如何用 Sysbench 测试 TiDB
本次测试使用的是 TiDB 3.0 Beta 和 Sysbench 1.0.14。建议使用 Sysbench 1.0 或之后的更新版本,可在 Sysbench Release 1.0.14 页面下载。
测试环境
参考 TiDB 部署文档部署 TiDB 集群。在 3 台服务器的条件下,建议每台机器部署 1 个 TiDB,1 个 PD,和 1 个 TiKV 实例。关于磁盘,以 32 张表、每张表 10M 行数据为例,建议 TiKV 的数据目录所在的磁盘空间大于 512 GB。对于单个 TiDB 的并发连接数,建议控制在 500 以内,如需增加整个系统的并发压力,可以增加 TiDB 实例,具体增加的 TiDB 个数视测试压力而定。
IDC 机器:
| 类别 | 名称 |
|---|---|
| OS | Linux (CentOS 7.3.1611) |
| CPU | 40 vCPUs, Intel® Xeon® CPU E5-2630 v4 @ 2.20GHz |
| RAM | 128GB |
| DISK | Intel Optane SSD P4800X 375G * 1 |
| NIC | 10Gb Ethernet |
测试方案
TiDB 版本信息
| 组件 | GitHash |
|---|---|
| TiDB | 7a240818d19ae96e4165af9ea35df92466f59ce6 |
| TiKV | e26ceadcdfe94fb6ff83b5abb614ea3115394bcd |
| PD | 5e81548c3c1a1adab056d977e7767307a39ecb70 |
集群拓扑
| 机器 IP | 部署实例 |
|---|---|
| 172.16.30.31 | 3*sysbench |
| 172.16.30.33 | 1*tidb 1*pd 1*tikv |
| 172.16.30.34 | 1*tidb 1*pd 1*tikv |
| 172.16.30.35 | 1*tidb 1*pd 1*tikv |
TiDB 配置
升高日志级别,可以减少打印日志数量,对 TiDB 的性能有积极影响。开启 TiDB 配置中的 prepared plan cache,以减少优化执行计划的开销。具体在 TiDB 配置文件中加入:
[log]
level = "error"
[prepared-plan-cache]
enabled = true
TiKV 配置
升高 TiKV 的日志级别同样有利于提高性能表现。
由于 TiKV 是以集群形式部署的,在 Raft 算法的作用下,能保证大多数节点已经写入数据。因此,除了对数据安全极端敏感的场景之外,raftstore 中的 sync-log 选项可以关闭。
TiKV 集群存在两个 Column Family(Default CF 和 Write CF),主要用于存储不同类型的数据。对于 Sysbench 测试,导入数据的 Column Family 在 TiDB 集群中的比例是固定的。这个比例是:
Default CF : Write CF = 4 : 1
在 TiKV 中需要根据机器内存大小配置 RocksDB 的 block cache,以充分利用内存。以 40 GB 内存的虚拟机部署一个 TiKV 为例,其 block cache 建议配置如下:
log-level = "error"
[raftstore]
sync-log = false
[rocksdb.defaultcf]
block-cache-size = "24GB"
[rocksdb.writecf]
block-cache-size = "6GB"
对于 3.0 及以后的版本,还可以使用共享 block cache 的方式进行设置:
log-level = "error"
[raftstore]
sync-log = false
[storage.block-cache]
capacity = "30GB"
更详细的 TiKV 参数调优请参考 TiKV 性能参数调优。
测试过程
Sysbench 配置
以下为 Sysbench 配置文件样例:
mysql-host={TIDB_HOST}
mysql-port=4000
mysql-user=root
mysql-password=password
mysql-db=sbtest
time=600
threads={8, 16, 32, 64, 128, 256}
report-interval=10
db-driver=mysql
可根据实际需求调整其参数,其中 TIDB_HOST 为 TiDB server 的 IP 地址(配置文件中不能写多个地址),threads 为测试中的并发连接数,可在 “8, 16, 32, 64, 128, 256” 中调整,导入数据时,建议设置 threads = 8 或者 16。调整后,将该文件保存为名为 config 的文件。
配置文件参考示例如下:
mysql-host=172.16.30.33
mysql-port=4000
mysql-user=root
mysql-password=password
mysql-db=sbtest
time=600
threads=16
report-interval=10
db-driver=mysql
数据导入
在数据导入前,需要对 TiDB 进行简单设置。在 MySQL 客户端中执行如下命令:
set global tidb_disable_txn_auto_retry = off;
然后退出客户端。TiDB 使用乐观事务模型,当发现并发冲突时,会回滚事务。将 tidb_disable_txn_auto_retry 设置为 off 会开启事务冲突后的自动重试机制,可以尽可能避免事务冲突报错导致 Sysbench 程序退出的问题。
重新启动 MySQL 客户端执行以下 SQL 语句,创建数据库 sbtest:
create database sbtest;
调整 Sysbench 脚本创建索引的顺序。Sysbench 按照“建表->插入数据->创建索引”的顺序导入数据。对于 TiDB 而言,该方式会花费更多的导入时间。你可以通过调整顺序来加速数据的导入。
假设使用的 Sysbench 版本为 1.0.14,可以通过以下两种方式来修改:
- 直接下载为 TiDB 修改好的 oltp_common.lua 文件,覆盖
/usr/share/sysbench/oltp_common.lua文件。 - 将
/usr/share/sysbench/oltp_common.lua的第 235 行到第 240 行移动到第 198 行以后。
命令行输入以下命令,开始导入数据,config 文件为上一步中配置的文件:
sysbench --config-file=config oltp_point_select --tables=32 --table-size=10000000 prepare
数据预热与统计信息收集
数据预热可将磁盘中的数据载入内存的 block cache 中,预热后的数据对系统整体的性能有较大的改善,建议在每次重启集群后进行一次数据预热。
Sysbench 1.0.14 没有提供数据预热的功能,因此需要手动进行数据预热。如果使用更新的 Sysbench 版本,可以使用自带的预热功能。
以 Sysbench 中某张表 sbtest7 为例,执行如下 SQL 语句 进行数据预热:
SELECT COUNT(pad) FROM sbtest7 USE INDEX (k_7);
统计信息收集有助于优化器选择更为准确的执行计划,可以通过 analyze 命令来收集表 sbtest 的统计信息,每个表都需要统计。
ANALYZE TABLE sbtest7;
Point select 测试命令
sysbench --config-file=config oltp_point_select --tables=32 --table-size=10000000 run
Update index 测试命令
sysbench --config-file=config oltp_update_index --tables=32 --table-size=10000000 run
Read-only 测试命令
sysbench --config-file=config oltp_read_only --tables=32 --table-size=10000000 run
测试结果
测试了数据 32 表,每表有 10M 数据。
对每个 tidb-server 进行了 Sysbench 测试,将结果相加,得出最终结果:
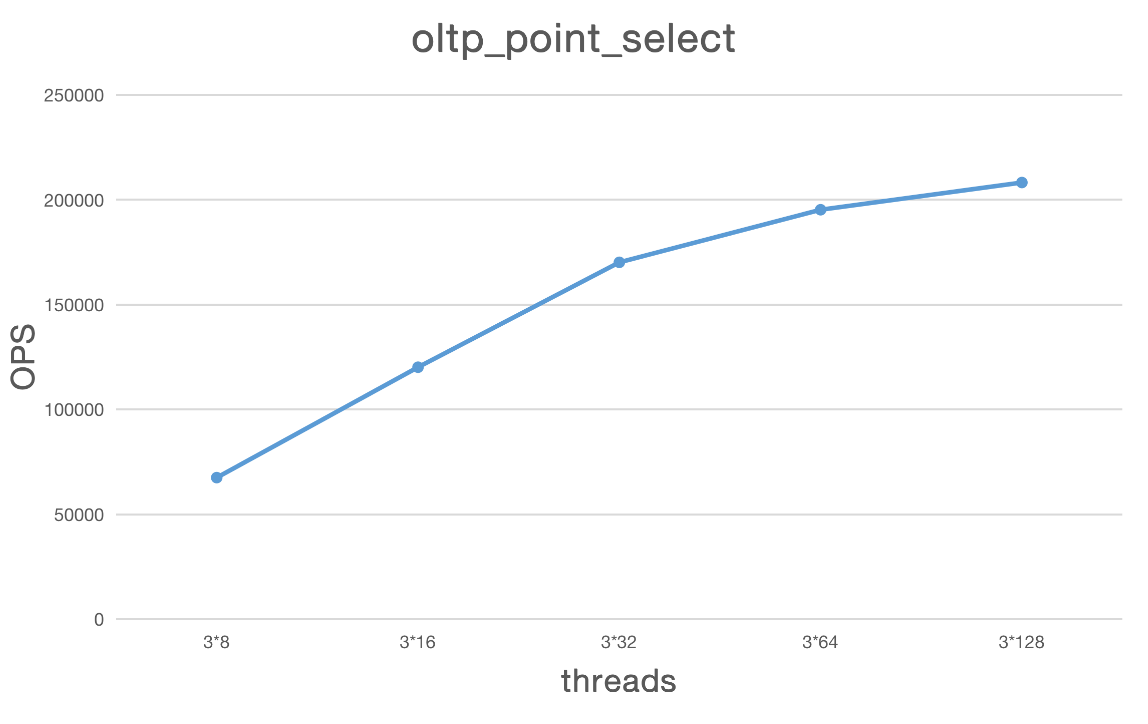
oltp_point_select
| 类型 | Thread | TPS | QPS | avg.latency(ms) | .95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| point_select | 3*8 | 67502.55 | 67502.55 | 0.36 | 0.42 | 141.92 |
| point_select | 3*16 | 120141.84 | 120141.84 | 0.40 | 0.52 | 20.99 |
| point_select | 3*32 | 170142.92 | 170142.92 | 0.58 | 0.99 | 28.08 |
| point_select | 3*64 | 195218.54 | 195218.54 | 0.98 | 2.14 | 21.82 |
| point_select | 3*128 | 208189.53 | 208189.53 | 1.84 | 4.33 | 31.02 |
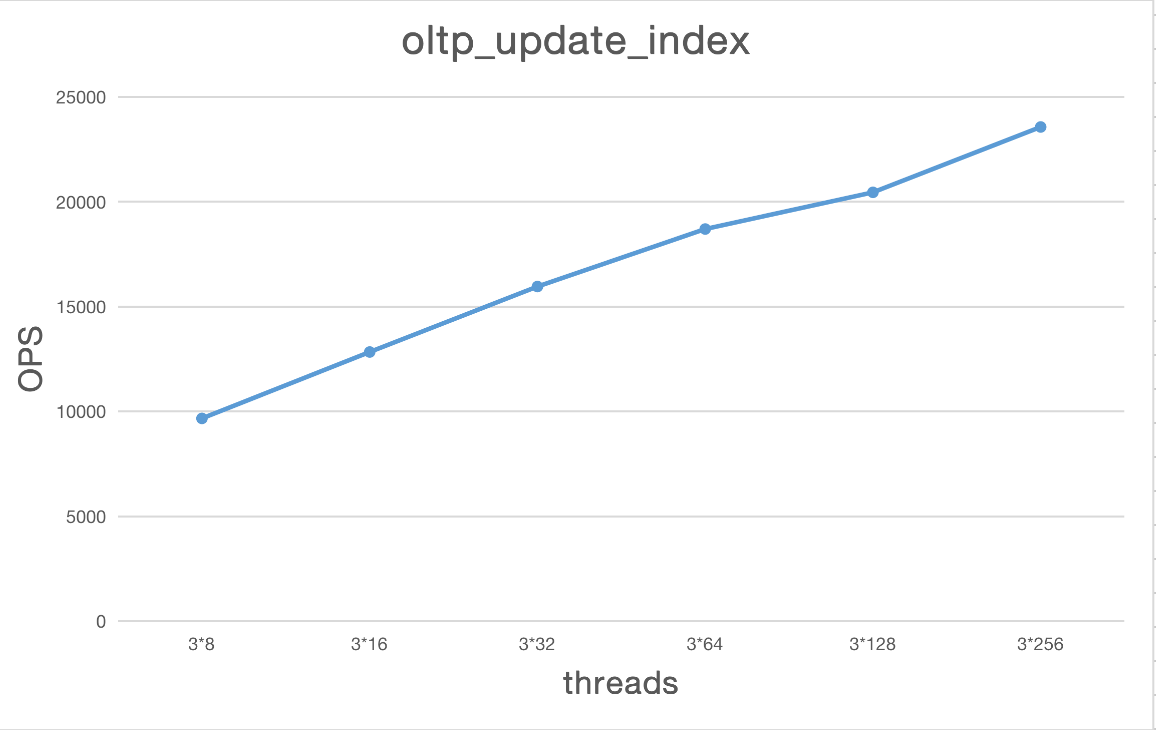
oltp_update_index
| 类型 | Thread | TPS | QPS | avg.latency(ms) | .95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| oltp_update_index | 3*8 | 9668.98 | 9668.98 | 2.51 | 3.19 | 103.88 |
| oltp_update_index | 3*16 | 12834.99 | 12834.99 | 3.79 | 5.47 | 176.90 |
| oltp_update_index | 3*32 | 15955.77 | 15955.77 | 6.07 | 9.39 | 4787.14 |
| oltp_update_index | 3*64 | 18697.17 | 18697.17 | 10.34 | 17.63 | 4539.04 |
| oltp_update_index | 3*128 | 20446.81 | 20446.81 | 18.98 | 40.37 | 5394.75 |
| oltp_update_index | 3*256 | 23563.03 | 23563.03 | 32.86 | 78.60 | 5530.69 |
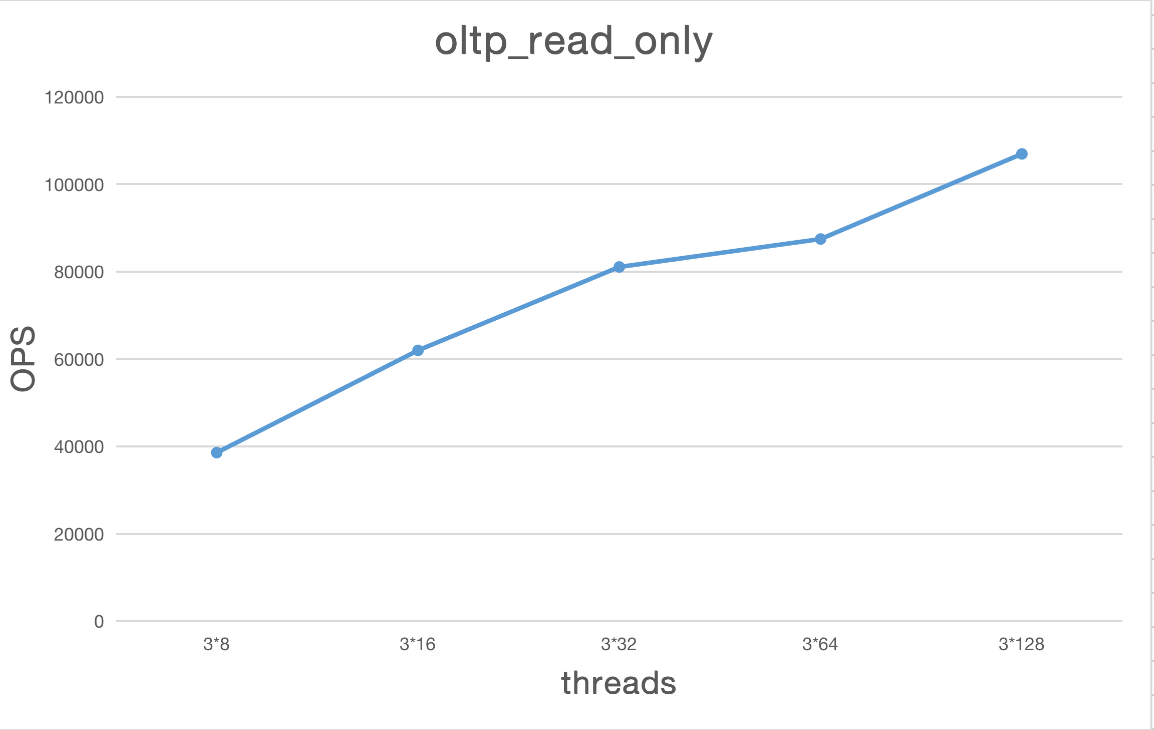
oltp_read_only
| 类型 | Thread | TPS | QPS | avg.latency(ms) | .95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| oltp_read_only | 3*8 | 2411.00 | 38575.96 | 9.92 | 20.00 | 92.23 |
| oltp_read_only | 3*16 | 3873.53 | 61976.50 | 12.25 | 16.12 | 56.94 |
| oltp_read_only | 3*32 | 5066.88 | 81070.16 | 19.42 | 26.20 | 123.41 |
| oltp_read_only | 3*64 | 5466.36 | 87461.81 | 34.65 | 63.20 | 231.19 |
| oltp_read_only | 3*128 | 6684.16 | 106946.59 | 57.29 | 97.55 | 180.85 |
常见问题
在高并发压力下,TiDB、TiKV 的配置都合理,为什么整体性能还是偏低?
这种情况可能与使用了 proxy 有关。可以尝试直接对单个 TiDB 加压,将求和后的结果与使用 proxy 的情况进行对比。
以 HAproxy 为例。nbproc 参数可以增加其最大启动的进程数,较新版本的 HAproxy 还支持 nbthread 和 cpu-map 等。这些都可以减少对其性能的不利影响。
在高并发压力下,为什么 TiKV 的 CPU 利用率依然很低?
TiKV 虽然整体 CPU 偏低,但部分模块的 CPU 可能已经达到了很高的利用率。
TiKV 的其他模块,如 storage readpool、coprocessor 和 gRPC 的最大并发度限制是可以通过 TiKV 的配置文件进行调整的。
通过 Grafana 的 TiKV Thread CPU 监控面板可以观察到其实际使用率。如出现多线程模块瓶颈,可以通过增加该模块并发度进行调整。
在高并发压力下,TiKV 也未达到 CPU 使用瓶颈,为什么 TiDB 的 CPU 利用率依然很低?
在某些高端设备上,使用的是 NUMA 架构的 CPU,跨 CPU 访问远端内存将极大降低性能。TiDB 默认将使用服务器所有 CPU,goroutine 的调度不可避免地会出现跨 CPU 内存访问。
因此,建议在 NUMA 架构服务器上,部署 n 个 TiDB(n = NUMA CPU 的个数),同时将 TiDB 的 max-procs 变量的值设置为与 NUMA CPU 的核数相同。