Troubleshoot Lock Conflicts
TiDB supports complete distributed transactions. Starting from v3.0, TiDB provides optimistic transaction mode and pessimistic transaction mode. This document describes how to use Lock View to troubleshoot lock issues and how to deal with common lock conflict issues in optimistic and pessimistic transactions.
Use Lock View to troubleshoot lock issues
Since v5.1, TiDB supports the Lock View feature. This feature has several system tables built in information_schema that provide more information about the lock conflicts and lock waitings.
For the detailed introduction of these tables, see the following documents:
TIDB_TRXandCLUSTER_TIDB_TRX: Provides information of all running transactions on the current TiDB node or in the entire cluster, including whether the transaction is in the lock-waiting state, the lock-waiting time, and the digests of statements that have been executed in the transaction.DATA_LOCK_WAITS: Provides the pessimistic lock-waiting information in TiKV, including thestart_tsof the blocking and blocked transaction, the digest of the blocked SQL statement, and the key on which the waiting occurs.DEADLOCKSandCLUSTER_DEADLOCKS: Provides the information of several deadlock events that have recently occurred on the current TiDB node or in the entire cluster, including the waiting relationship among transactions in the deadlock loops, the digest of the statement currently being executed in the transaction, and the key on which the waiting occurs.
The following sections show the examples of troubleshooting some issues using these tables.
Deadlock errors
To get the information of the recent deadlock errors, you can query the DEADLOCKS or CLUSTER_DEADLOCKS table.
For example, to query the DEADLOCKS table, you can execute the following SQL statement:
select * from information_schema.deadlocks;
The following is an example output:
+-------------+----------------------------+-----------+--------------------+------------------------------------------------------------------+-----------------------------------------+----------------------------------------+----------------------------------------------------------------------------------------------------+--------------------+
| DEADLOCK_ID | OCCUR_TIME | RETRYABLE | TRY_LOCK_TRX_ID | CURRENT_SQL_DIGEST | CURRENT_SQL_DIGEST_TEXT | KEY | KEY_INFO | TRX_HOLDING_LOCK |
+-------------+----------------------------+-----------+--------------------+------------------------------------------------------------------+-----------------------------------------+----------------------------------------+----------------------------------------------------------------------------------------------------+--------------------+
| 1 | 2021-08-05 11:09:03.230341 | 0 | 426812829645406216 | 22230766411edb40f27a68dadefc63c6c6970d5827f1e5e22fc97be2c4d8350d | update `t` set `v` = ? where `id` = ? ; | 7480000000000000355F728000000000000002 | {"db_id":1,"db_name":"test","table_id":53,"table_name":"t","handle_type":"int","handle_value":"2"} | 426812829645406217 |
| 1 | 2021-08-05 11:09:03.230341 | 0 | 426812829645406217 | 22230766411edb40f27a68dadefc63c6c6970d5827f1e5e22fc97be2c4d8350d | update `t` set `v` = ? where `id` = ? ; | 7480000000000000355F728000000000000001 | {"db_id":1,"db_name":"test","table_id":53,"table_name":"t","handle_type":"int","handle_value":"1"} | 426812829645406216 |
+-------------+----------------------------+-----------+--------------------+------------------------------------------------------------------+-----------------------------------------+----------------------------------------+----------------------------------------------------------------------------------------------------+--------------------+
The query result above shows the waiting relationship among multiple transactions in the deadlock error, the normalized form of the SQL statements currently being executed in each transaction (statements without formats and arguments), the key on which the conflict occurs, and the information of the key.
For example, in the above example, the first row means that the transaction with the ID of 426812829645406216 is executing a statement like update `t` set `v` =? Where `id` =? ; but is blocked by another transaction with the ID of 426812829645406217. The transaction with the ID of 426812829645406217 is also executing a statement that is in the form of update `t` set `v` =? Where `id` =? ; but is blocked by the transaction with the ID of 426812829645406216. The two transactions thus form a deadlock.
A few hot keys cause queueing locks
The DATA_LOCK_WAITS system table provides the lock-waiting status on the TiKV nodes. When you query this table, TiDB automatically obtains the real-time lock-waiting information from all TiKV nodes. If a few hot keys are frequently locked and block many transactions, you can query the DATA_LOCK_WAITS table and aggregate the results by key to try to find the keys on which issues frequently occur:
select `key`, count(*) as `count` from information_schema.data_lock_waits group by `key` order by `count` desc;
The following is an example output:
+----------------------------------------+-------+
| key | count |
+----------------------------------------+-------+
| 7480000000000000415F728000000000000001 | 2 |
| 7480000000000000415F728000000000000002 | 1 |
+----------------------------------------+-------+
To avoid contingency, you might need to make multiple queries.
If you know the key that frequently has issues occurred, you can try to get the information of the transaction that tries to lock the key from the TIDB_TRX or CLUSTER_TIDB_TRX table.
Note that the information displayed in the TIDB_TRX and CLUSTER_TIDB_TRX tables is also the information of the transactions that are running at the time the query is performed. These tables do not display the information of the completed transactions. If there is a large number of concurrent transactions, the result set of the query might also be large. You can use the limit clause or the where clause to filter transactions with a long lock-waiting time. Note that when you join multiple tables in Lock View, the data in different tables might not be obtained at the same time, so the information in different tables might not be consistent.
For example, to filter transactions with a long lock-waiting time using the where clause, you can execute the following SQL statement:
select trx.* from information_schema.data_lock_waits as l left join information_schema.tidb_trx as trx on l.trx_id = trx.id where l.key = "7480000000000000415F728000000000000001"\G
The following is an example output:
*************************** 1. row ***************************
ID: 426831815660273668
START_TIME: 2021-08-06 07:16:00.081000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
CURRENT_SQL_DIGEST_TEXT: update `t` set `v` = `v` + ? where `id` = ? ;
STATE: LockWaiting
WAITING_START_TIME: 2021-08-06 07:16:00.087720
MEM_BUFFER_KEYS: 0
MEM_BUFFER_BYTES: 0
SESSION_ID: 77
USER: root
DB: test
ALL_SQL_DIGESTS: ["0fdc781f19da1c6078c9de7eadef8a307889c001e05f107847bee4cfc8f3cdf3","06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7"]
*************************** 2. row ***************************
ID: 426831818019569665
START_TIME: 2021-08-06 07:16:09.081000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
CURRENT_SQL_DIGEST_TEXT: update `t` set `v` = `v` + ? where `id` = ? ;
STATE: LockWaiting
WAITING_START_TIME: 2021-08-06 07:16:09.290271
MEM_BUFFER_KEYS: 0
MEM_BUFFER_BYTES: 0
SESSION_ID: 75
USER: root
DB: test
ALL_SQL_DIGESTS: ["0fdc781f19da1c6078c9de7eadef8a307889c001e05f107847bee4cfc8f3cdf3","06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7"]
2 rows in set (0.00 sec)
A transaction is blocked for a long time
If a transaction is known to be blocked by another transaction (or multiple transactions) and the start_ts (transaction ID) of the current transaction is known, you can use the following method to obtain the information of the blocking transaction. Note that when you join multiple tables in Lock View, the data in different tables might not be obtained at the same time, so the information in different tables might not be consistent.
select l.key, trx.*, tidb_decode_sql_digests(trx.all_sql_digests) as sqls from information_schema.data_lock_waits as l join information_schema.cluster_tidb_trx as trx on l.current_holding_trx_id = trx.id where l.trx_id = 426831965449355272\G
The following is an example output:
*************************** 1. row ***************************
key: 74800000000000004D5F728000000000000001
INSTANCE: 127.0.0.1:10080
ID: 426832040186609668
START_TIME: 2021-08-06 07:30:16.581000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
CURRENT_SQL_DIGEST_TEXT: update `t` set `v` = `v` + ? where `id` = ? ;
STATE: LockWaiting
WAITING_START_TIME: 2021-08-06 07:30:16.592763
MEM_BUFFER_KEYS: 1
MEM_BUFFER_BYTES: 19
SESSION_ID: 113
USER: root
DB: test
ALL_SQL_DIGESTS: ["0fdc781f19da1c6078c9de7eadef8a307889c001e05f107847bee4cfc8f3cdf3","a4e28cc182bdd18288e2a34180499b9404cd0ba07e3cc34b6b3be7b7c2de7fe9","06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7"]
sqls: ["begin ;","select * from `t` where `id` = ? for update ;","update `t` set `v` = `v` + ? where `id` = ? ;"]
1 row in set (0.01 sec)
In the above query, the TIDB_DECODE_SQL_DIGESTS function is used on the ALL_SQL_DIGESTS column of the CLUSTER_TIDB_TRX table. This function tries to convert this column (the value is a set of SQL digests) to the normalized SQL statements, which improves readability.
If the start_ts of the current transaction is unknown, you can try to find it out from the information in the TIDB_TRX / CLUSTER_TIDB_TRX table or in the PROCESSLIST / CLUSTER_PROCESSLIST table.
Troubleshoot optimistic lock conflicts
This section provides the solutions of common lock conflict issues in the optimistic transaction mode.
Read-write conflicts
As the TiDB server receives a read request from a client, it gets a globally unique and increasing timestamp at the physical time as the start_ts of the current transaction. The transaction needs to read the latest data before start_ts, that is, the target key of the latest commit_ts that is smaller than start_ts. When the transaction finds that the target key is locked by another transaction, and it cannot know which phase the other transaction is in, a read-write conflict happens. The diagram is as follows:
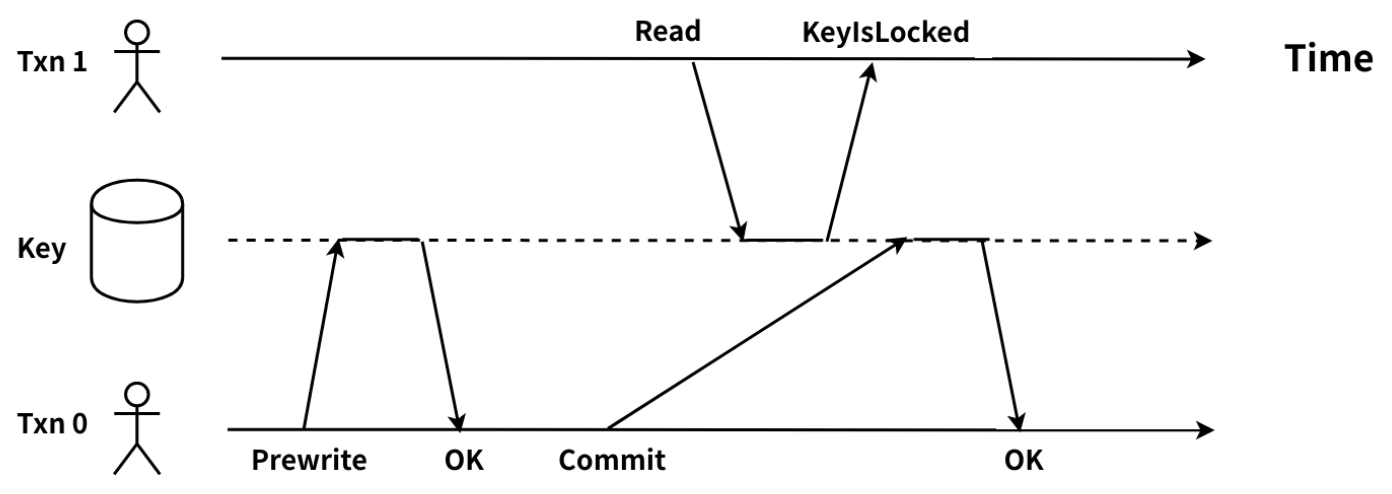
Txn0 completes the Prewrite phase and enters the Commit phase. At this time, Txn1 requests to read the same target key. Txn1 needs to read the target key of the latest commit_ts that is smaller than its start_ts. Because Txn1's start_ts is larger than Txn0's lock_ts, Txn1 must wait for the target key's lock to be cleared, but it hasn't been done. As a result, Txn1 cannot confirm whether Txn0 has been committed or not. Thus, a read-write conflict between Txn1 and Txn0 happens.
You can detect the read-write conflict in your TiDB cluster by the following ways:
Monitoring metrics and logs of the TiDB server
Monitoring data through Grafana
In the
KV Errorspanel in the TiDB dashboard,not_expired/resolveinLock Resolve OPSandtikvLockFastinKV Backoff OPSare monitoring metrics that can be used to check read-write conflicts in transactions. If the values of all the metrics increase, there might be many read-write conflicts. Thenot_expireditem means that the transaction's lock has not timed out. Theresolveitem means that the other transaction tries to clean up the locks. ThetikvLockFastitem means that read-write conflicts occur.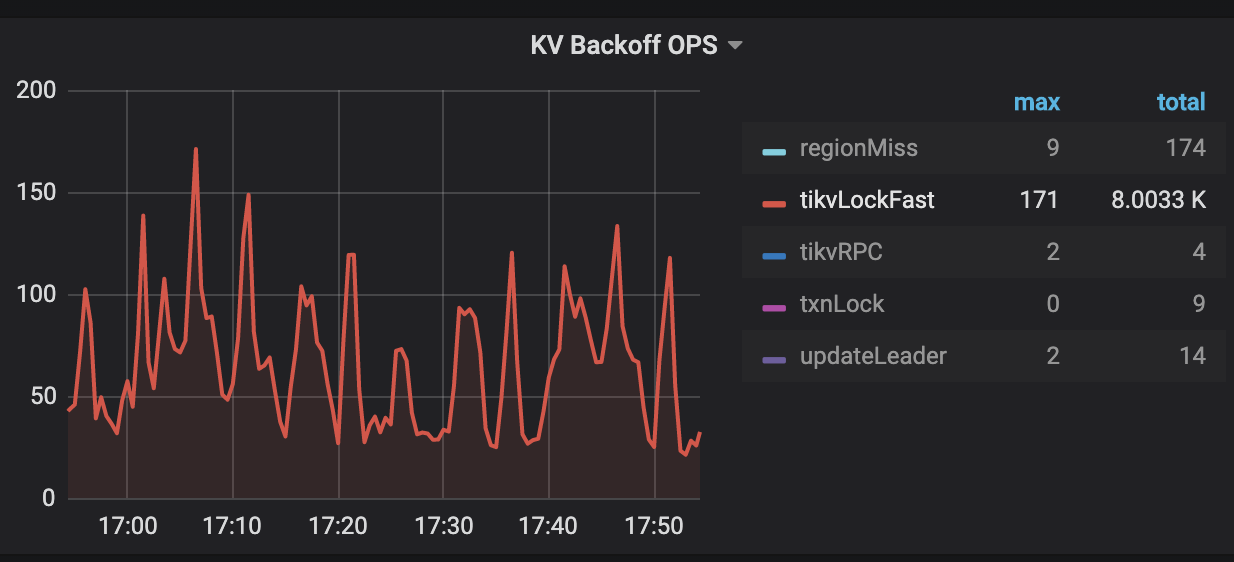
Logs of the TiDB server
If there is any read-write conflict, you can see the following message in the TiDB log:
[INFO] [coprocessor.go:743] ["[TIME_COP_PROCESS] resp_time:406.038899ms txnStartTS:416643508703592451 region_id:8297 store_addr:10.8.1.208:20160 backoff_ms:255 backoff_types:[txnLockFast,txnLockFast] kv_process_ms:333 scan_total_write:0 scan_processed_write:0 scan_total_data:0 scan_processed_data:0 scan_total_lock:0 scan_processed_lock:0"]- txnStartTS: The start_ts of the transaction that is sending the read request. In the above log,
416643508703592451is the start_ts. - backoff_types: If a read-write conflict happens, and the read request performs backoff and retry, the type of retry is
TxnLockFast. - backoff_ms: The time that the read request spends in the backoff and retry, and the unit is milliseconds. In the above log, the read request spends 255 milliseconds in the backoff and retry.
- region_id: Region ID corresponding to the target key of the read request.
- txnStartTS: The start_ts of the transaction that is sending the read request. In the above log,
Logs of the TiKV server
If there is any read-write conflict, you can see the following message in the TiKV log:
[ERROR] [endpoint.rs:454] [error-response] [err=""locked primary_lock:7480000000000004D35F6980000000000000010380000000004C788E0380000000004C0748 lock_version: 411402933858205712 key: 7480000000000004D35F7280000000004C0748 lock_ttl: 3008 txn_size: 1""]This message indicates that a read-write conflict occurs in TiDB. The target key of the read request has been locked by another transaction. The locks are from the uncommitted optimistic transaction and the uncommitted pessimistic transaction after the prewrite phase.
- primary_lock: Indicates that the target key is locked by the primary lock.
- lock_version: The start_ts of the transaction that owns the lock.
- key: The target key that is locked.
- lock_ttl: The lock's TTL (Time To Live)
- txn_size: The number of keys that are in the Region of the transaction that owns the lock.
Solutions:
A read-write conflict triggers an automatic backoff and retry. As in the above example, Txn1 has a backoff and retry. The first time of the retry is 10 ms, the longest retry is 3000 ms, and the total time is 20000 ms at maximum.
You can use the sub-command
decoderof TiDB Control to view the table id and rowid of the row corresponding to the specified key:./tidb-ctl decoder "t\x00\x00\x00\x00\x00\x00\x00\x1c_r\x00\x00\x00\x00\x00\x00\x00\xfa" format: table_row table_id: -9223372036854775780 row_id: -9223372036854775558
KeyIsLocked error
In the Prewrite phase of a transaction, TiDB checks whether there is any write-write conflict, and then checks whether the target key has been locked by another transaction. If the key is locked, the TiKV server outputs a "KeyIsLocked" error. At present, the error message is not printed in the logs of TiDB and TiKV. Same as read-write conflicts, when "KeyIsLocked" occurs, TiDB automatically performs backoff and retry for the transaction.
You can check whether there's any "KeyIsLocked" error in the TiDB monitoring on Grafana:
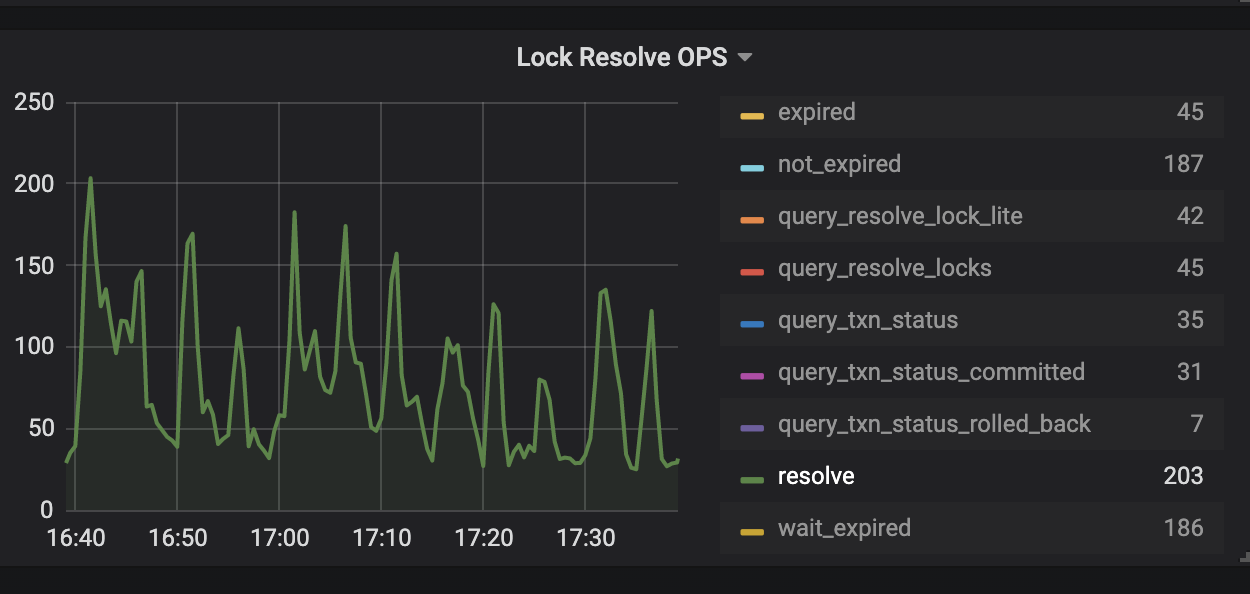
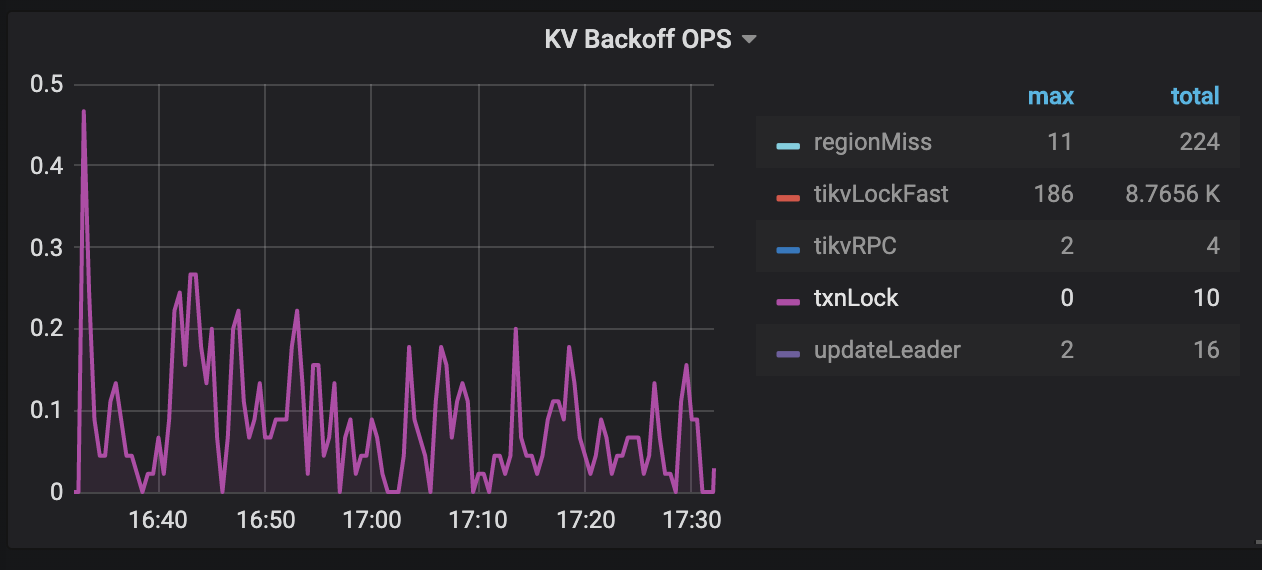
The KV Errors panel in the TiDB dashboard has two monitoring metrics Lock Resolve OPS and KV Backoff OPS which can be used to check write-write conflicts caused by a transaction. If the resolve item under Lock Resolve OPS and the txnLock item under KV Backoff OPS have a clear upward trend, a "KeyIsLocked" error occurs. resolve refers to the operation that attempts to clear the lock, and txnLock represents a write conflict.
Solutions:
- If there is a small amount of txnLock in the monitoring, no need to pay too much attention. The backoff and retry is automatically performed in the background. The first time of the retry is 100 ms and the maximum time is 3000 ms for a single retry.
- If there are too many "txnLock" operations in the
KV Backoff OPS, it is recommended that you analyze the reasons to the write conflicts from the application side. - If your application is a write-write conflict scenario, it is strongly recommended to use the pessimistic transaction mode.
LockNotFound error
The error log of "TxnLockNotFound" means that transaction commit time is longer than the TTL time, and when the transaction is going to commit, its lock has been rolled back by other transactions. If the TiDB server enables transaction commit retry, this transaction is re-executed according to tidb_retry_limit. (Note about the difference between explicit and implicit transactions.)
You can check whether there is any "LockNotFound" error in the following ways:
View the logs of the TiDB server
If a "TxnLockNotFound" error occurs, the TiDB log message is like this:
[WARN] [session.go:446] ["commit failed"] [conn=149370] ["finished txn"="Txn{state=invalid}"] [error="[kv:6]Error: KV error safe to retry tikv restarts txn: Txn(Mvcc(TxnLockNotFound{ start_ts: 412720515987275779, commit_ts: 412720519984971777, key: [116, 128, 0, 0, 0, 0, 1, 111, 16, 95, 114, 128, 0, 0, 0, 0, 0, 0, 2] })) [try again later]"]- start_ts: The start_ts of the transaction that outputs the
TxnLockNotFounderror because its lock has been rolled back by other transactions. In the above log,412720515987275779is the start_ts. - commit_ts: The commit_ts of the transaction that outputs the
TxnLockNotFounderror. In the above log,412720519984971777is the commit_ts.
- start_ts: The start_ts of the transaction that outputs the
View the logs of the TiKV server
If a "TxnLockNotFound" error occurs, the TiKV log message is like this:
Error: KV error safe to retry restarts txn: Txn(Mvcc(TxnLockNotFound)) [ERROR [Kv.rs:708] ["KvService::batch_raft send response fail"] [err=RemoteStoped]
Solutions:
By checking the time interval between start_ts and commit_ts, you can confirm whether the commit time exceeds the TTL time.
Checking the time interval using the PD control tool:
tiup ctl:v<CLUSTER_VERSION> pd tso [start_ts] tiup ctl:v<CLUSTER_VERSION> pd tso [commit_ts]It is recommended to check whether the write performance is slow, which might cause that the efficiency of transaction commit is poor, and thus the lock is cleared.
In the case of disabling the TiDB transaction retry, you need to catch the exception on the application side and try again.
Troubleshoot pessimistic lock conflicts
This section provides the solutions of common lock conflict issues in the pessimistic transaction mode.
Read-write conflicts
The error messages and solutions are the same as Read-write conflict for optimistic lock conflict.
Pessimistic lock retry limit reached
When the transaction conflict is very serious or a write conflict occurs, the optimistic transaction will be terminated directly, and the pessimistic transaction will retry the statement with the latest data from storage until there is no write conflict.
Because TiDB's locking operation is a write operation, and the process of the operation is to read first and then write, there are two RPC requests. If a write conflict occurs in the middle of a transaction, TiDB will try again to lock the target keys, and each retry will be printed to the TiDB log. The number of retries is determined by pessimistic-txn.max-retry-count.
In the pessimistic transaction mode, if a write conflict occurs and the number of retries reaches the upper limit, an error message containing the following keywords appears in the TiDB log:
err="pessimistic lock retry limit reached"
Solutions:
- If the above error occurs frequently, it is recommended to adjust from the application side.
- If your business contains high concurrent locking on the same row (the same key) and encounters frequent conflicts, you can try to enable the system variable
tidb_pessimistic_txn_fair_locking. Note that enabling this variable might bring some cost of throughput reduction (average latency increase) for transactions with lock conflicts. For newly deployed clusters, this variable is enabled (ON) by default.
Lock wait timeout exceeded
In the pessimistic transaction mode, transactions wait for locks of each other. The timeout for waiting a lock is defined by the innodb_lock_wait_timeout parameter of TiDB. This is the maximum wait lock time at the SQL statement level, which is the expectation of a SQL statement Locking, but the lock has never been acquired. After this time, TiDB will not try to lock again and will return the corresponding error message to the client.
When a wait lock timeout occurs, the following error message will be returned to the client:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
Solutions:
- If the above error occurs frequently, it is recommended to adjust the application logic.
TTL manager has timed out
The transaction execution time cannot exceed the GC time limit. In addition, the TTL time of pessimistic transactions has an upper limit, whose default value is 1 hour. Therefore, a pessimistic transaction executed for more than 1 hour will fail to commit. This timeout threshold is controlled by the TiDB parameter performance.max-txn-ttl.
When the execution time of a pessimistic transaction exceeds the TTL time, the following error message occurs in the TiDB log:
TTL manager has timed out, pessimistic locks may expire, please commit or rollback this transaction
Solutions:
- First, confirm whether the application logic can be optimized. For example, large transactions may trigger TiDB's transaction size limit, which can be split into multiple small transactions.
- Also, you can adjust the related parameters properly to meet the application transaction logic.
Deadlock found when trying to get lock
Due to resource competition between two or more transactions, a deadlock occurs. If you do not handle it manually, transactions that block each other cannot be executed successfully and will wait for each other forever. To resolve dead locks, you need to manually terminate one of the transactions to resume other transaction requests.
When a pessimistic transaction has a deadlock, one of the transactions must be terminated to unlock the deadlock. The client will return the same Error 1213 error as in MySQL, for example:
[err="[executor:1213]Deadlock found when trying to get lock; try restarting transaction"]
Solutions:
- If it is difficult to confirm the cause of the deadlock, for v5.1 and later versions, you are recommended to try to query the
INFORMATION_SCHEMA.DEADLOCKSorINFORMATION_SCHEMA.CLUSTER_DEADLOCKSsystem table to get the information of deadlock waiting chain. For details, see the Deadlock errors section and theDEADLOCKStable document. - If the deadlock occurs frequently, you need to adjust the transaction query logic in your application to reduce such occurrences.