BR 备份与恢复场景示例
BR 是一款分布式的快速备份和恢复工具。
本文展示了以下几种备份和恢复场景下的 BR 操作过程:
- 将单表数据备份到网络盘(推荐生产环境使用)
- 从网络磁盘恢复备份数据(推荐生产环境使用)
- 将单表数据备份到本地磁盘(推荐测试环境试用)
- 从本地磁盘恢复备份数据(推荐测试环境试用)
以帮助读者达到以下目标:
- 正确使用网络盘或本地盘进行备份或恢复
- 通过相关监控指标了解备份或恢复的状态
- 了解在备份或恢复时如何调优性能
- 处理备份时可能发生的异常
目标读者
你需要对 TiDB 和 TiKV 有一定的了解。
在阅读本文前,请确保你已通读备份与恢复工具 BR 简介,尤其是使用限制和最佳实践这两节。
环境准备
本节介绍 TiDB 的推荐部署方式、BR 使用示例中的集群版本、TiKV 集群硬件信息和集群配置。
你可以根据自己的硬件和配置来预估备份恢复的性能。
部署方式
推荐使用 TiUP 部署 TiDB 集群,再下载 TiDB Toolkit 获取 BR 工具。
集群版本
- TiDB: v5.1.5
- TiKV: v5.1.5
- PD: v5.1.5
- BR: v5.1.5
TiKV 集群硬件信息
- 操作系统:CentOS Linux release 7.6.1810 (Core)
- CPU:16-Core Common KVM processor
- RAM:32GB
- 硬盘:500G SSD * 2
- 网卡:万兆网卡
配置
BR 可以直接将命令下发到 TiKV 集群来执行备份和恢复,不依赖 TiDB server 组件,因此无需对 TiDB server 进行配置。
- TiKV: 默认配置
- PD : 默认配置
使用场景
本节描述以下几种使用场景:
推荐使用网络盘来进行备份和恢复操作,这样可以省去收集备份数据文件的繁琐步骤。尤其在 TiKV 集群规模较大的情况下,使用网络盘可以大幅提升操作效率。
在使用 BR 进行备份或恢复操作前,需要先进行如下准备工作.
备份前的准备工作
BR 工具已支持自适应 GC,会自动将 backupTS(默认是最新的 PD timestamp)注册到 PD 的 safePoint,保证 TiDB 的 GC Safe Point 在备份期间不会向前移动,即可避免手动设置 GC。
关于 br backup 命令的具体使用方法,参见使用备份与恢复工具 BR。
运行 br backup 命令前,请确保以下条件:
- TiDB 集群中没有正在运行中的 DDL。
- 用于创建备份的存储设备有足够的空间。
恢复前的准备工作
使用 BR 进行恢复前的准备工作如下:
运行 br restore 命令前,需要检查新集群,确保集群内没有同名的表。
将单表数据备份到网络盘(推荐生产环境使用)
使用 br backup 命令,将单表数据 --db batchmark --table order_line 备份到指定的网络盘路径 local:///br_data 下。
前置要求
- 备份前的准备工作。
- 配置一台高性能 SSD 硬盘主机为 NFS server 存储数据。其他所有 BR 节点、 TiKV 节点 和 TiFlash 节点为 NFS client,挂载相同的路径(例如
/br_data)到 NFS server 上以访问 NFS server。 - NFS server 和 NFS client 间的数据传输速率至少要达到备份集群的
TiKV 实例数 * 150MB/s。否则网络 I/O 有可能成为性能瓶颈。
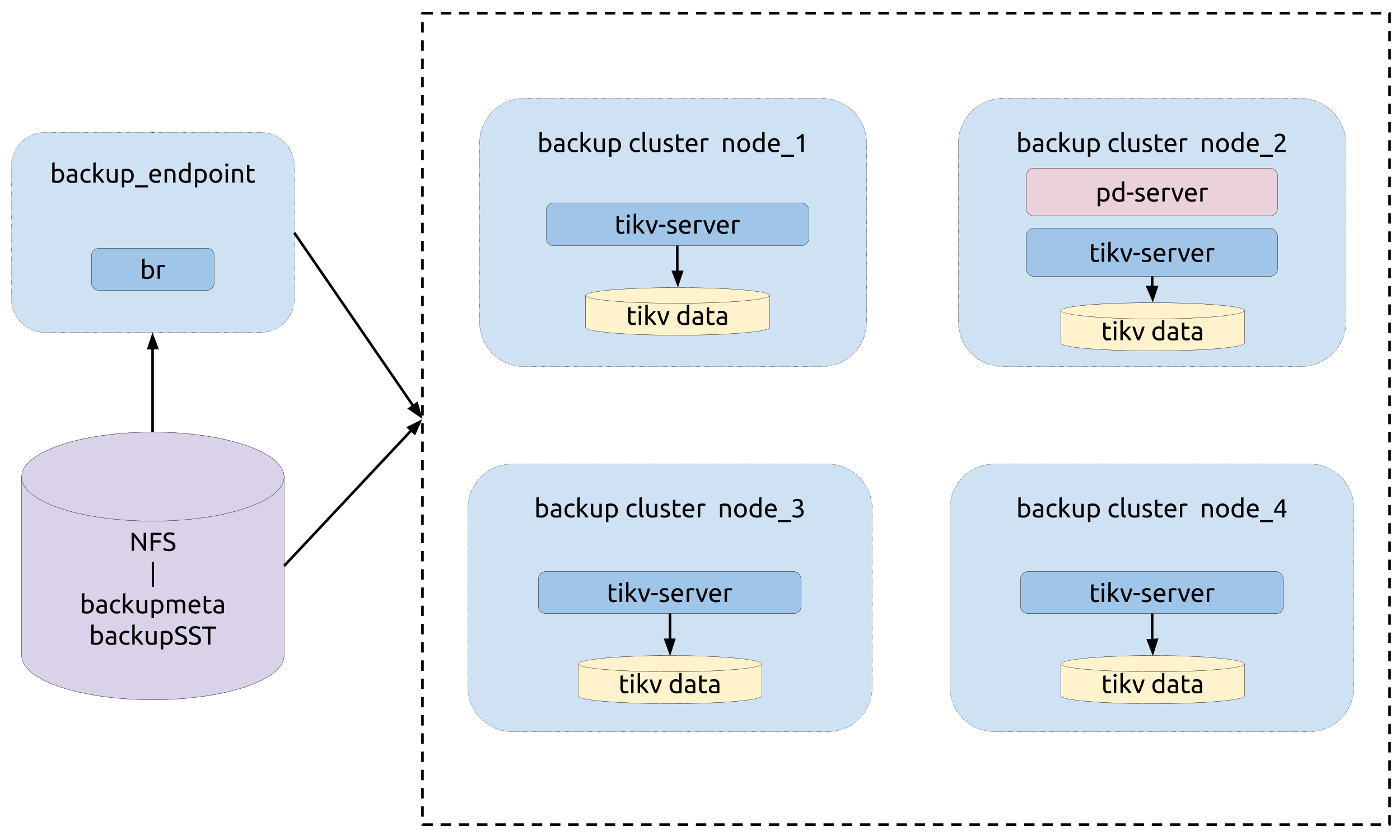
部署拓扑
部署拓扑如下图所示:

运行备份
备份操作前,在 TiDB 中使用 admin checksum table order_line 命令获得备份目标表 --db batchmark --table order_line 的统计信息。统计信息示例如下:
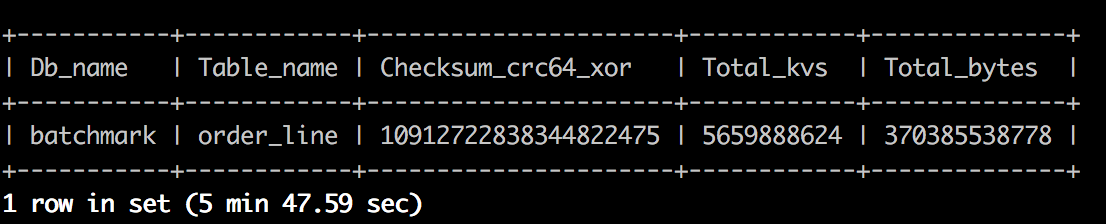
运行 BR 备份命令:
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///br_data \
--pd ${PD_ADDR}:2379 \
--log-file backup-nfs.log
备份过程中的运行指标
在 BR 备份过程中,需关注以下监控面版中的运行指标来了解备份的状态。
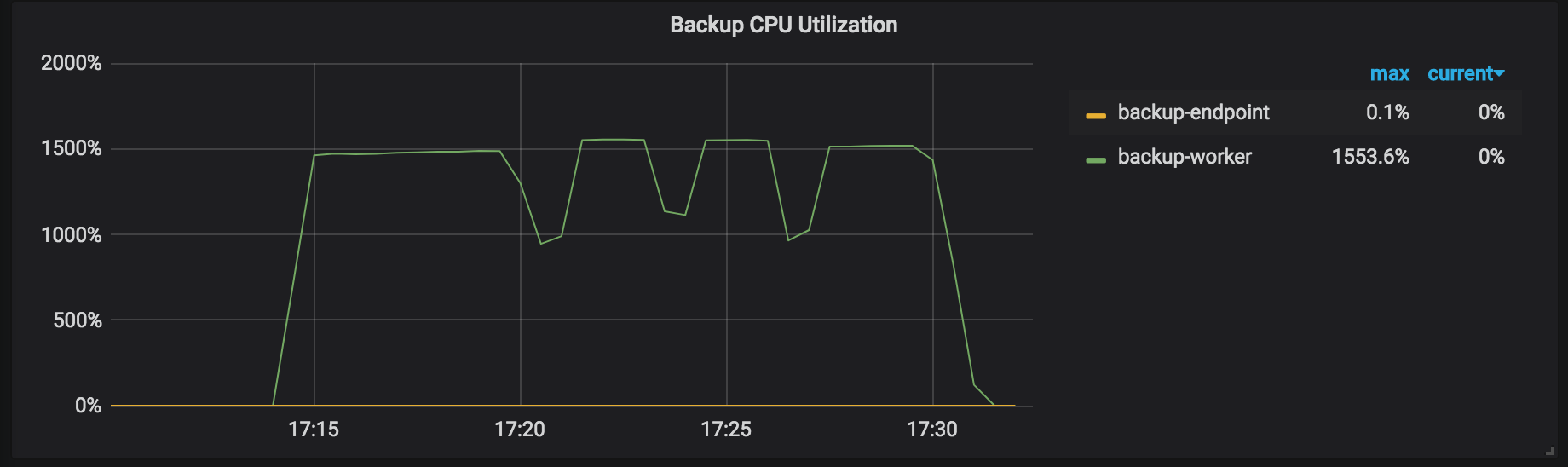
Backup CPU Utilization:参与备份的 TiKV 节点(例如 backup-worker 和 backup-endpoint)的 CPU 使用率。
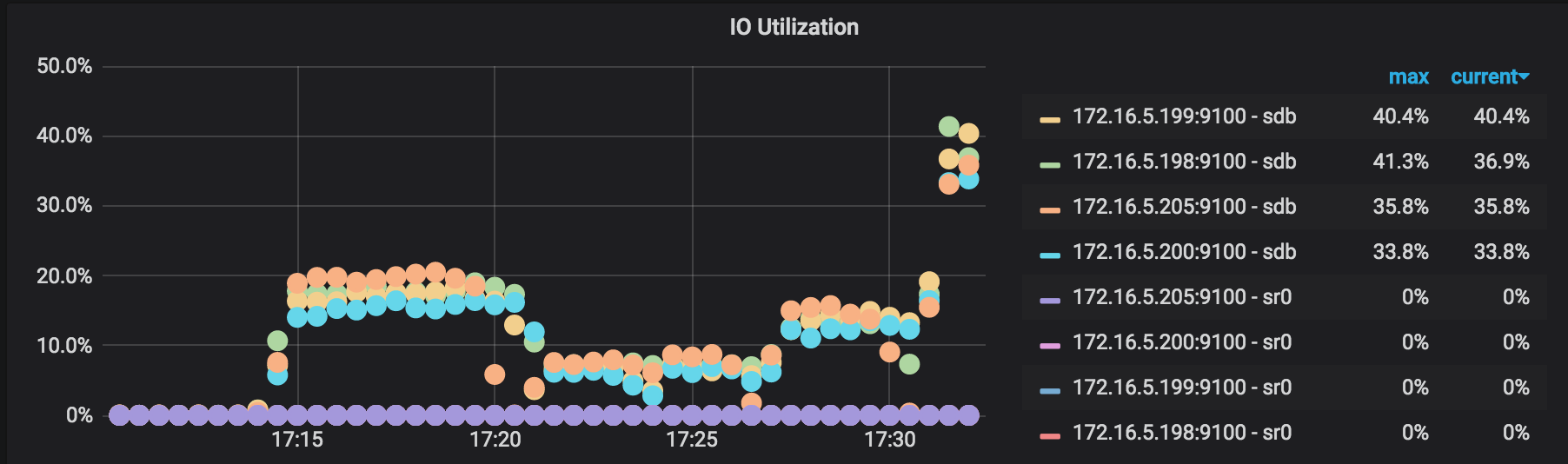
IO Utilization:参与备份的 TiKV 节点的 I/O 使用率。
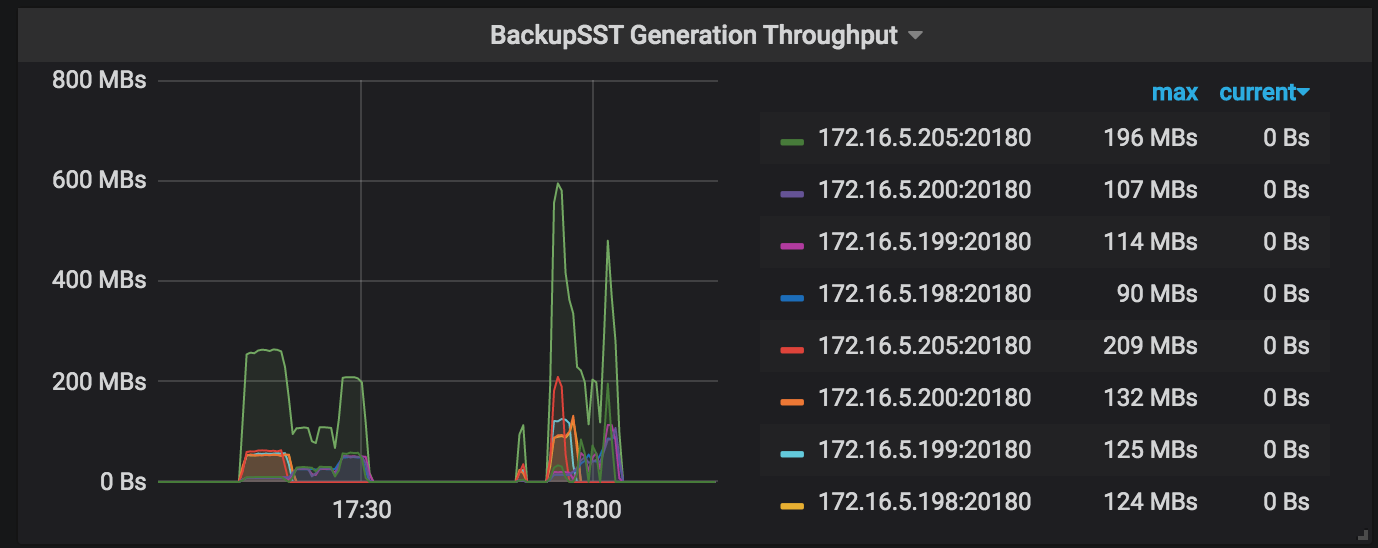
BackupSST Generation Throughput:参与备份的 TiKV 节点生成 backupSST 文件的吞吐。正常时单个 TiKV 节点的吞吐在 150MB/s 左右。

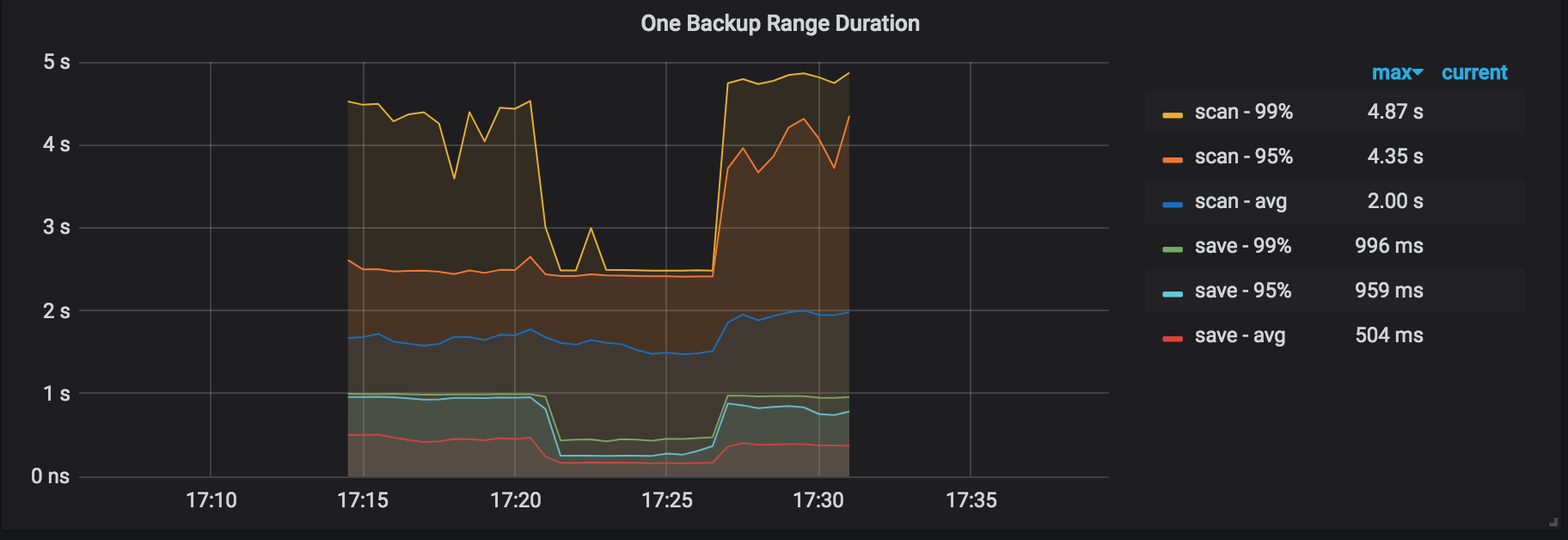
One Backup Range Duration:备份一个 range 的操作耗时,包括扫描耗时 (scan KV) 和保存耗时(保存为 backupSST 文件)。
One Backup Subtask Duration: 一次备份任务会被拆分成多个子任务。该监控项显示子任务的耗时。
Backup Errors:备份过程中的错误。正常时无错误。即使出现少量错误,备份操作也有重试机制,可能会导致备份时间增加,但不会影响备份的正确性。
Checksum Request Duration:对备份集群执行 admin checksum 的耗时统计。
结果解读
BR 会在备份结束时输出备份总结到控制台。
同时使用 BR 前已设置日志的存放路径。从路径下存放的日志中可以获取此次备份的相关统计信息。在日志中搜关键字 "summary",可以看到以下信息:
["Full backup Success summary:
total backup ranges: 2,
total success: 2,
total failed: 0,
total take(Full backup time): 31.802912166s,
total take(real time): 49.799662427s,
total size(MB): 5997.49,
avg speed(MB/s): 188.58,
total kv: 120000000"]
["backup checksum"=17.907153678s]
["backup fast checksum"=349.333µs]
["backup total regions"=43]
[BackupTS=422618409346269185]
[Size=826765915]
以上日志信息中包含以下内容:
- 备份耗时:
total take(Full backup time): 31.802912166s - 程序运行总耗时:
total take(real time): 49.799662427s - 备份数据大小:
total size(MB): 5997.49 - 备份吞吐:
avg speed(MB/s): 188.58 - 备份 KV 对数:
total kv: 120000000 - 校验耗时:
["backup checksum"=17.907153678s] - 计算各表 checksum、KV 和 bytes 信息总和的耗时:
["backup fast checksum"=349.333µs] - 备份 Region 总数:
["backup total regions"=43] - 备份存档经压缩后在磁盘中的实际大小:
[Size=826765915] - 备份存档的快照时间戳:
[BackupTS=422618409346269185]
通过以上数据可以计算得到单个 TiKV 实例的吞吐为:avg speed(MB/s)/tikv_count = 62.86。
性能调优
如果 TiKV 的资源使用没有出现明显的瓶颈(例如备份过程中的运行指标中的 Backup CPU Utilization 最高为 1500% 左右,IO Utilization 普遍低于 30%),可以尝试调大 --concurrency(默认是 4)参数以进行性能调优。该方法不适用于存在许多小表的场景。
示例如下:
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///br_data/ \
--pd ${PD_ADDR}:2379 \
--log-file backup-nfs.log \
--concurrency 16
性能调优后的结果如下所示(保持数据大小不变):
- 备份耗时:
total take(s)从986.43减少到535.53 - 数据大小:
total size(MB): 353227.18 - 备份吞吐:
avg speed(MB/s)从358.09提升到659.59 - 单个 TiKV 实例的吞吐:
avg speed(MB/s)/tikv_count从89提升到164.89
从网络磁盘恢复备份数据(推荐生产环境使用)
使用 br restore 命令,将一份完整的备份数据恢复到一个离线集群。暂不支持恢复到在线集群。
前置要求
部署拓扑
部署拓扑如下图所示:
运行恢复
运行 br restore 命令:
bin/br restore table --db batchmark --table order_line -s local:///br_data --pd 172.16.5.198:2379 --log-file restore-nfs.log
恢复过程中的运行指标
在 BR 恢复过程中,需关注以下监控面版中的运行指标来了解恢复的状态。
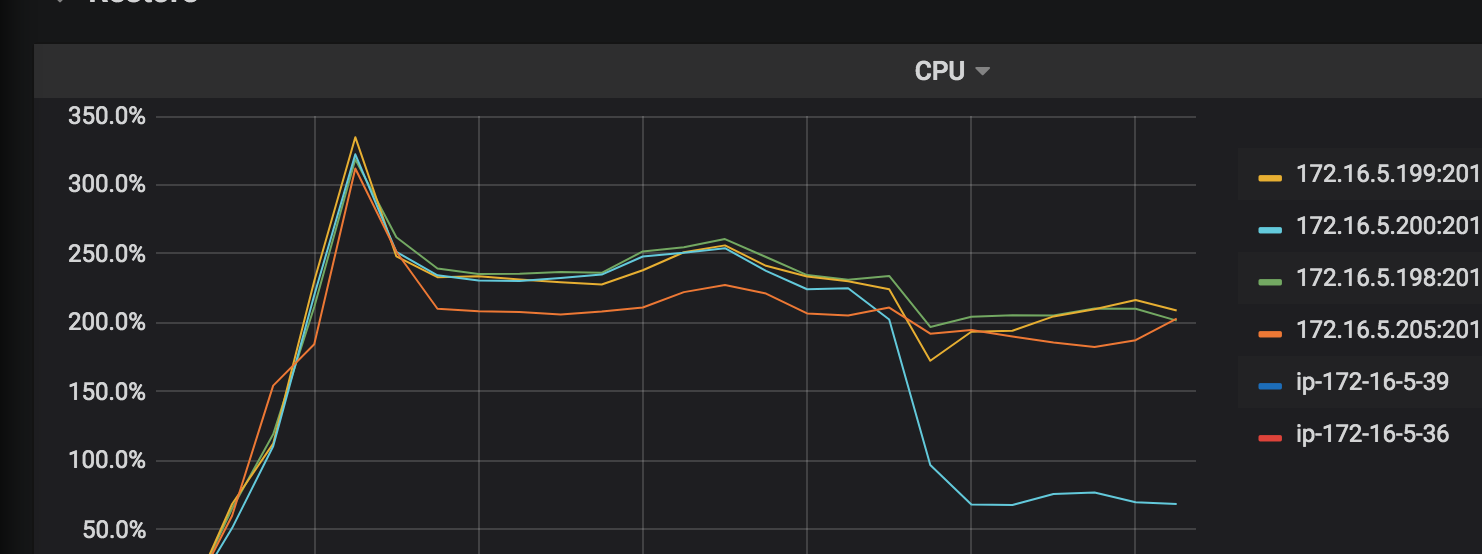
CPU Utilization:参与恢复的 TiKV 节点 CPU 使用率。
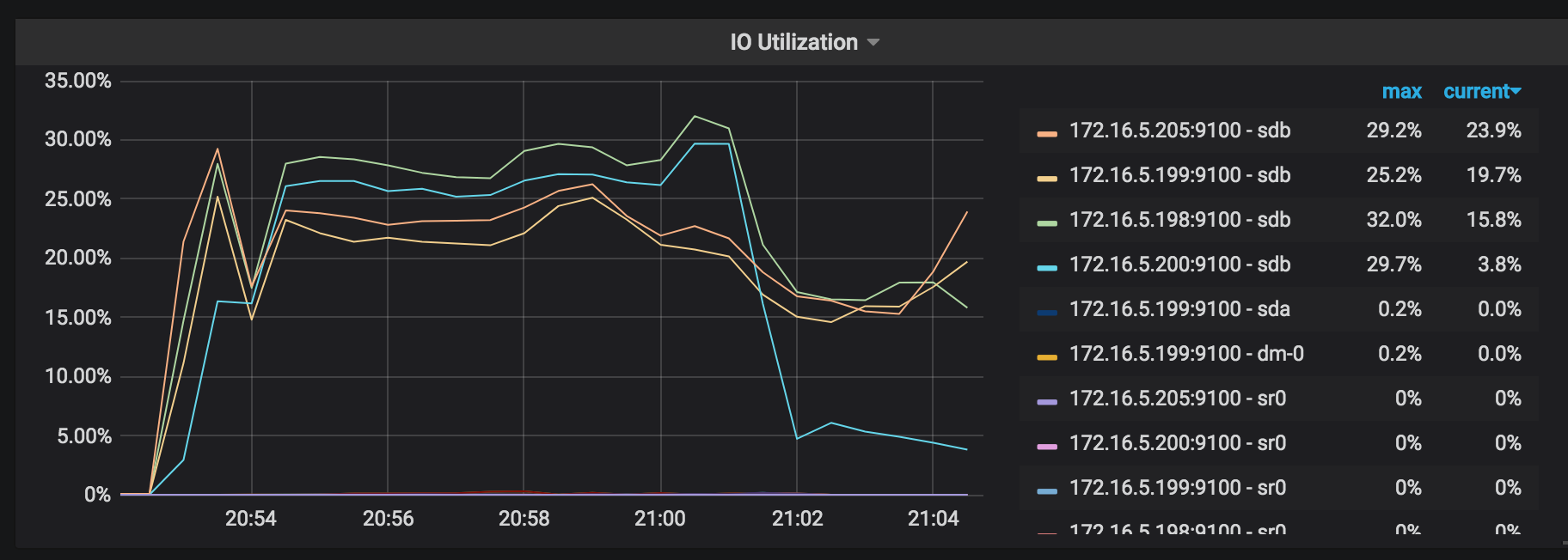
IO Utilization:参与恢复的 TiKV 节点的 I/O 使用率。
Region 分布:Region 分布越均匀,说明恢复资源利用越充分。
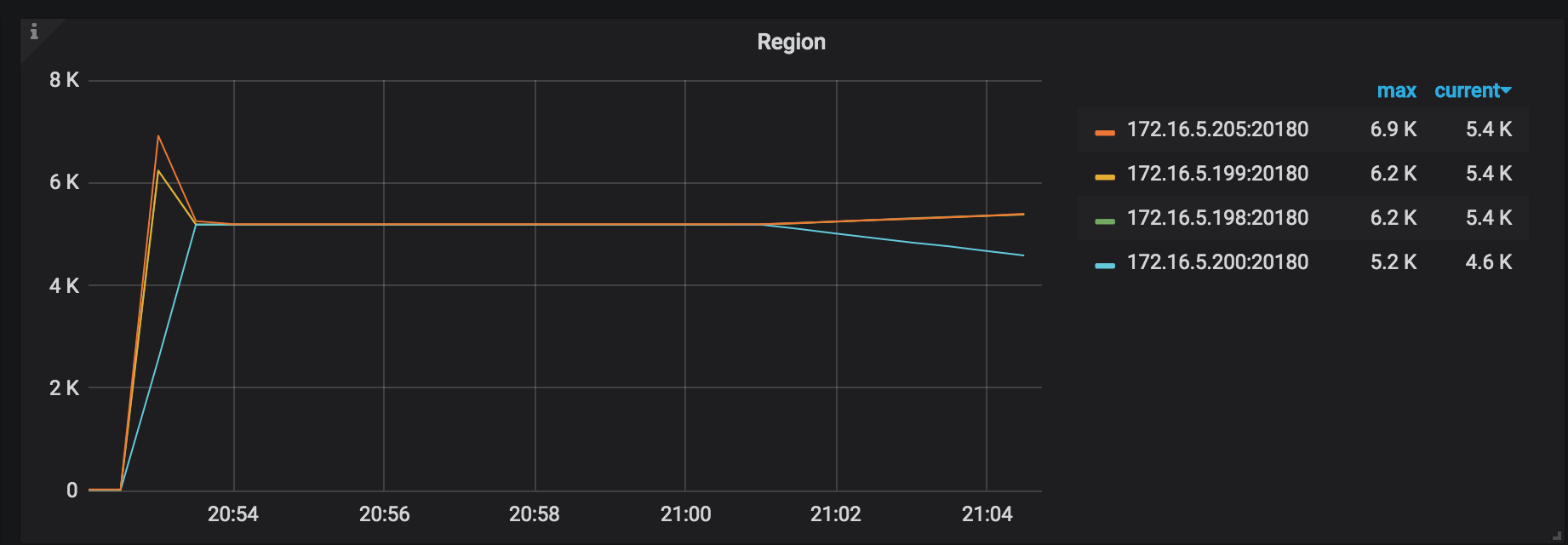
Process SST Duration:处理 SST 文件的延迟。恢复一张表时时,如果 tableID 发生了变化,需要对 tableID 进行 rewrite,否则会进行 rename。通常 rewrite 延迟要高于 rename 的延迟。
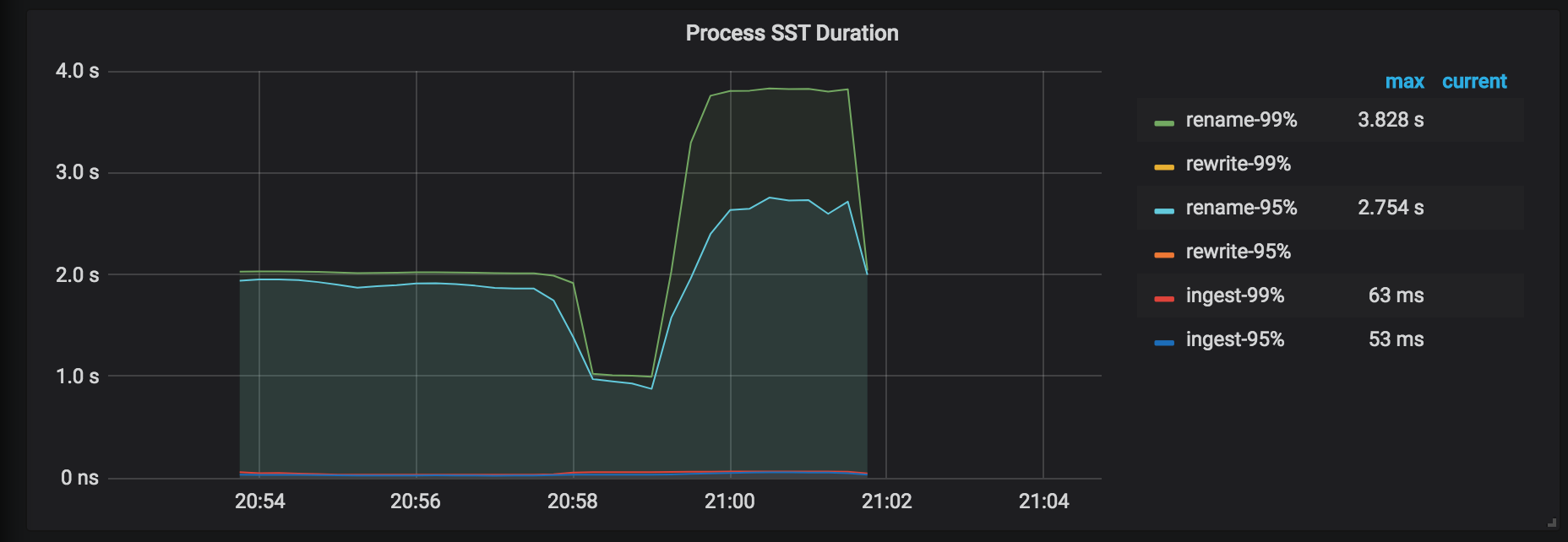
DownLoad SST Throughput:从 External Storage 下载 SST 文件的吞吐。
Restore Errors:恢复过程中的错误。
Checksum Request duration:对恢复集群执行 admin checksum 的耗时统计,会比备份时的 checksum 延迟高。
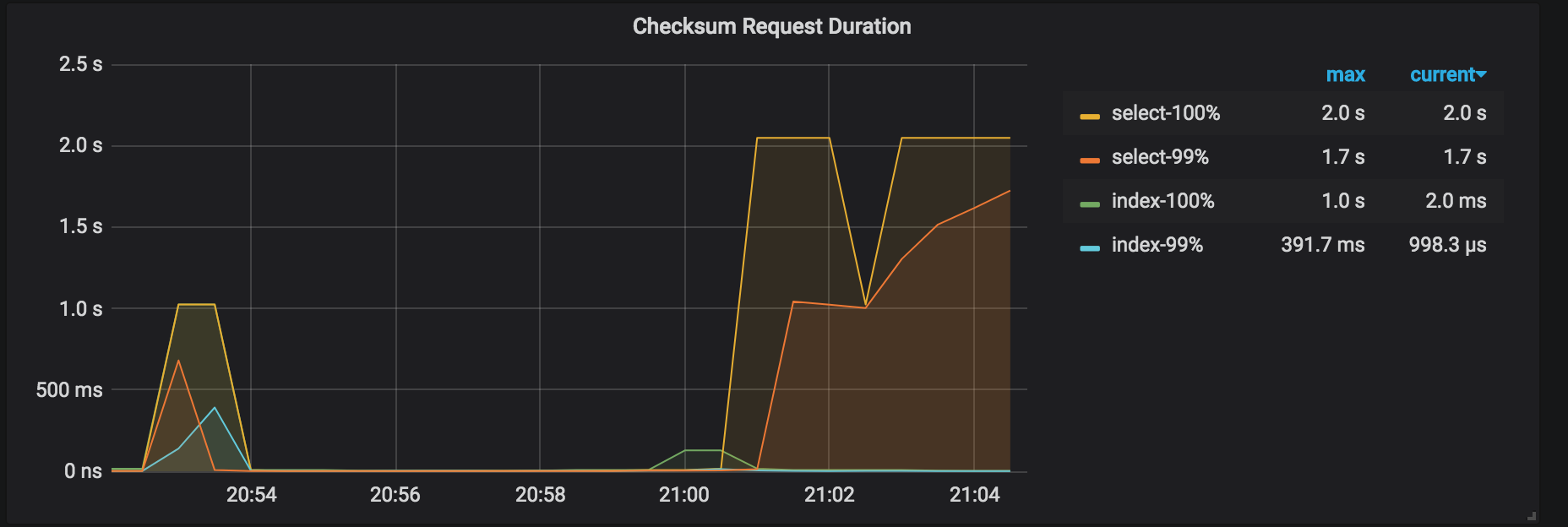
结果解读
使用 BR 前已设置日志的存放路径。从路径下存放的日志中可以获取此次恢复的相关统计信息。在日志中搜关键字 "summary",可以看到以下信息:
["Table Restore summary:
total restore tables: 1,
total success: 1,
total failed: 0,
total take(Full restore time): 17m1.001611365s,
total take(real time): 16m1.371611365s,
total kv: 5659888624,
total size(MB): 353227.18,
avg speed(MB/s): 367.42"]
["restore files"=9263]
["restore ranges"=6888]
["split region"=49.049182743s]
["restore checksum"=6m34.879439498s]
[Size=48693068713]
以上日志信息中包含以下内容:
- 恢复耗时:
total take(Full restore time): 17m1.001611365s - 程序运行总耗时:
total take(real time): 16m1.371611365s - 恢复数据大小:
total size(MB): 353227.18 - 恢复 KV 对数:
total kv: 5659888624 - 恢复吞吐:
avg speed(MB/s): 367.42 Region Split耗时:take=49.049182743s- 校验耗时:
restore checksum=6m34.879439498s - 恢复存档在磁盘中的实际大小:
[Size=48693068713]
根据上表数据可以计算得到:
- 单个 TiKV 吞吐:
avg speed(MB/s)/tikv_count=91.8 - 单个 TiKV 平均恢复速度:
total size(MB)/(split time+restore time)/tikv_count=87.4
性能调优
如果 TiKV 资源使用没有明显的瓶颈,可以尝试调大 --concurrency 参数(默认为 128),示例如下:
bin/br restore table --db batchmark --table order_line -s local:///br_data/ --pd 172.16.5.198:2379 --log-file restore-concurrency.log --concurrency 1024
性能调优后的结果如下表所示(保持数据大小不变):
- 恢复耗时:
total take(s)从961.37减少到443.49 - 恢复吞吐:
avg speed(MB/s)从367.42提升到796.47 - 单个 TiKV 实例的吞吐:
avg speed(MB/s)/tikv_count从91.8提升到199.1 - 单个 TiKV 实例的平均恢复速度:
total size(MB)/(split time+restore time)/tikv_count从87.4提升到162.3
将单表数据备份到本地磁盘(推荐测试环境试用)
使用 br backup 命令,将单表数据 --db batchmark --table order_line 备份到指定的本地磁盘路径 local:///home/tidb/backup_local 下。
前置要求
- 备份前的准备工作。
- 各个 TiKV 节点有单独的磁盘用来存放 backupSST 数据。
backup_endpoint节点有单独的磁盘用来存放备份的backupmeta文件。- TiKV 和
backup_endpoint节点需要有相同的备份目录,例如/home/tidb/backup_local。
部署拓扑
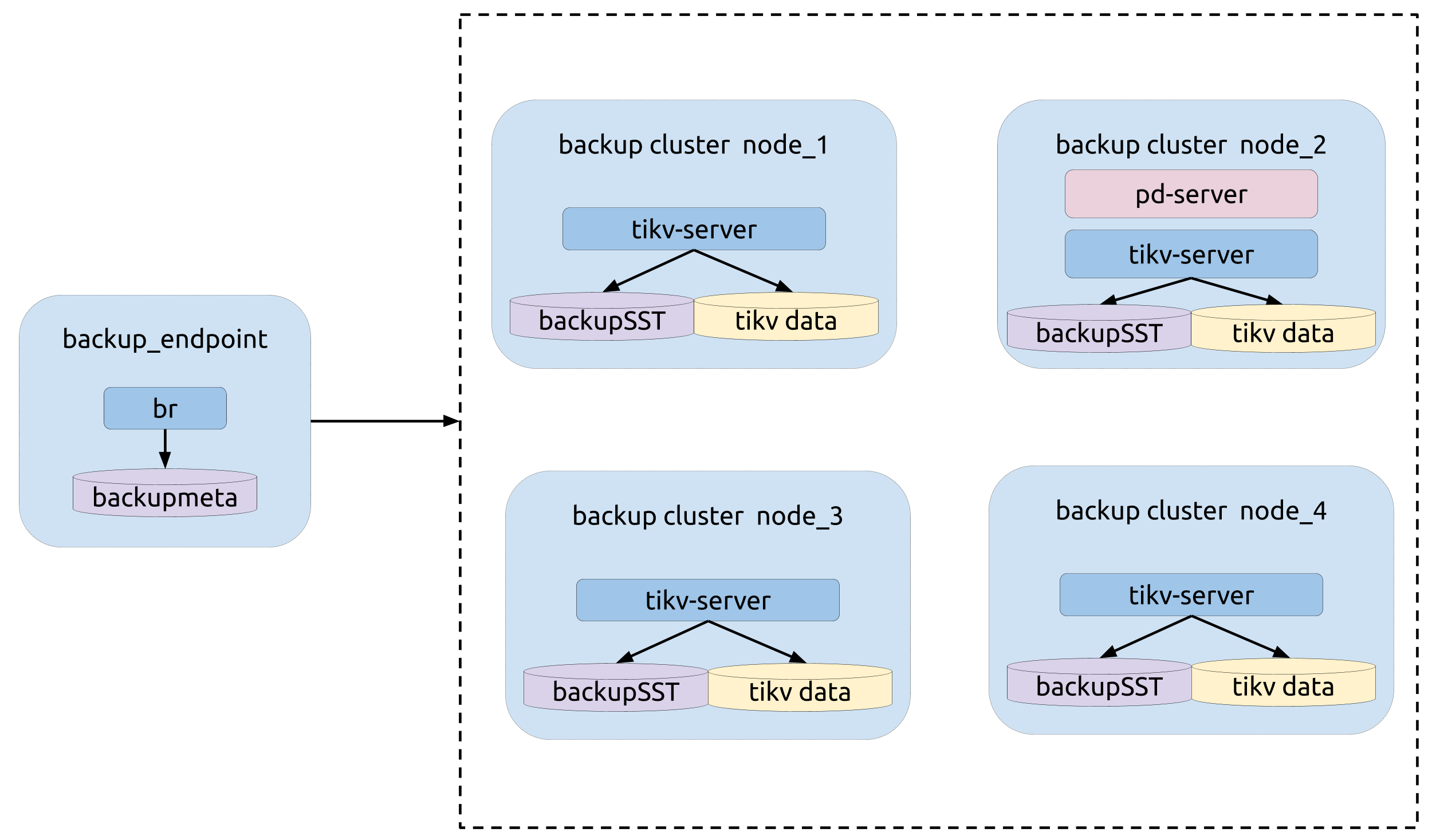
运行备份
备份前在 TiDB 里通过 admin checksum table order_line 获得备份的目标表 --db batchmark --table order_line 的统计信息。统计信息示例如下:
运行 br backup 命令:
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///home/tidb/backup_local/ \
--pd ${PD_ADDR}:2379 \
--log-file backup_local.log
运行备份时,参考备份过程中的运行指标对相关指标进行监控,以了解备份状态。
结果解读
使用 BR 前已设置日志的存放路径。从该路径下存放的日志获取此次备份的相关统计信息。在日志中搜关键字 "summary",可以看到以下信息:
["Table backup summary: total backup ranges: 4, total success: 4, total failed: 0, total take(s): 551.31, total kv: 5659888624, total size(MB): 353227.18, avg speed(MB/s): 640.71"] ["backup total regions"=6795] ["backup checksum"=6m33.962719217s] ["backup fast checksum"=22.995552ms]
以上日志信息中包含以下内容:
- 备份耗时:
total take(s): 551.31 - 数据大小:
total size(MB): 353227.18 - 备份吞吐:
avg speed(MB/s): 640.71 - 校验耗时:
take=6m33.962719217s
根据上表数据可以计算得到单个 TiKV 实例的吞吐:avg speed(MB/s)/tikv_count = 160。
从本地磁盘恢复备份数据(推荐测试环境试用)
使用 br restore 命令,将一份完整的备份数据恢复到一个离线集群。暂不支持恢复到在线集群。
前置要求
- 恢复前的准备工作。
- 集群中没有与备份数据相同的库表。目前 BR 不支持 table route。
- 集群中各个 TiKV 节点有单独的磁盘用来存放要恢复的 backupSST 数据。
restore_endpoint节点有单独的磁盘用来存放要恢复的backupmeta文件。- 集群中 TiKV 和
restore_endpoint节点需要有相同的备份目录,例如/home/tidb/backup_local/。
如果备份数据存放在本地磁盘,那么需要执行以下的步骤:
- 汇总所有 backupSST 文件到一个统一的目录下。
- 将汇总后的 backupSST 文件到复制到集群的所有 TiKV 节点下。
- 将
backupmeta文件复制到到restore endpoint节点下。
部署拓扑
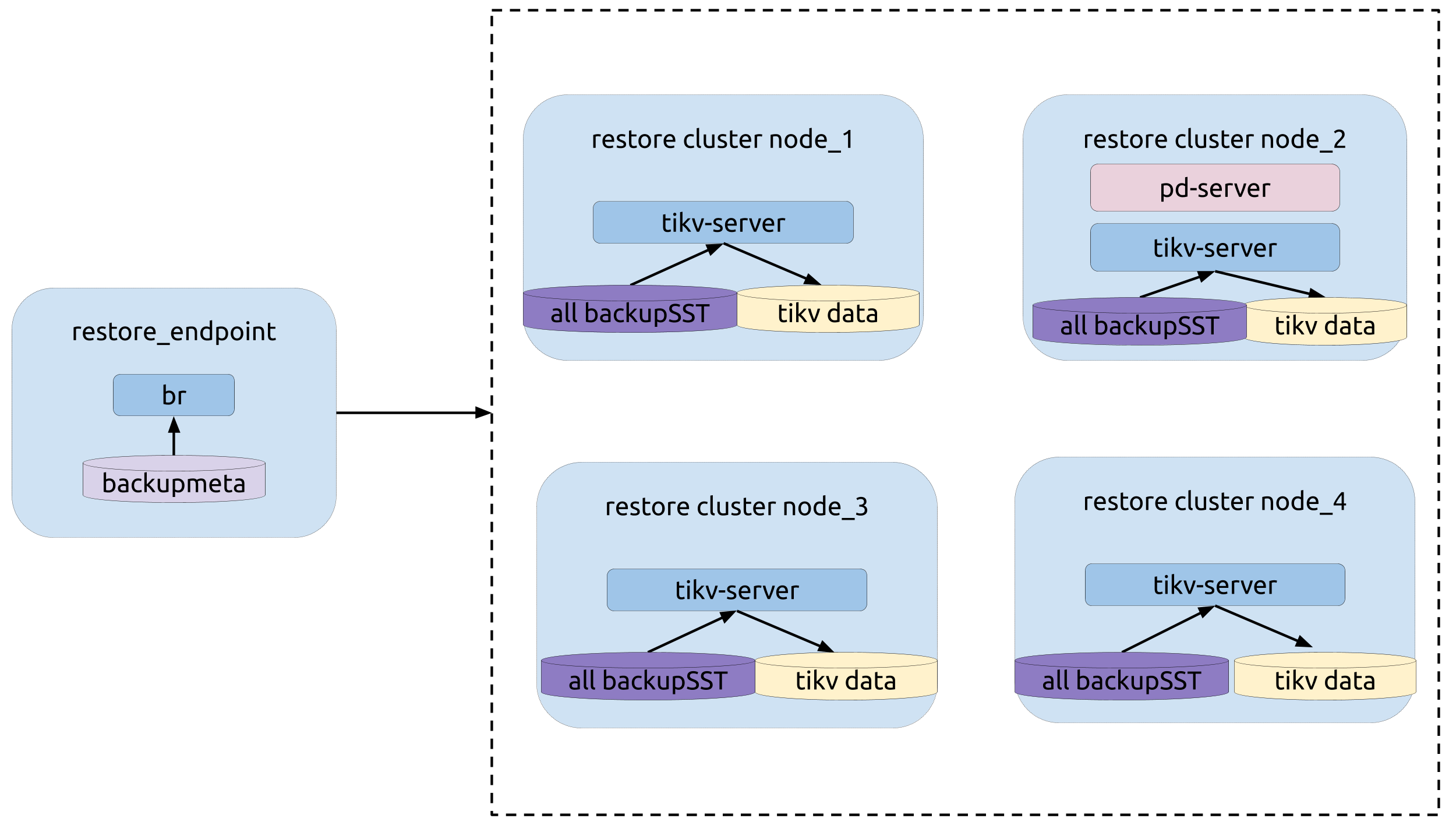
运行恢复
运行 br restore 命令:
bin/br restore table --db batchmark --table order_line -s local:///home/tidb/backup_local/ --pd 172.16.5.198:2379 --log-file restore_local.log
运行恢复时,参考恢复过程中的运行指标对相关指标进行监控,以了解恢复状态。
结果解读
使用 BR 前已设置日志的存放路径。从该日志中可以获取此次恢复的相关统计信息。在日志中搜关键字 "summary",可以看到以下信息:
["Table Restore summary: total restore tables: 1, total success: 1, total failed: 0, total take(s): 908.42, total kv: 5659888624, total size(MB): 353227.18, avg speed(MB/s): 388.84"] ["restore files"=9263] ["restore ranges"=6888] ["split region"=58.7885518s] ["restore checksum"=6m19.349067937s]
以上日志信息中包含以下内容:
- 恢复耗时:
total take(s): 908.42 - 数据大小:
total size(MB): 353227.18 - 恢复吞吐:
avg speed(MB/s): 388.84 Region Split耗时:take=58.7885518s- 校验耗时:
take=6m19.349067937s
根据上表数据可以计算得到:
- 单个 TiKV 实例的吞吐:
avg speed(MB/s)/tikv_count=97.2 - 单个 TiKV 实例的平均恢复速度:
total size(MB)/(split time+restore time)/tikv_count=92.4
备份过程中的异常处理
本节介绍如何处理备份过程中出现的常见错误。
备份日志中出现 key locked Error
日志中的错误消息:log - ["backup occur kv error"][error="{\"KvError\":{\"locked\":
如果在备份过程中遇到 key 被锁住,目前 BR 会尝试清锁。少量报错不会影响备份的正确性。
备份失败
日志中的错误消息:log - Error: msg:"Io(Custom { kind: AlreadyExists, error: \"[5_5359_42_123_default.sst] is already exists in /dir/backup_local/\" })"
若备份失败并出现以上错误消息,采取以下其中一种操作后再重新备份:
- 更换备份数据目录。例如将
/dir/backup-2020-01-01/改为/dir/backup_local/。 - 删除所有 TiKV 和 BR 节点的备份目录。