TiDB Backend Task Distributed Execution Framework
TiDB adopts a computing-storage separation architecture with excellent scalability and elasticity. Starting from v7.1.0, TiDB introduces a backend task distributed execution framework to further leverage the resource advantages of the distributed architecture. The goal of this framework is to implement unified scheduling and distributed execution of all backend tasks, and to provide unified resource management capabilities for both overall and individual backend tasks, which better meets users' expectations for resource usage.
This document describes the use cases, limitations, usage, and implementation principles of the TiDB backend task distributed execution framework.
Use cases and limitations
In a database management system, in addition to the core transactional processing (TP) and analytical processing (AP) workloads, there are other important tasks, such as DDL operations, IMPORT INTO, TTL, Analyze, and Backup/Restore, which are called backend tasks. These backend tasks need to process a large amount of data in database objects (tables), so they typically have the following characteristics:
- Need to process all data in a schema or a database object (table).
- Might need to be executed periodically, but at a low frequency.
- If the resources are not properly controlled, they are prone to affect TP and AP tasks, lowering the database service quality.
Enabling the TiDB backend task distributed execution framework can solve the above problems and has the following three advantages:
- The framework provides unified capabilities for high scalability, high availability, and high performance.
- The framework supports distributed execution of backend tasks, which can flexibly schedule the available computing resources of the entire TiDB cluster, thereby better utilizing the computing resources in a TiDB cluster.
- The framework provides unified resource usage and management capabilities for both overall and individual backend tasks.
Currently, for TiDB Self-Hosted, the TiDB backend task distributed execution framework supports the distributed execution of the ADD INDEX and IMPORT INTO statements. For TiDB Cloud, the IMPORT INTO statement is not applicable.
ADD INDEXis a DDL statement used to create indexes. For example:ALTER TABLE t1 ADD INDEX idx1(c1); CREATE INDEX idx1 ON table t1(c1);IMPORT INTOis used to import data in formats such asCSV,SQL, andPARQUETinto an empty table. For more information, seeIMPORT INTO.
Limitation
- The DXF can only schedule the distributed execution of one
ADD INDEXtask at a time. If a newADD INDEXtask is submitted before the currentADD INDEXdistributed task has finished, the new task is executed through a transaction. - Adding indexes on columns with the
TIMESTAMPdata type through the DXF is not supported, because it might lead to inconsistency between the index and the data.
Prerequisites
Before using the distributed framework, you need to enable the Fast Online DDL mode.
Adjust the following system variables related to Fast Online DDL:
tidb_ddl_enable_fast_reorg: used to enable Fast Online DDL mode. It is enabled by default starting from TiDB v6.5.0.tidb_ddl_disk_quota: used to control the maximum quota of local disks that can be used in Fast Online DDL mode.
Adjust the following configuration item related to Fast Online DDL:
temp-dir: specifies the local disk path that can be used in Fast Online DDL mode.
Usage
To enable the distributed framework, set the value of
tidb_enable_dist_tasktoON:SET GLOBAL tidb_enable_dist_task = ON;When background tasks are running, the statements supported by the framework (such as
ADD INDEXandIMPORT INTO) are executed in a distributed manner. All TiDB nodes run background tasks by default.Adjust the following system variables that might affect the distributed execution of DDL tasks according to your needs:
tidb_ddl_reorg_worker_cnt: use the default value4. The recommended maximum value is16.tidb_ddl_reorg_prioritytidb_ddl_error_count_limittidb_ddl_reorg_batch_size: use the default value. The recommended maximum value is1024.
Starting from v7.4.0, you can adjust the number of TiDB nodes that perform background tasks according to actual needs. After deploying a TiDB cluster, you can set the instance-level system variable
tidb_service_scopefor each TiDB node in the cluster. Whentidb_service_scopeof a TiDB node is set tobackground, the TiDB node can execute background tasks. Whentidb_service_scopeof a TiDB node is set to the default value "", the TiDB node cannot execute background tasks. Iftidb_service_scopeis not set for any TiDB node in a cluster, the TiDB distributed execution framework schedules all TiDB nodes to execute background tasks by default.
Implementation principles
The architecture of the TiDB backend task distributed execution framework is as follows:
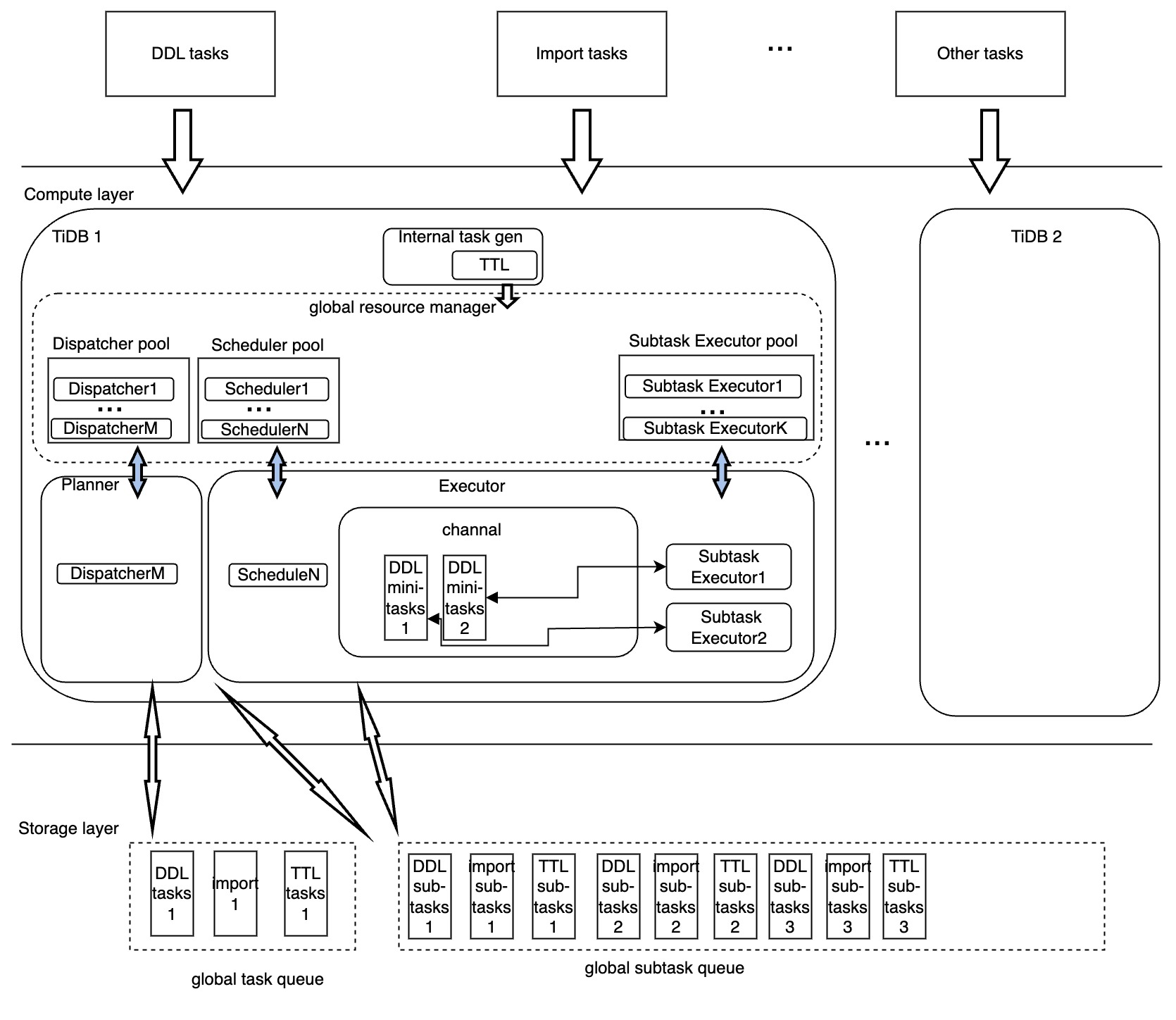
As shown in the preceding diagram, the execution of backend tasks in the distributed framework is mainly handled by the following modules:
- Dispatcher: generates the distributed execution plan for each task, manages the execution process, converts the task status, and collects and feeds back the runtime task information.
- Scheduler: replicates the execution of distributed tasks among TiDB nodes to improve the efficiency of backend task execution.
- Subtask Executor: the actual executor of distributed subtasks. In addition, the Subtask Executor returns the execution status of subtasks to the Scheduler, and the Scheduler updates the execution status of subtasks in a unified manner.
- Resource pool: provides the basis for quantifying resource usage and management by pooling computing resources of the above modules.