TiFlash Disaggregated Storage and Compute Architecture and S3 Support
By default, TiFlash is deployed using the coupled storage and compute architecture, in which each TiFlash node acts as both storage and compute node. Starting from TiDB v7.0.0, TiFlash supports the disaggregated storage and compute architecture and allows to store data in Amazon S3 or S3-compatible object storage (such as MinIO).
Architecture overview
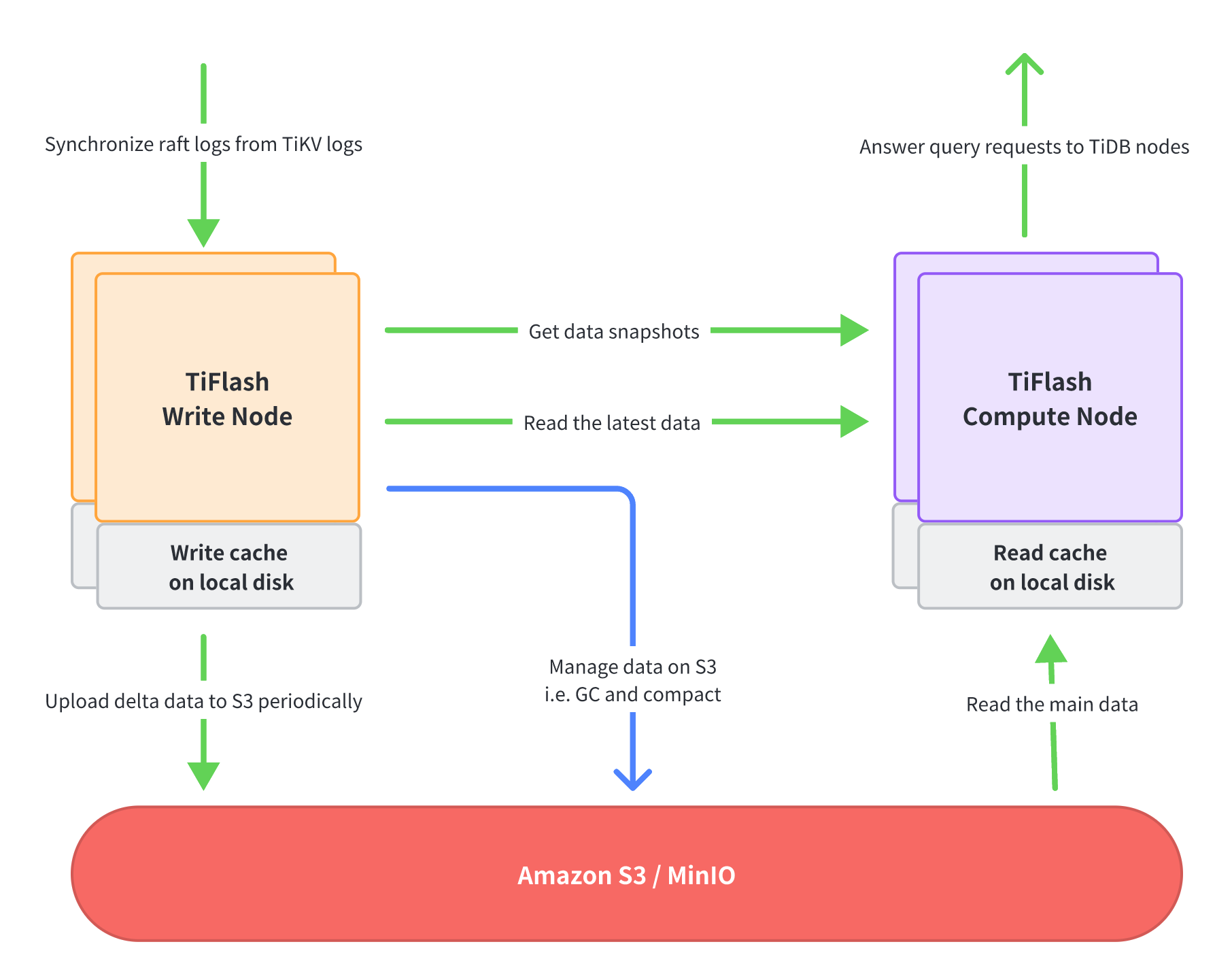
In the disaggregated storage and compute architecture, different functionalities of the TiFlash process are divided and allocated to two types of nodes: the Write Node and the Compute Node. These two types of nodes can be deployed separately and scaled independently, which means that you can decide the number of Write Nodes and Compute Nodes to be deployed as needed.
TiFlash Write Node
The Write Node receives Raft logs data from TiKV, converts the data into the columnar format, and periodically packages and uploads all the updated data within a certain period to S3. In addition, the Write Node manages the data on S3, such as continuously organizing data to improve query performance and deleting useless data.
The Write Node uses local disks (usually NVMe SSDs) to cache the latest written data to avoid excessive use of memory.
TiFlash Compute Node
The Compute Node executes query requests sent from a TiDB node. It first accesses a Write Node to obtain data snapshots, and then reads the latest data (that is, the data not been uploaded to S3 yet) from the Write Node and most of the remaining data from S3.
The Compute Node uses local disks (usually NVMe SSDs) as a cache for data files to avoid repeatedly reading the same data from remote locations (Write Nodes or S3) and improve query performance.
The Compute Node is stateless and its scaling speed is at a second level. You can use this feature to reduce costs as follows:
- When the query workload is low, reduce the number of Compute Nodes to save costs. When there are no queries, you can even stop all Compute Nodes.
- When the query workload increases, quickly increase the number of Compute Nodes to ensure query performance.
Scenarios
TiFlash disaggregated storage and compute architecture is suitable for cost-effective data analysis services. Because storage and compute resources can be scaled separately as needed in this architecture, you can get significant benefits in the following scenarios:
The amount of data is large, but only a small amount of data is frequently queried. Most of the data is cold data and rarely queried. At this time, the frequently queried data is usually cached on the local SSD of the Compute Node to provide fast query performance, while most of the other cold data is stored in low-cost S3 or other object storage to save storage costs.
The demand for compute resources has obvious peaks and valleys. For example, intensive reconciliation queries are usually performed at night, which demands high compute resources. In this case, you can consider temporarily adding more Compute Nodes at night. While at other times, you only need fewer Compute Nodes to complete regular query tasks.
Prerequisites
Prepare an Amazon S3 bucket for storing the TiFlash data.
You can also use an existing bucket, but you need to reserve dedicated key prefixes for each TiDB cluster. For more information about S3 buckets, see AWS documentation.
You can also use other S3-compatible object storage, such as MinIO.
TiFlash needs to use the following S3 APIs for accessing data. Make sure that TiFlash nodes in your TiDB cluster have the necessary permissions for these APIs.
- PutObject
- GetObject
- CopyObject
- DeleteObject
- ListObjectsV2
- GetObjectTagging
- PutBucketLifecycle
Make sure that your TiDB cluster has no TiFlash nodes deployed using the coupled storage and compute architecture. If any, set the TiFlash replica count of all tables to
0and then remove all TiFlash nodes. For example:SELECT * FROM INFORMATION_SCHEMA.TIFLASH_REPLICA; # Query all tables with TiFlash replicas ALTER TABLE table_name SET TIFLASH REPLICA 0; # Set the TiFlash replica count of all tables to `0`tiup cluster scale-in mycluster -N 'node0,node1...' # Remove all TiFlash nodes tiup cluster display mycluster # Wait for all TiFlash nodes to enter the Tombstone state tiup cluster prune mycluster # Remove all TiFlash nodes in the Tombstone state
Usage
By default, TiUP deploys TiFlash in the coupled storage and computation architecture. If you need to deploy TiFlash in the disaggregated storage and compute architecture, take the following steps for manual configuration:
Prepare a TiFlash topology configuration file, such as
scale-out.topo.yaml, with the following configuration:tiflash_servers: # In the TiFlash topology configuration file, the `storage.s3` configuration indicates that the disaggregated storage and compute architecture is used for deployment. # If `flash.disaggregated_mode: tiflash_compute` is configured for a node, it is a Compute Node. # If `flash.disaggregated_mode: tiflash_write` is configured for a node, it is a Write Node. # 172.31.8.1~2 are TiFlash Write Nodes - host: 172.31.8.1 config: flash.disaggregated_mode: tiflash_write # This is a Write Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 endpoint address storage.s3.bucket: mybucket # TiFlash stores all data in this bucket storage.s3.root: /cluster1_data # Root directory where data is stored in the S3 bucket storage.s3.access_key_id: {ACCESS_KEY_ID} # Access S3 with ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # Access S3 with SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Local data directory of the Write Node. Configure it in the same way as the directory configuration of the coupled storage and compute architecture - host: 172.31.8.2 config: flash.disaggregated_mode: tiflash_write # This is a Write Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 endpoint address storage.s3.bucket: mybucket # TiFlash stores all data in this bucket storage.s3.root: /cluster1_data # Root directory where data is stored in the S3 bucket storage.s3.access_key_id: {ACCESS_KEY_ID} # Access S3 with ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # Access S3 with SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Local data directory of the Write Node. Configure it in the same way as the directory configuration of the coupled storage and compute architecture # 172.31.9.1~2 are TiFlash Compute Nodes - host: 172.31.9.1 config: flash.disaggregated_mode: tiflash_compute # This is a Compute Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 endpoint address storage.s3.bucket: mybucket # TiFlash stores all data in this bucket storage.s3.root: /cluster1_data # Root directory where data is stored in the S3 bucket storage.s3.access_key_id: {ACCESS_KEY_ID} # Access S3 with ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # Access S3 with SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Local data directory of the Compute Node. Configure it in the same way as the directory configuration of the coupled storage and compute architecture storage.remote.cache.dir: /data1/tiflash/cache # Local data cache directory of the Compute Node storage.remote.cache.capacity: 858993459200 # 800 GiB - host: 172.31.9.2 config: flash.disaggregated_mode: tiflash_compute # This is a Compute Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 endpoint address storage.s3.bucket: mybucket # TiFlash stores all data in this bucket storage.s3.root: /cluster1_data # Root directory where data is stored in the S3 bucket storage.s3.access_key_id: {ACCESS_KEY_ID} # Access S3 with ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # Access S3 with SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Local data directory of the Compute Node. Configure it in the same way as the directory configuration of the coupled storage and compute architecture storage.remote.cache.dir: /data1/tiflash/cache # Local data cache directory of the Compute Node storage.remote.cache.capacity: 858993459200 # 800 GiBNote that the above
ACCESS_KEY_IDandSECRET_ACCESS_KEYare directly written in the configuration file. You can also choose to configure them separately using environment variables. If both ways are configured, the environment variables have higher priority.To configure
ACCESS_KEY_IDandSECRET_ACCESS_KEYthrough environment variables, switch to the user environment that starts the TiFlash process (usuallytidb) on all machines where TiFlash processes are deployed, and then modify~/.bash_profileto add the following configurations:export S3_ACCESS_KEY_ID={ACCESS_KEY_ID} export S3_SECRET_ACCESS_KEY={SECRET_ACCESS_KEY}storage.s3.endpointsupports connecting to S3 using thehttporhttpsmode, and you can set the mode by directly modifying the URL. For example,https://s3.{region}.amazonaws.com.
Add TiFlash nodes and reset the number of TiFlash replicas:
tiup cluster scale-out mycluster ./scale-out.topo.yamlALTER TABLE table_name SET TIFLASH REPLICA 1;Modify the TiDB configuration to query TiFlash using the disaggregated storage and compute architecture.
Open the TiDB configuration file in edit mode:
tiup cluster edit-config myclusterAdd the following configuration items to the TiDB configuration file:
server_configs: tidb: disaggregated-tiflash: true # Query TiFlash using the disaggregated storage and compute architectureRestart TiDB:
tiup cluster reload mycluster -R tidb
Restrictions
- TiFlash does not support in-place switching between the disaggregated storage and compute architecture and the coupled storage and compute architecture. Before switching to the disaggregated architecture, you must remove all existing TiFlash nodes deployed using the coupled architecture.
- After the migration from one architecture to another, all TiFlash data needs to be replicated again.
- Only TiFlash nodes with the same architecture are allowed in the same TiDB cluster. Two architectures cannot coexist in one cluster.
- The disaggregated storage and compute architecture only supports object storage using the S3 API, while the coupled storage and compute architecture only supports local storage.
- When using S3 storage, TiFlash nodes cannot obtain the keys of files not on their own nodes, so the Encryption at Rest feature cannot be used.