Guide for Developing a Storage Sink Consumer
This document describes how to design and implement a TiDB data change consumer.
TiCDC does not provide any standard way for implementing a consumer. This document provides a consumer example program written in Golang. This program can read data from the storage service and write the data to a MySQL-compatible database. You can refer to the data format and instructions provided in this example to implement a consumer on your own.
Consumer program written in Golang
Design a consumer
The following diagram shows the overall consumption process of the consumer:
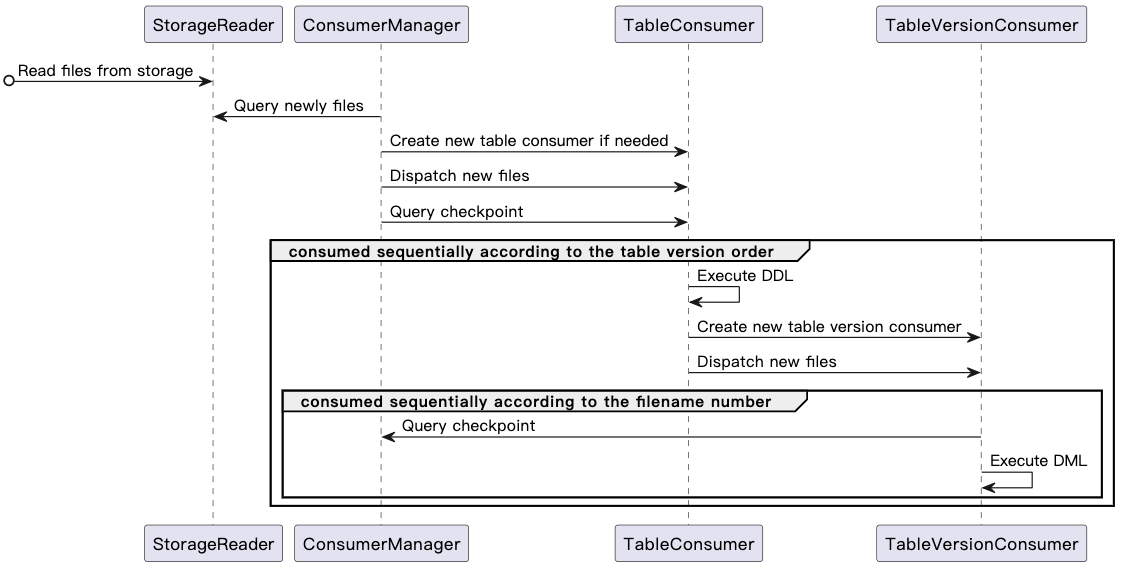
The components of the consumer and their features are described as follows:
type StorageReader struct {
}
// Read the files from storage.
// Add new files and delete files that do not exist in storage.
func (c *StorageReader) ReadFiles() {}
// Query newly added files and the latest checkpoint from storage. One file can only be returned once.
func (c *StorageReader) ExposeNewFiles() (int64, []string) {}
// ConsumerManager is responsible for assigning tasks to TableConsumer.
// Different consumers can consume data concurrently,
// but data of one table must be processed by the same TableConsumer.
type ConsumerManager struct {
// StorageCheckpoint is recorded in the metadata file, and it can be fetched by calling `StorageReader.ExposeNewFiles()`.
// This checkpoint indicates that the data whose transaction commit time is less than this checkpoint has been stored in storage.
StorageCheckpoint int64
// This checkpoint indicates where the consumer has consumed.
// ConsumerManager periodically collects TableConsumer.Checkpoint,
// then Checkpoint is updated to the minimum value of all TableConsumer.Checkpoint.
Checkpoint int64
tableFiles[schema][table]*TableConsumer
}
// Query newly added files from StorageReader.
// For a newly created table, create a TableConsumer for it.
// If any, send new files to the corresponding TableConsumer.
func (c *ConsumerManager) Dispatch() {}
type TableConsumer struct {
// This checkpoint indicates where this TableConsumer has consumed.
// Its initial value is ConsumerManager.Checkpoint.
// TableConsumer.Checkpoint is equal to TableVersionConsumer.Checkpoint.
Checkpoint int64
schema,table string
// Must be consumed sequentially according to the order of table versions.
verConsumers map[version int64]*TableVersionConsumer
currentVer, previousVer int64
}
// Send newly added files to the corresponding TableVersionConsumer.
// For any DDL, assign a TableVersionConsumer for the new table version.
func (tc *TableConsumer) Dispatch() {}
// If DDL query is empty or its tableVersion is less than TableConsumer.Checkpoint,
// - ignore this DDL, and consume the data under the table version.
// Otherwise,
// - execute the DDL first, and then consume the data under the table version.
// - For tables that are dropped, auto-recycling is performed after the drop table DDL is executed.
func (tc *TableConsumer) ExecuteDDL() {}
type TableVersionConsumer struct {
// This checkpoint indicates where the TableVersionConsumer has consumed.
// Its initial value is TableConsumer.Checkpoint.
Checkpoint int64
schema,table,version string
// For the same table version, data in different partitions can be consumed concurrently.
# partitionNum int64
// Must be consumed sequentially according to the data file number.
fileSet map[filename string]*TableVersionConsumer
currentVersion
}
// If data commit ts is less than TableConsumer.Checkpoint
// or bigger than ConsumerManager.StorageCheckpoint,
// - ignore this data.
// Otherwise,
// - process this data and write it to MySQL.
func (tc *TableVersionConsumer) ExecuteDML() {}
Process DDL events
The consumer traverses the directory for the first time. The following is an example:
├── metadata
└── test
├── tbl_1
│ └── 437752935075545091
│ ├── CDC000001.json
│ └── schema.json
The consumer parses the table schema of the schema.json file and obtains the DDL Query statements:
- If no Query statement is found or
TableVersionis less than the consumer checkpoint, the consumer skips this statement. - If Query statements exist or
TableVersionis equal to or greater than the consumer checkpoint, the consumer executes the DDL statements in the downstream MySQL.
Then the consumer starts replicating the CDC000001.json file.
In the following example, the DDL Query statement in the test/tbl_1/437752935075545091/schema.json file is not empty:
{
"Table":"test",
"Schema":"tbl_1",
"Version": 1,
"TableVersion":437752935075545091,
"Query": "create table tbl_1 (Id int primary key, LastName char(20), FirstName varchar(30), HireDate datetime, OfficeLocation Blob(20))",
"TableColumns":[
{
"ColumnName":"Id",
"ColumnType":"INT",
"ColumnNullable":"false",
"ColumnIsPk":"true"
},
{
"ColumnName":"LastName",
"ColumnType":"CHAR",
"ColumnLength":"20"
},
{
"ColumnName":"FirstName",
"ColumnType":"VARCHAR",
"ColumnLength":"30"
},
{
"ColumnName":"HireDate",
"ColumnType":"DATETIME"
},
{
"ColumnName":"OfficeLocation",
"ColumnType":"BLOB",
"ColumnLength":"20"
}
],
"TableColumnsTotal":"5"
}
When the consumer traverses the directory again, it finds a new version directory of the table. Note that the consumer can consume data in the new directory only after all files in the test/tbl_1/437752935075545091 directory have been consumed.
├── metadata
└── test
├── tbl_1
│ ├── 437752935075545091
│ │ ├── CDC000001.json
│ │ └── schema.json
│ └── 437752935075546092
│ │ └── CDC000001.json
│ │ └── schema.json
The consumption logic is consistent. Specifically, the consumer parses the table schema of the schema.json file and obtains and processes DDL Query statements accordingly. Then the consumer starts replicating the CDC000001.json file.
Process DML events
After DDL events are properly processed, you can process DML events in the {schema}/{table}/{table-version-separator}/ directory based on the specific file format (CSV or Canal-JSON) and file number.
TiCDC ensures that data is replicated at least once. Therefore, there might be duplicate data. You need to compare the commit ts of the change data with the consumer checkpoint. If the commit ts is less than the consumer checkpoint, you need to perform deduplication.