语法如下:
SHOW ANALYZE STATUS [ShowLikeOrWhere];
该语句会输出 ANALYZE 的状态,可以通过使用 ShowLikeOrWhere 来筛选需要的信息。
目前 SHOW ANALYZE STATUS 会输出 7 列,具体如下:
统计信息的查看
你可以通过一些语句来查看统计信息的状态。
表的元信息
你可以通过 SHOW STATS_META 来查看表的总行数以及修改的行数等信息。
语法如下:
其中,ShowLikeOrWhereOpt 部分的语法图为:
SHOW STATS_META [ShowLikeOrWhere];
目前 SHOW STATS_META 会输出 6 列,具体如下:
表的健康度信息
通过 SHOW STATS_HEALTHY 可以查看表的统计信息健康度,并粗略估计表上统计信息的准确度。当 modify_count >= row_count 时,健康度为 0;当 modify_count < row_count 时,健康度为 (1 - modify_count/row_count) * 100。
SHOW STATS_HEALTHY 的语法图为:

其中,ShowLikeOrWhereOpt 部分的语法图为:
目前,SHOW STATS_HEALTHY 会输出 4 列,具体如下:
列的元信息
你可以通过 SHOW STATS_HISTOGRAMS 来查看列的不同值数量以及 NULL 数量等信息。
语法如下:
SHOW STATS_HISTOGRAMS [ShowLikeOrWhere];
该语句会输出所有列的不同值数量以及 NULL 数量等信息,你可以通过 ShowLikeOrWhere 来筛选需要的信息。
目前 SHOW STATS_HISTOGRAMS 会输出 10 列,具体如下:
直方图桶的信息
你可以通过 SHOW STATS_BUCKETS 来查看直方图每个桶的信息。
语法如下:
SHOW STATS_BUCKETS [ShowLikeOrWhere];
语法图:
SHOW STATS_BUCKETS:

该语句会输出所有桶的信息,你可以通过 ShowLikeOrWhere 来筛选需要的信息。
目前 SHOW STATS_BUCKETS 会输出 11 列,具体如下:
Top-N 信息
你可以通过 SHOW STATS_TOPN 来查看当前 TiDB 中收集的 Top-N 值的信息。
语法如下:
SHOW STATS_TOPN [ShowLikeOrWhere];
目前 SHOW STATS_TOPN 会输出 7 列,具体如下:
删除统计信息
可以通过执行 DROP STATS 语句来删除统计信息。
语法如下:
DROP STATS TableName;
该语句会删除 TableName 中所有的统计信息。
统计信息的导入导出
导出统计信息
统计信息的导出接口如下。
通过以下接口可以获取数据库 ${db_name} 中的表 ${table_name} 的 json 格式的统计信息:
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}
通过以下接口可以获取数据库 ${db_name} 中的表 ${table_name} 在指定时间上的 json 格式统计信息。指定的时间应在 GC SafePoint 之后。
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyyMMddHHmmss}
通过以下接口可以获取数据库 ${db_name} 中的表 ${table_name} 在指定时间上的 json 格式统计信息。指定的时间应在 GC SafePoint 之后。
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyy-MM-dd HH:mm:ss}
导入统计信息
导入的统计信息一般是通过统计信息导出接口得到的 json 文件。
语法如下:
LOAD STATS 'file_name';
file_name 为要导入的统计信息的文件名。