Architecture and Principles of TiCDC
TiCDC architecture
Consisting of multiple TiCDC nodes, a TiCDC cluster uses a distributed and stateless architecture. The design of TiCDC and its components is as follows:
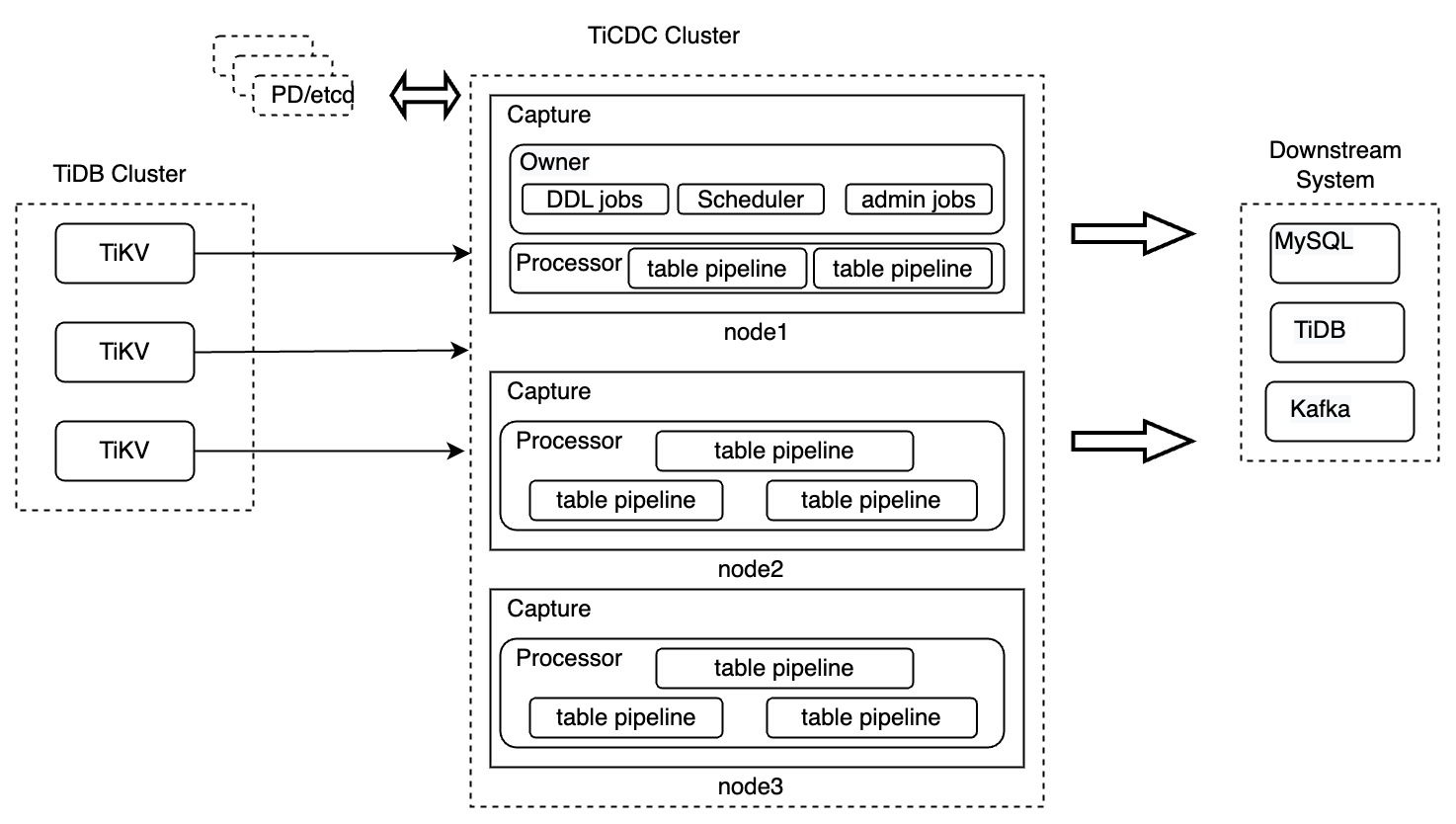
TiCDC components
In the preceding diagram, a TiCDC cluster consists of multiple nodes running TiCDC instances. Each TiCDC instance carries a Capture process. One of the Capture processes is elected as the owner Capture, which is responsible for scheduling workload, replicating DDL statements, and performing management tasks.
Each Capture process contains one or multiple Processor threads for replicating data from tables in the upstream TiDB. Because table is the minimum unit of data replication in TiCDC, a Processor is composed of multiple table pipelines.
Each pipeline contains the following components: Puller, Sorter, Mounter, and Sink.
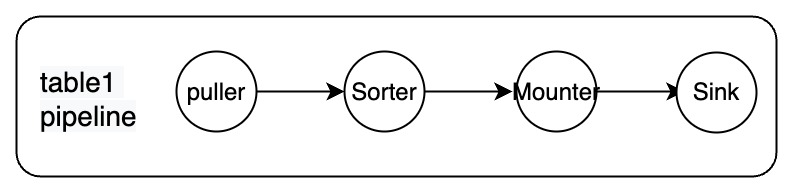
These components work in serial with each other to complete the replication process, including pulling data, sorting data, loading data, and replicating data from the upstream to the downstream. The components are described as follows:
- Puller: pulls DDL and row changes from TiKV nodes.
- Sorter: sorts the changes received from TiKV nodes in ascending order of timestamps.
- Mounter: converts the changes into a format that TiCDC sink can process based on the schema information.
- Sink: replicates the changes to the downstream system.
To realize high availability, each TiCDC cluster runs multiple TiCDC nodes. These nodes regularly report their status to the etcd cluster in PD, and elect one of the nodes as the owner of the TiCDC cluster. The owner node schedules data based on the status stored in etcd and writes the scheduling results to etcd. The Processor completes tasks according to the status in etcd. If the node running the Processor fails, the cluster schedules tables to other nodes. If the owner node fails, the Capture processes in other nodes will elect a new owner. See the following figure:
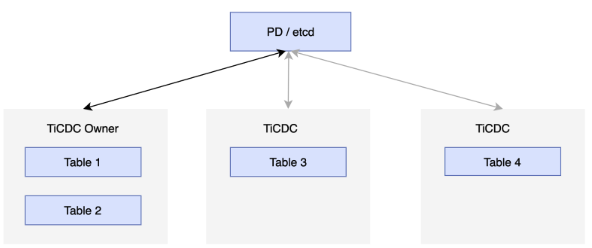
Changefeeds and tasks
Changefeed and Task in TiCDC are two logical concepts. The specific description is as follows:
- Changefeed: Represents a replication task. It carries the information about the tables to be replicated and the downstream.
- Task: After TiCDC receives a replication task, it splits this task into several subtasks. Such a subtask is called Task. These Tasks are assigned to the Capture processes of the TiCDC nodes for processing.
For example:
cdc cli changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://127.0.0.1:9092/cdc-test?kafka-version=2.4.0&partition-num=6&max-message-bytes=67108864&replication-factor=1"
cat changefeed.toml
......
[sink]
dispatchers = [
{matcher = ['test1.tab1', 'test2.tab2'], topic = "{schema}_{table}"},
{matcher = ['test3.tab3', 'test4.tab4'], topic = "{schema}_{table}"},
]
For a detailed description of the parameters in the preceding cdc cli changefeed create command, see TiCDC Changefeed Configuration Parameters.
The preceding cdc cli changefeed create command creates a changefeed task that replicates test1.tab1, test1.tab2, test3.tab3, and test4.tab4 to the Kafka cluster. The processing flow after TiCDC receives this command is as follows:
- TiCDC sends this task to the owner Capture process.
- The owner Capture process saves information about this changefeed task in etcd in PD.
- The owner Capture process splits the changefeed task into several Tasks and notifies other Capture processes of the Tasks to be completed.
- The Capture processes start pulling data from TiKV nodes, process the data, and complete replication.
The following is the TiCDC architecture diagram with Changefeed and Task included:
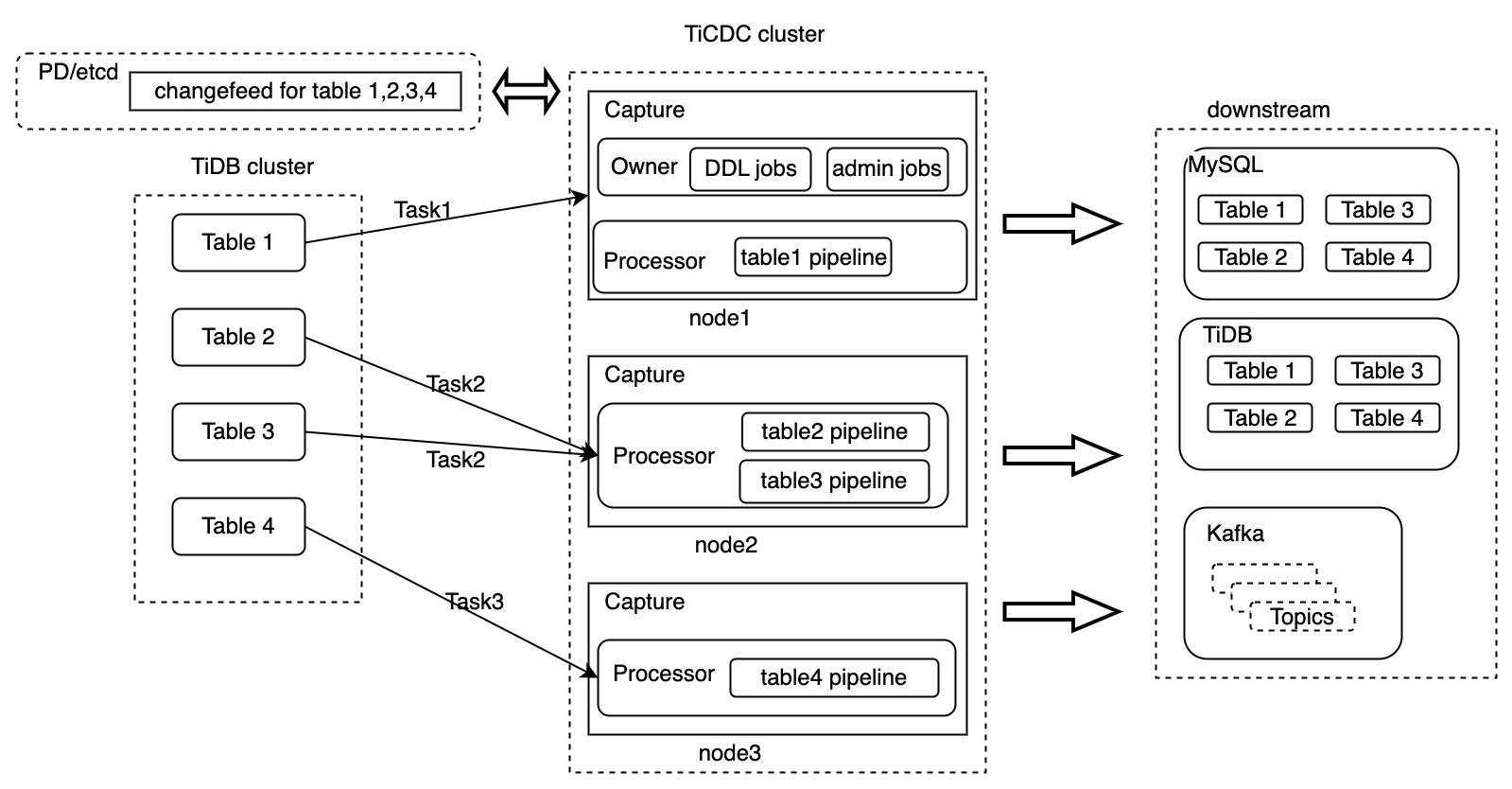
In the preceding diagram, a changefeed is created to replicate four tables to downstream. This changefeed is split into three Tasks, which are sent to the three Capture processes respectively in the TiCDC cluster. After TiCDC processes the data, the data is replicated to the downstream system.
TiCDC supports replicating data to MySQL, TiDB, and Kafka databases. The preceding diagram only illustrates the process of data transfer at the changefeed level. The following sections describe in detail how TiCDC processes data, using Task1 that replicates table table1 as an example.
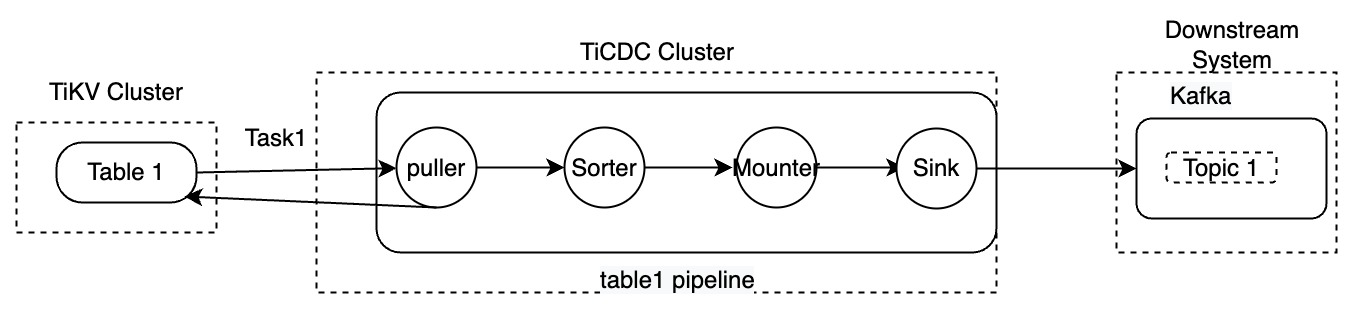
- Push data: When a data change occurs, TiKV pushes data to the Puller module.
- Scan incremental data: The Puller module pulls data from TiKV when it finds the data changes received not continuous.
- Sort data: The Sorter module sorts the data received from TiKV based on the timestamps and sends the sorted data to the Mounter module.
- Mount data: After receiving the data changes, the Mounter module loads the data in a format that TiCDC sink can understand.
- Replicate data: The Sink module replicates the data changes to the downstream.
The upstream of TiCDC is the distributed relational database TiDB that supports transactions. When TiCDC replicates data, it should ensure the consistency of data and that of transactions when replicating multiple tables, which is a great challenge. The following sections introduce the key technologies and concepts used by TiCDC to address this challenge.
Key concepts of TiCDC
For the downstream relational databases, TiCDC ensures the consistency of transactions in a single table and eventual transaction consistency in multiple tables. In addition, TiCDC ensures that any data change that has occurred in the upstream TiDB cluster can be replicated to the downstream at least once.
Architecture-related concepts
- Capture: The process that runs the TiCDC node. Multiple Capture processes constitute a TiCDC cluster. Each Capture process is responsible for replicating data changes in TiKV, including receiving and actively pulling data changes, and replicating the data to the downstream.
- Capture Owner: The owner Capture among multiple Capture processes. Only one owner role exists in a TiCDC cluster at a time. The Capture Owner is responsible for scheduling data within the cluster.
- Processor: The logical thread inside Capture. Each Processor is responsible for processing the data of one or more tables in the same replication stream. A Capture node can run multiple Processors.
- Changefeed: A task that replicates data from an upstream TiDB cluster to a downstream system. A changefeed contains multiple Tasks, and each Task is processed by a Capture node.
Timestamp-related concepts
TiCDC introduces a series of timestamps (TS) to indicate the status of data replication. These timestamps are used to ensure that data is replicated to the downstream at least once and that the consistency of data is guaranteed.
ResolvedTS
This timestamp exists in both TiKV and TiCDC.
ResolvedTS in TiKV: Represents the start time of the earliest transaction in a Region leader, that is,
ResolvedTS= max(ResolvedTS, min(StartTS)). Because a TiDB cluster contains multiple TiKV nodes, the minimum ResolvedTS of the Region leader on all TiKV nodes is called the global ResolvedTS. The TiDB cluster ensures that all transactions before the global ResolvedTS are committed. Alternatively, you can assume that there are no uncommitted transactions before this timestamp.ResolvedTS in TiCDC:
table ResolvedTS: Each table has a table-level ResolvedTS, which indicates all data changes in the table that are smaller than the Resolved TS have been received. To make it simple, this timestamp is the same as the minimum value of the ResolvedTS of all Regions corresponding to this table on the TiKV node.
global ResolvedTS: The minimum ResolvedTS of all Processors on all TiCDC nodes. Because each TiCDC node has one or more Processors, each Processor corresponds to multiple table pipelines.
For TiCDC, the ResolvedTS sent by TiKV is a special event in the format of
<resolvedTS: timestamp>. In general, the ResolvedTS satisfies the following constraints:table ResolvedTS >= global ResolvedTS
CheckpointTS
This timestamp exists only in TiCDC. It means that the data changes that occur before this timestamp have been replicated to the downstream system.
- table CheckpointTS: Because TiCDC replicates data in tables, the table checkpointTS indicates all data changes that occur before CheckpointTS have been replicated at the table level.
- processor CheckpointTS: Indicates the minimum table CheckpointTS on a Processor.
- global CheckpointTS: Indicates the minimum CheckpointTS among all Processors.
Generally, a checkpointTS satisfies the following constraint:
table CheckpointTS >= global CheckpointTS
Because TiCDC only replicates data smaller than the global ResolvedTS to the downstream, the complete constraint is as follows:
table ResolvedTS >= global ResolvedTS >= table CheckpointTS >= global CheckpointTS
After data changes and transactions are committed, the ResolvedTS on the TiKV node will continue to advance, and the Puller module on the TiCDC node keeps receiving data pushed by TiKV. The Puller module also decides whether to scan incremental data based on the data changes it has received, which ensures that all data changes are sent to the TiCDC node.
The Sorter module sorts data received by the Puller module in ascending order according to the timestamp. This process ensures data consistency at the table level. Next, the Mounter module assembles the data changes from the upstream into a format that the Sink module can consume, and sends it to the Sink module. The Sink module replicates the data changes between the CheckpointTS and the ResolvedTS to the downstream in the order of the timestamp, and advances the checkpointTS after the downstream receives the data changes.
The preceding sections only cover data changes of DML statements and do not include DDL statements. The following sections introduce the timestamp related to DDL statements.
Barrier TS
Barrier TS is generated when there are DDL change events or a Syncpoint is used.
- DDL change events: Barrier TS ensures that all changes before the DDL statement are replicated to the downstream. After this DDL statement is executed and replicated, TiCDC starts replicating other data changes. Because DDL statements are processed by the Capture Owner, the Barrier TS corresponding to a DDL statement is only generated by the owner node.
- Syncpoint: When you enable the Syncpoint feature of TiCDC, a Barrier TS is generated by TiCDC according to the
sync-point-intervalyou specified. When all table changes before this Barrier TS are replicated, TiCDC inserts the current global CheckpointTS as the primary TS to the table recording tsMap in downstream. Then TiCDC continues data replication.
After a Barrier TS is generated, TiCDC ensures that only data changes that occur before this Barrier TS are replicated to downstream. Before these data changes are replicated to downstream, the replication task does not proceed. The owner TiCDC checks whether all target data has been replicated by continuously comparing the global CheckpointTS and the Barrier TS. If the global CheckpointTS equals to the Barrier TS, TiCDC continues replication after performing a designated operation (such as executing a DDL statement or recording the global CheckpointTS downstream). Otherwise, TiCDC waits for all data changes that occur before the Barrier TS to be replicated to the downstream.
Major processes
This section describes the major processes of TiCDC to help you better understand its working principles.
Note that the following processes occur only within TiCDC and are transparent to users. Therefore, you do not need to care about which TiCDC node you are starting.
Start TiCDC
For a TiCDC node that is not an owner, it works as follows:
- Starts the Capture process.
- Starts the Processor.
- Receives the Task scheduling command executed by the Owner.
- Starts or stops tablePipeline according to the scheduling command.
For an owner TiCDC node, it works as follows:
- Starts the Capture process.
- The node is elected as the Owner and the corresponding thread is started.
- Reads the changefeed information.
- Starts the changefeed management process.
- Reads the schema information in TiKV according to the changefeed configuration and the latest CheckpointTS to determine the tables to be replicated.
- Reads the list of tables currently replicated by each Processor and distributes the tables to be added.
- Updates the replication progress.
Stop TiCDC
Usually, you stop a TiCDC node when you need to upgrade it or perform some planned maintenance operations. The process of stopping a TiCDC node is as follows:
- The node receives the command to stop itself.
- The node sets its service status to unavailable.
- The node stops receiving new replication tasks.
- The node notifies the Owner node to transfer its data replication tasks to other nodes.
- The node stops after the replication tasks are transferred to other nodes.