Continuous Data Validation in DM
This document describes how to use continuous data validation in DM, its working principles, and its limitations.
User scenario
In the process of incrementally migrating data from the upstream database to the downstream database, there is a small probability that the flow of data leads to data corruption or data loss. For scenarios where data consistency is required, such as the credit and securities industries, after the migration is complete, you can perform full data validation to ensure data consistency.
However, in incremental migration scenarios, the upstream and downstream are continuously writing data. Because data is constantly changing in the upstream and downstream, it is difficult to perform full data validation (for example, use sync-diff-inspector) to all data in the tables.
In incremental migration scenarios, you can use the continuous data validation feature in DM. This feature ensures data integrity and consistency during incremental migration where data is continuously written into the downstream.
Enable continuous data validation
You can enable continuous data validation using either of the following methods:
- Enable in the task configuration file.
- Enable using dmctl.
Method 1: Enable in the task configuration file
To enable continuous data validation, add the following configuration items to the task configuration file:
# Add the following configuration items to the upstream database that needs to be validated:
mysql-instances:
- source-id: "mysql1"
block-allow-list: "bw-rule-1"
validator-config-name: "global"
validators:
global:
mode: full # "fast" is also allowed. "none" is the default mode, which means no validation is performed.
worker-count: 4 # The number of validation workers in the background. The default value is 4.
row-error-delay: 30m # If a row cannot pass the validation within the specified time, it will be marked as an error row. The default value is 30m, which means 30 minutes.
The configuration items are described as follows:
mode: validation mode. The possible values arenone,full, andfast.none: the default value, which means no validation is performed.full: compares the changed row and the row obtained in the downstream database.fast: only checks if the changed row exists in the downstream database.
worker-count: the number of validation workers in the background. Each worker is a goroutine.row-error-delay: if a row cannot pass the validation within the specified time, it will be marked as an error row. The default value is 30 minutes.
For the complete configuration, refer to DM Advanced Task Configuration File.
Method 2: Enable using dmctl
To enable continuous data validation, run the dmctl validation start command:
Usage:
dmctl validation start [--all-task] [task-name] [flags]
Flags:
--all-task whether applied to all tasks
-h, --help help for start
--mode string specify the mode of validation: full (default), fast; this flag will be ignored if the validation task has been ever enabled but currently paused (default "full")
--start-time string specify the start time of binlog for validation, e.g. '2021-10-21 00:01:00' or 2021-10-21T00:01:00
--mode: specify the validation mode. The possible values arefastandfull.--start-time: specify the start time for validation. The format follows2021-10-21 00:01:00or2021-10-21T00:01:00.task: specify the name of the task to enable continuous validation for. You can use--all-taskto enable validation for all tasks.
For example:
dmctl --master-addr=127.0.0.1:8261 validation start --start-time 2021-10-21T00:01:00 --mode full my_dm_task
Use continuous data validation
When you use continuous data validation, you can use dmctl to view the status of the validation and to handle the error rows. "Error rows" refers to the rows that are found to be inconsistent between the upstream and downstream databases.
View the validation status
You can view the validation status using either of the following methods:
Method 1: run the dmctl query-status <task-name> command. If continuous data validation is enabled, the validation result is displayed in the validation field of each subtask. Example output:
"subTaskStatus": [
{
"name": "test",
"stage": "Running",
"unit": "Sync",
"result": null,
"unresolvedDDLLockID": "",
"sync": {
...
},
"validation": {
"task": "test", // Task name
"source": "mysql-01", // Source id
"mode": "full", // Validation mode
"stage": "Running", // Current stage. "Running" or "Stopped".
"validatorBinlog": "(mysql-bin.000001, 5989)", // The binlog position of the validation
"validatorBinlogGtid": "1642618e-cf65-11ec-9e3d-0242ac110002:1-30", // The GTID position of the validation
"cutoverBinlogPos": "", // The specified binlog position for cutover
"cutoverBinlogGTID": "1642618e-cf65-11ec-9e3d-0242ac110002:1-30", // The specified GTID position for cutover
"result": null, // When the validation is abnormal, show the error message
"processedRowsStatus": "insert/update/delete: 0/0/0", // Statistics of the processed binlog rows.
"pendingRowsStatus": "insert/update/delete: 0/0/0", // Statistics of the binlog rows that are not validated yet or that fail to be validated but are not marked as "error rows"
"errorRowsStatus": "new/ignored/resolved: 0/0/0" // Statistics of the error rows. The three statuses are explained in the next section.
}
}
]
Method 2: run the dmctl validation status <taskname> command.
dmctl validation status [--table-stage stage] <task-name> [flags]
Flags:
-h, --help help for status
--table-stage string filter validation tables by stage: running/stopped
In the preceding command, you can use --table-stage to filter the tables that are being validated or stop validation. Example output:
{
"result": true,
"msg": "",
"validators": [
{
"task": "test",
"source": "mysql-01",
"mode": "full",
"stage": "Running",
"validatorBinlog": "(mysql-bin.000001, 6571)",
"validatorBinlogGtid": "",
"cutoverBinlogPos": "(mysql-bin.000001, 6571)",
"cutoverBinlogGTID": "",
"result": null,
"processedRowsStatus": "insert/update/delete: 2/0/0",
"pendingRowsStatus": "insert/update/delete: 0/0/0",
"errorRowsStatus": "new/ignored/resolved: 0/0/0"
}
],
"tableStatuses": [
{
"source": "mysql-01", // Source id
"srcTable": "`db`.`test1`", // Source table name
"dstTable": "`db`.`test1`", // Target table name
"stage": "Running", // Validation status
"message": "" // Error message
}
]
}
If you want to view the details of the error rows, such as error types and error time, run the dmctl validation show-error command:
Usage:
dmctl validation show-error [--error error-state] <task-name> [flags]
Flags:
--error string filtering type of error: all, ignored, or unprocessed (default "unprocessed")
-h, --help help for show-error
Example output:
{
"result": true,
"msg": "",
"error": [
{
"id": "1", // Error row id, which will be used in processing error rows
"source": "mysql-replica-01", // Source id
"srcTable": "`validator_basic`.`test`", // Source table of the error row
"srcData": "[0, 0]", // Data of the error row in the source table
"dstTable": "`validator_basic`.`test`", // Target table of the error row
"dstData": "[]", // Data of the error row in the target table
"errorType": "Expected rows not exist", // Error type
"status": "NewErr", // Error status
"time": "2022-07-04 13:33:02", // Discovery time of the error row
"message": "" // Additional information
}
]
}
Handle error rows
After continuous data validation returns error rows, you need to manually handle the error rows.
When continuous data validation finds error rows, the validation does not stop immediately. Instead, it records the error rows for you to handle. Before the error rows are processed, the default status is unprocessed. If you manually correct the error rows in the downstream, the validation does not automatically retrieve the latest status of the corrected data. The error rows are still recorded in the error field.
If you do not want to see an error row in the validation status, or if you want to mark an error row as resolved, you can locate the error row id using the validation show-error command and subsequently handle it with the given error id:
dmctl provides three error handling commands:
clear-error: clear the error row. Theshow-errorcommand does not show the error row anymore.Usage: dmctl validation clear-error <task-name> <error-id|--all> [flags] Flags: --all all errors -h, --help help for clear-errorignore-error: ignore the error row. This error row is marked as "ignored".Usage: dmctl validation ignore-error <task-name> <error-id|--all> [flags] Flags: --all all errors -h, --help help for ignore-errorresolve-error: the error row is manually handled and marked as "resolved".Usage: dmctl validation resolve-error <task-name> <error-id|--all> [flags] Flags: --all all errors -h, --help help for resolve-error
Stop continuous data validation
To stop the continuous data validation, run the validation stop command:
Usage:
dmctl validation stop [--all-task] [task-name] [flags]
Flags:
--all-task whether applied to all tasks
-h, --help help for stop
For detailed usage, refer to dmctl validation start.
Set the cutover point for continuous data validation
Before switching the application to another database, you might need to perform continuous data validation immediately after the data is replicated to a specific position to ensure data integrity. To achieve this, you can set this specific position as the cutover point for continuous validation.
To set the cutover point for continuous data validation, use the validation update command:
Usage:
dmctl validation update <task-name> [flags]
Flags:
--cutover-binlog-gtid string specify the cutover binlog gtid for validation, only valid when source config's gtid is enabled, e.g. '1642618e-cf65-11ec-9e3d-0242ac110002:1-30'
--cutover-binlog-pos string specify the cutover binlog name for validation, should include binlog name and pos in brackets, e.g. '(mysql-bin.000001, 5989)'
-h, --help help for update
--cutover-binlog-gtid: specifies the cutover position for validation, in the format of1642618e-cf65-11ec-9e3d-0242ac110002:1-30. Only valid when GTID is enabled in the upstream cluster.--cutover-binlog-pos: specifies the cutover position for validation, in the format of(mysql-bin.000001, 5989).task-name: the name of the task for continuous data validation. This parameter is required.
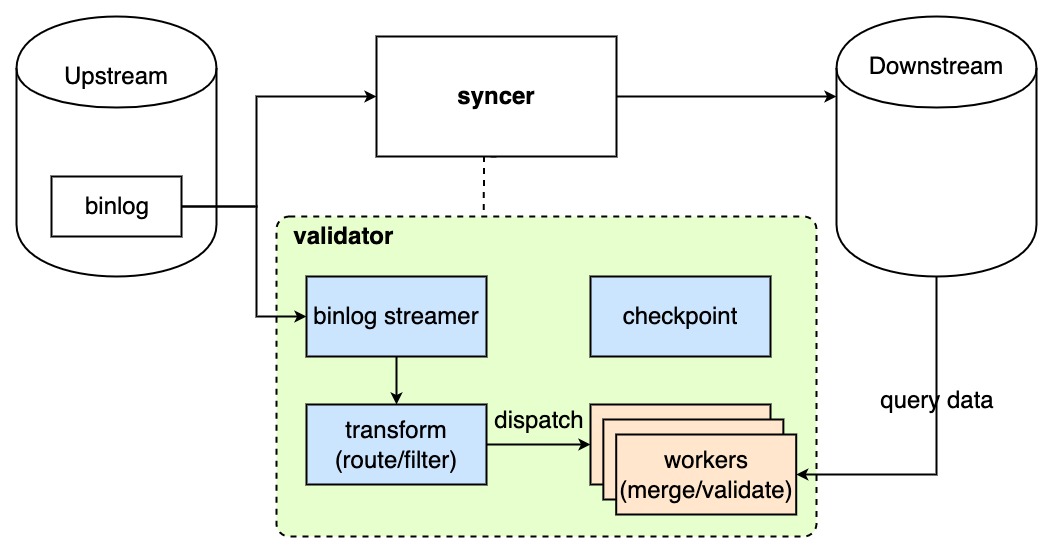
Implementation
The architecture of continuous data validation (validator) in DM is as follows:
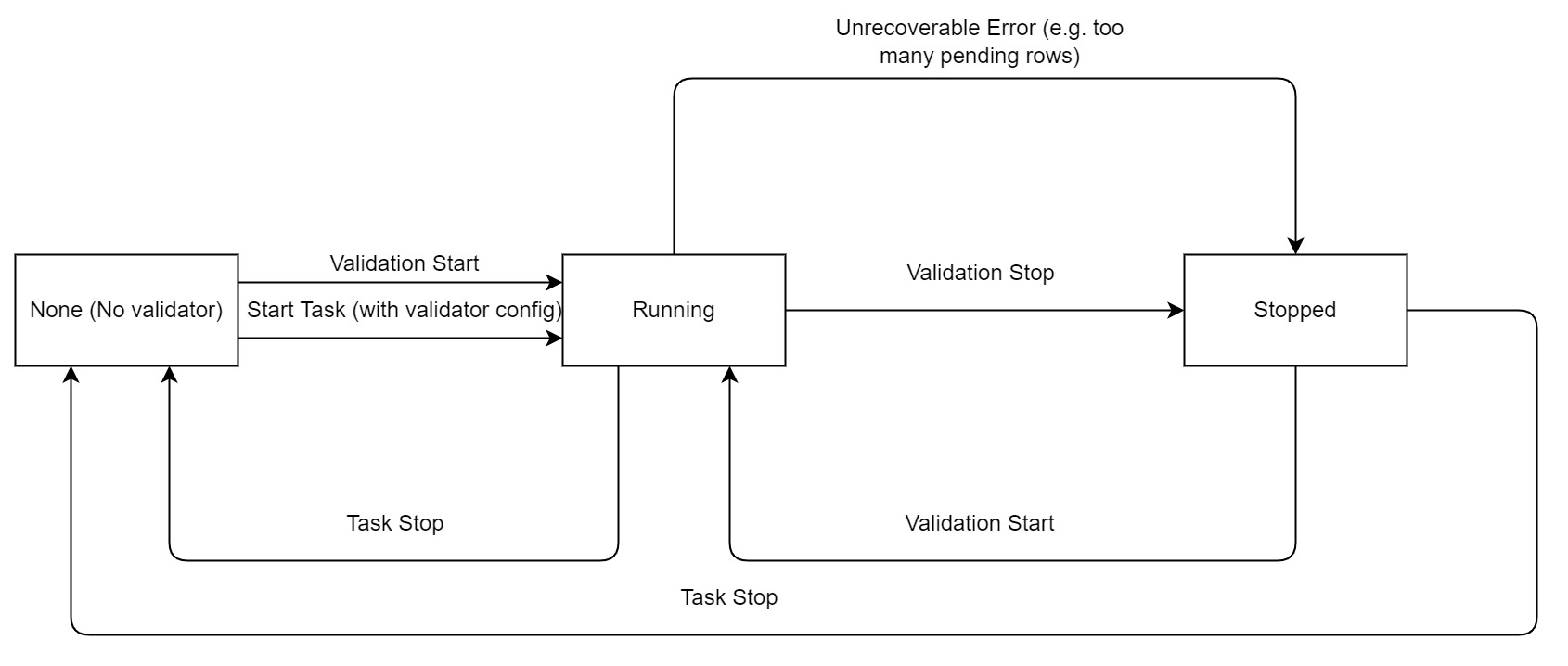
The lifecycle of continuous data validation is as follows:
The detailed implementation of continuous data validation is as follows:
- The validator pulls a binlog event from the upstream and gets the changed rows:
- The validator only checks a event that has been incrementally migrated by the syncer. If the event has not been processed by the syncer, the validator pauses and waits for the syncer to complete processing.
- If the event has been processed by the syncer, the validator moves on to the following steps.
- The validator parses the binlog event and filters out the rows based on the block and allow lists, the table filters, and table routing. After that, the validator submits the changed rows to the validation worker that runs in the background.
- The validation worker merges the changed rows that affect the same table and the same primary key to avoid validating "expired" data. The changed rows are cached in memory.
- When the validation worker has accumulated a certain number of changed rows or when a certain time interval is passed, the validation worker queries the downstream database using the primary keys to get the current data and compares it with the changed rows.
- The validation worker performs the data validation. If the validation mode is
full, the validation worker compares data of the changed rows with data of the downstream database. if the validation mode isfast, the validation worker only checks the existence of the changed rows.- If the changed rows pass the validation, the changed row is removed from the memory.
- If the changed rows fail the validation, the validator does not report an error immediately but waits for a certain time interval before validating the row again.
- If a changed row cannot pass the validation within the specified time (specified by the user), the validator marks the row as an error row and writes it to the meta database in the downstream. You can view the information of error rows by querying the migration task. For details, refer to View the validation status and Handle error rows.
Limitations
- The source table to be validated must have a primary key or a not-null unique key.
- When DM migrates DDL from the upstream database, the following limitations apply:
- The DDL must not change the primary key, or change the order of columns, or delete existing columns.
- The table must not be dropped.
- Does not support tasks that use expressions to filter events.
- The precision of floating-point numbers is different between TiDB and MySQL. Differences smaller than 10^-6 are considered equal.
- Does not support the following data types:
- JSON
- Binary data