Periodically Delete Expired Data Using TTL (Time to Live)
Time to live (TTL) is a feature that allows you to manage TiDB data lifetime at the row level. For a table with the TTL attribute, TiDB automatically checks data lifetime and deletes expired data at the row level. This feature can effectively save storage space and enhance performance in some scenarios.
The following are some common scenarios for TTL:
- Regularly delete verification codes and short URLs.
- Regularly delete unnecessary historical orders.
- Automatically delete intermediate results of calculations.
TTL is designed to help users clean up unnecessary data periodically and in a timely manner without affecting the online read and write workloads. TTL concurrently dispatches different jobs to different TiDB nodes to delete data in parallel in the unit of table. TTL does not guarantee that all expired data is deleted immediately, which means that even if some data is expired, the client might still read that data some time after the expiration time until that data is deleted by the background TTL job.
Syntax
You can configure the TTL attribute of a table using the CREATE TABLE or ALTER TABLE statement.
Create a table with a TTL attribute
Create a table with a TTL attribute:
CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP ) TTL = `created_at` + INTERVAL 3 MONTH;The preceding example creates a table
t1and specifiescreated_atas the TTL timestamp column, which indicates the creation time of the data. The example also sets the longest time that a row is allowed to live in the table to 3 months throughINTERVAL 3 MONTH. Data that lives longer than this value will be deleted later.Set the
TTL_ENABLEattribute to enable or disable the feature of cleaning up expired data:CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP ) TTL = `created_at` + INTERVAL 3 MONTH TTL_ENABLE = 'OFF';If
TTL_ENABLEis set toOFF, even if other TTL options are set, TiDB does not automatically clean up expired data in this table. For a table with the TTL attribute,TTL_ENABLEisONby default.To be compatible with MySQL, you can set a TTL attribute using a comment:
CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP ) /*T![ttl] TTL = `created_at` + INTERVAL 3 MONTH TTL_ENABLE = 'OFF'*/;In TiDB, using the table TTL attribute or using comments to configure TTL is equivalent. In MySQL, the comment is ignored and an ordinary table is created.
Modify the TTL attribute of a table
Modify the TTL attribute of a table:
ALTER TABLE t1 TTL = `created_at` + INTERVAL 1 MONTH;You can use the preceding statement to modify a table with an existing TTL attribute or to add a TTL attribute to a table without a TTL attribute.
Modify the value of
TTL_ENABLEfor a table with the TTL attribute:ALTER TABLE t1 TTL_ENABLE = 'OFF';To remove all TTL attributes of a table:
ALTER TABLE t1 REMOVE TTL;
TTL and the default values of data types
You can use TTL together with default values of the data types. The following are two common usage examples:
Use
DEFAULT CURRENT_TIMESTAMPto specify the default value of a column as the current creation time and use this column as the TTL timestamp column. Records that were created 3 months ago are expired:CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) TTL = `created_at` + INTERVAL 3 MONTH;Specify the default value of a column as the creation time or the latest update time and use this column as the TTL timestamp column. Records that have not been updated for 3 months are expired:
CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) TTL = `created_at` + INTERVAL 3 MONTH;
TTL and generated columns
You can use TTL together with generated columns (experimental feature) to configure complex expiration rules. For example:
CREATE TABLE message (
id int PRIMARY KEY,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
image bool,
expire_at TIMESTAMP AS (IF(image,
created_at + INTERVAL 5 DAY,
created_at + INTERVAL 30 DAY
))
) TTL = `expire_at` + INTERVAL 0 DAY;
The preceding statement uses the expire_at column as the TTL timestamp column and sets the expiration time according to the message type. If the message is an image, it expires in 5 days. Otherwise, it expires in 30 days.
You can use TTL together with the JSON type. For example:
CREATE TABLE orders (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
order_info JSON,
created_at DATE AS (JSON_EXTRACT(order_info, '$.created_at')) VIRTUAL
) TTL = `created_at` + INTERVAL 3 month;
TTL job
For each table with a TTL attribute, TiDB internally schedules a background job to clean up expired data. You can customize the execution period of these jobs by setting the TTL_JOB_INTERVAL attribute for the table. The following example sets the background cleanup jobs for the table orders to run once every 24 hours:
ALTER TABLE orders TTL_JOB_INTERVAL = '24h';
TTL_JOB_INTERVAL is set to 1h by default.
When executing a TTL job, TiDB will split the table into up to 64 tasks, with the Region being the smallest unit. These tasks will be executed distributedly. You can limit the number of concurrent TTL tasks across the entire cluster by setting the system variable tidb_ttl_running_tasks. However, not all TTL jobs for all kinds of tables can be split into tasks. For more details on which kinds of tables' TTL jobs cannot be split into tasks, refer to the Limitations section.
To disable the execution of TTL jobs, in addition to setting the TTL_ENABLE='OFF' table option, you can also disable the execution of TTL jobs in the entire cluster by setting the tidb_ttl_job_enable global variable:
SET @@global.tidb_ttl_job_enable = OFF;
In some scenarios, you might want to allow TTL jobs to run only in a certain time window. In this case, you can set the tidb_ttl_job_schedule_window_start_time and tidb_ttl_job_schedule_window_end_time global variables to specify the time window. For example:
SET @@global.tidb_ttl_job_schedule_window_start_time = '01:00 +0000';
SET @@global.tidb_ttl_job_schedule_window_end_time = '05:00 +0000';
The preceding statement allows TTL jobs to be scheduled only between 1:00 and 5:00 UTC. By default, the time window is set to 00:00 +0000 to 23:59 +0000, which allows the jobs to be scheduled at any time.
Observability
TiDB collects runtime information about TTL periodically and provides visualized charts of these metrics in Grafana. You can see these metrics in the TiDB -> TTL panel in Grafana.
For details of the metrics, see the TTL section in TiDB Monitoring Metrics.
In addition, TiDB provides three tables to obtain more information about TTL jobs:
The
mysql.tidb_ttl_table_statustable contains information about the previously executed TTL job and ongoing TTL job for all TTL tablesMySQL [(none)]> SELECT * FROM mysql.tidb_ttl_table_status LIMIT 1\G; *************************** 1. row *************************** table_id: 85 parent_table_id: 85 table_statistics: NULL last_job_id: 0b4a6d50-3041-4664-9516-5525ee6d9f90 last_job_start_time: 2023-02-15 20:43:46 last_job_finish_time: 2023-02-15 20:44:46 last_job_ttl_expire: 2023-02-15 19:43:46 last_job_summary: {"total_rows":4369519,"success_rows":4369519,"error_rows":0,"total_scan_task":64,"scheduled_scan_task":64,"finished_scan_task":64} current_job_id: NULL current_job_owner_id: NULL current_job_owner_addr: NULL current_job_owner_hb_time: NULL current_job_start_time: NULL current_job_ttl_expire: NULL current_job_state: NULL current_job_status: NULL current_job_status_update_time: NULL 1 row in set (0.040 sec)The column
table_idis the ID of the partitioned table, and theparent_table_idis the ID of the table, corresponding with the ID ininfomation_schema.tables. If the table is not a partitioned table, the two IDs are the same.The columns
{last, current}_job_{start_time, finish_time, ttl_expire}describe respectively the start time, finish time, and expiration time used by the TTL job of the last or current execution. Thelast_job_summarycolumn describes the execution status of the last TTL task, including the total number of rows, the number of successful rows, and the number of failed rows.The
mysql.tidb_ttl_tasktable contains information about the ongoing TTL subtasks. A TTL job is split into many subtasks, and this table records the subtasks that are currently being executed.The
mysql.tidb_ttl_job_historytable contains information about the TTL jobs that have been executed. The record of TTL job history is kept for 90 days.MySQL [(none)]> SELECT * FROM mysql.tidb_ttl_job_history LIMIT 1\G; *************************** 1. row *************************** job_id: f221620c-ab84-4a28-9d24-b47ca2b5a301 table_id: 85 parent_table_id: 85 table_schema: test_schema table_name: TestTable partition_name: NULL create_time: 2023-02-15 17:43:46 finish_time: 2023-02-15 17:45:46 ttl_expire: 2023-02-15 16:43:46 summary_text: {"total_rows":9588419,"success_rows":9588419,"error_rows":0,"total_scan_task":63,"scheduled_scan_task":63,"finished_scan_task":63} expired_rows: 9588419 deleted_rows: 9588419 error_delete_rows: 0 status: finishedThe column
table_idis the ID of the partitioned table, and theparent_table_idis the ID of the table, corresponding with the ID ininfomation_schema.tables.table_schema,table_name, andpartition_namecorrespond to the database, table name, and partition name.create_time,finish_time, andttl_expireindicate the creation time, end time, and expiration time of the TTL task.expired_rowsanddeleted_rowsindicate the number of expired rows and the number of rows deleted successfully.
Compatibility with TiDB tools
TTL can be used with other TiDB migration, backup, and recovery tools.
Compatibility with SQL
Limitations
Currently, the TTL feature has the following limitations:
- The TTL attribute cannot be set on temporary tables, including local temporary tables and global temporary tables.
- A table with the TTL attribute does not support being referenced by other tables as the primary table in a foreign key constraint.
- It is not guaranteed that all expired data is deleted immediately. The time when expired data is deleted depends on the scheduling interval and scheduling window of the background cleanup job.
- For tables that use clustered indexes, if the primary key is neither an integer nor a binary string type, the TTL job cannot be split into multiple tasks. This will cause the TTL job to be executed sequentially on a single TiDB node. If the table contains a large amount of data, the execution of the TTL job might become slow.
- TTL is not available for TiDB Serverless.
FAQs
How can I determine whether the deletion is fast enough to keep the data size relatively stable?
In the Grafana
TiDBdashboard, the panelTTL Insert Rows Per Hourrecords the total number of rows inserted in the previous hour. The correspondingTTL Delete Rows Per Hourrecords the total number of rows deleted by the TTL task in the previous hour. IfTTL Insert Rows Per Houris higher thanTTL Delete Rows Per Hourfor a long time, it means that the rate of insertion is higher than the rate of deletion and the total amount of data will increase. For example:
It is worth noting that since TTL does not guarantee that the expired rows will be deleted immediately, and the rows currently inserted will be deleted in a future TTL task, even if the speed of TTL deletion is lower than the speed of insertion in a short period of time, it does not necessarily mean that the speed of TTL is too slow. You need to consider the situation in its context.
How can I determine whether the bottleneck of a TTL task is in scanning or deleting?
Look at the
TTL Scan Worker Time By PhaseandTTL Delete Worker Time By Phasepanels. If the scan worker is in thedispatchphase for a large percentage of time and the delete worker is rarely in theidlephase, then the scan worker is waiting for the delete worker to finish the deletion. If the cluster resources are still free at this point, you can consider increasingtidb_ttl_ delete_worker_countto increase the number of delete workers. For example: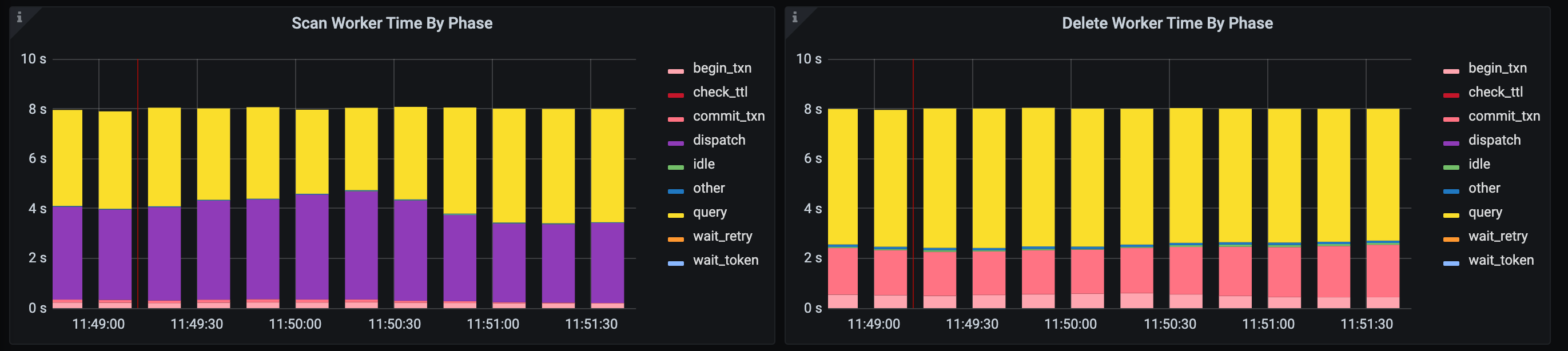
In contrast, if the scan worker is rarely in the
dispatchphase and the delete worker is in theidlephase for a long time, then the scan worker is relatively busy. For example:
The percentage of scan and delete in TTL jobs is related to the machine configuration and data distribution, so the monitoring data at each moment is only representative of the TTL Jobs being executed. You can read the table
mysql.tidb_ttl_job_historyto determine which TTL job is running at a certain moment and the corresponding table of the job.How to configure
tidb_ttl_scan_worker_countandtidb_ttl_delete_worker_countproperly?Refer to the question "How to determine whether the bottleneck of TTL tasks is in scanning or deleting?" to consider whether to increase the value of
tidb_ttl_scan_worker_countortidb_ttl_delete_worker_count.If the number of TiKV nodes is high, increase the value of
tidb_ttl_scan_worker_countcan make the TTL task workload more balanced.Since too many TTL workers will cause a lot of pressure, you need to evaluate the CPU level of TiDB and the disk and CPU usage of TiKV together. Depending on different scenarios and needs (whether you need to speed up TTL as much as possible, or to reduce the impact of TTL on other queries), you can adjust the value of
tidb_ttl_scan_worker_countandtidb_ttl_delete_worker_countto improve the speed of TTL scanning and deleting or reduce the performance impact brought by TTL tasks.