Three Availability Zones in Two Regions Deployment
This document introduces the architecture and configuration of the three availability zones (AZs) in two regions deployment.
The term "region" in this document refers to a geographic area, while the capitalized "Region" refers to a basic unit of data storage in TiKV. "AZ" refers to an isolated location within a region, and each region has multiple AZs. The solution described in this document also applies to the scenario where multiple data centers are located in a single city.
Overview
The architecture of three AZs in two regions is a highly available and disaster tolerant deployment solution that provides a production data AZ, a disaster recovery AZ in the same region, and a disaster recovery AZ in another region. In this mode, the three AZs in two regions are interconnected. If one AZ fails or suffers from a disaster, other AZs can still operate well and take over the key applications or all applications. Compared with the multi-AZ in one region deployment, this solution has the advantage of cross-region high availability and can survive region-level natural disasters.
The distributed database TiDB natively supports the three-AZ-in-two-region architecture by using the Raft algorithm, and guarantees the consistency and high availability of data within a database cluster. Because the network latency across AZs in the same region is relatively low, the application traffic can be dispatched to two AZs in the same region, and the traffic load can be shared by these two AZs by controlling the distribution of TiKV Region leaders and PD leaders.
Deployment architecture
This section takes the example of Seattle and San Francisco to explain the deployment mode of three AZs in two regions for the distributed database of TiDB.
In this example, two AZs (AZ1 and AZ2) are located in Seattle and another AZ (AZ3) is located in San Francisco. The network latency between AZ1 and AZ2 is lower than 3 milliseconds. The network latency between AZ3 and AZ1/AZ2 in Seattle is about 20 milliseconds (ISP dedicated network is used).
The architecture of the cluster deployment is as follows:
- The TiDB cluster is deployed to three AZs in two regions: AZ1 in Seattle, AZ2 in Seattle, and AZ3 in San Francisco.
- The cluster has five replicas, two in AZ1, two in AZ2, and one in AZ3. For the TiKV component, each rack has a label, which means that each rack has a replica.
- The Raft protocol is adopted to ensure consistency and high availability of data, which is transparent to users.
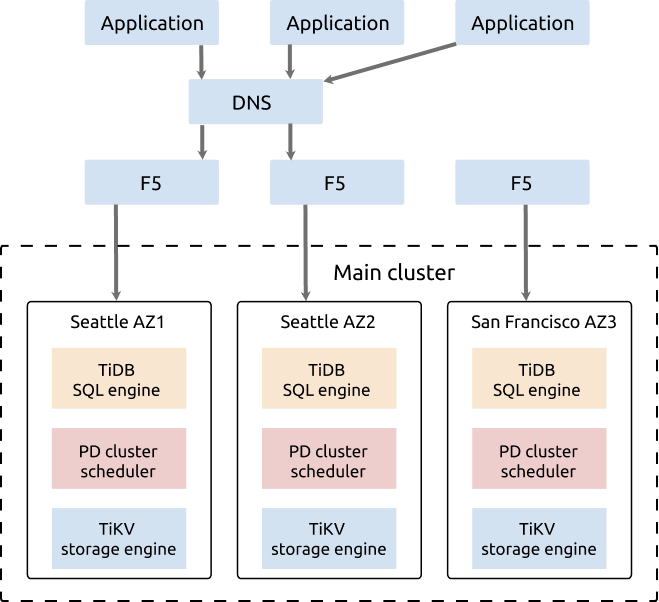
This architecture is highly available. The distribution of Region leaders is restricted to the two AZs (AZ1 and AZ2) that are in the same region (Seattle). Compared with the three-AZ solution in which the distribution of Region leaders is not restricted, this architecture has the following advantages and disadvantages:
Advantages
- Region leaders are in AZs of the same region with low latency, so the write is faster.
- The two AZs can provide services at the same time, so the resource usage rate is higher.
- If one AZ fails, services are still available and data safety is ensured.
Disadvantages
- Because the data consistency is achieved by the Raft algorithm, when two AZs in the same region fail at the same time, only one surviving replica remains in the disaster recovery AZ in another region (San Francisco). This cannot meet the requirement of the Raft algorithm that most replicas survive. As a result, the cluster can be temporarily unavailable. Maintenance staff needs to recover the cluster from the one surviving replica and a small amount of hot data that has not been replicated will be lost. But this case is a rare occurrence.
- Because the ISP dedicated network is used, the network infrastructure of this architecture has a high cost.
- Five replicas are configured in three AZs in two regions, data redundancy increases, which brings a higher storage cost.
Deployment details
The configuration of the three AZs in two regions (Seattle and San Francisco) deployment plan is illustrated as follows:
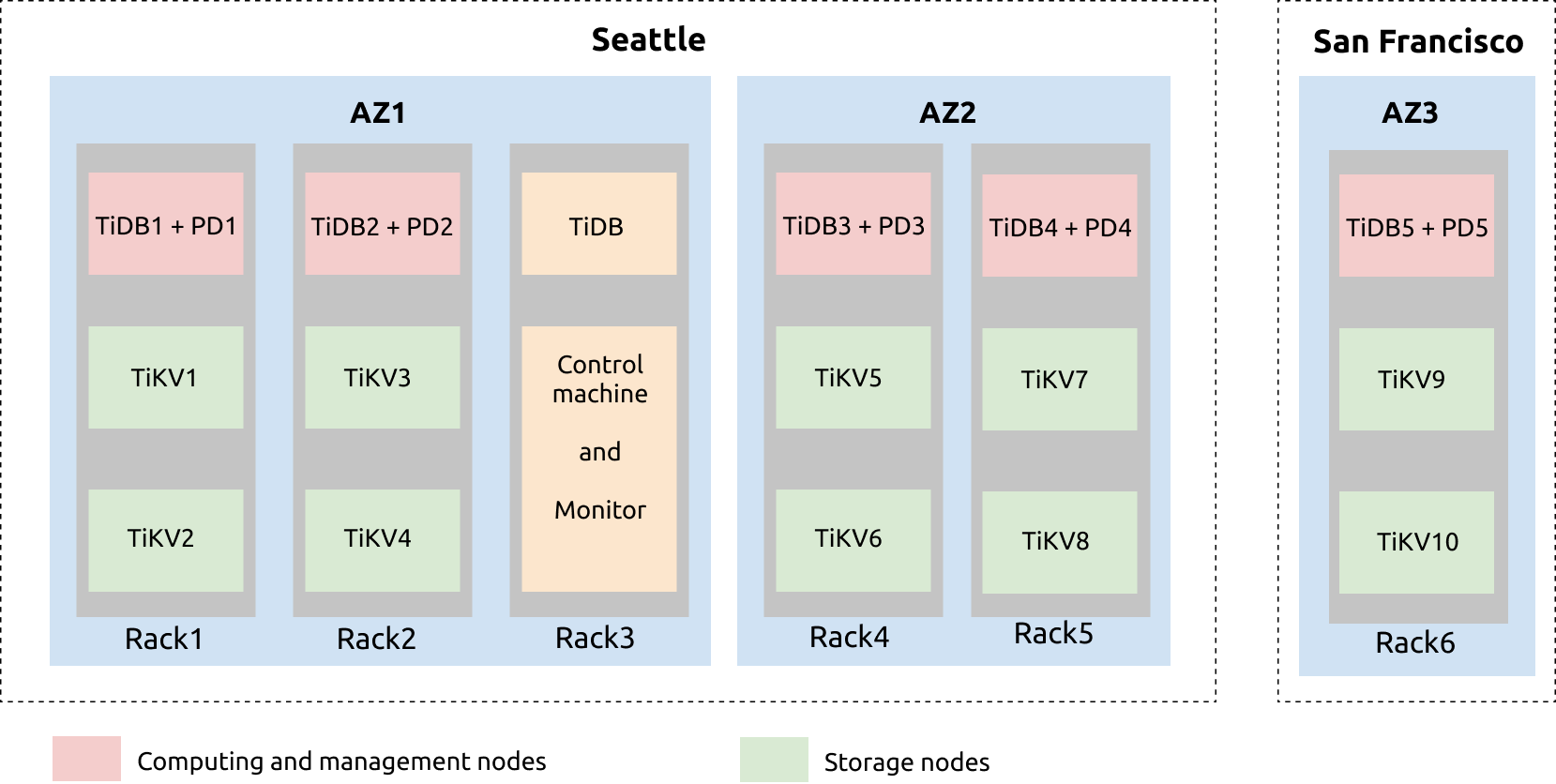
From the preceding illustration, you can see that Seattle has two AZs: AZ1 and AZ2. AZ1 has three sets of racks: rac1, rac2, and rac3. AZ2 has two racks: rac4 and rac5. The AZ3 in San Francisco has the rac6 rack.
In the rac1 of AZ1, one server is deployed with TiDB and PD services, and the other two servers are deployed with TiKV services. Each TiKV server is deployed with two TiKV instances (tikv-server). This is similar to rac2, rac4, rac5, and rac6.
The TiDB server, the control machine, and the monitoring server are on rac3. The TiDB server is deployed for regular maintenance and backup. Prometheus, Grafana, and the restore tools are deployed on the control machine and monitoring machine.
Another backup server can be added to deploy Drainer. Drainer saves binlog data to a specified location by outputting files, to achieve incremental backup.
Configuration
Example
See the following tiup topology.yaml yaml file for example:
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb_cluster/tidb-deploy"
data_dir: "/data/tidb_cluster/tidb-data"
server_configs:
tikv:
server.grpc-compression-type: gzip
pd:
replication.location-labels: ["az","replication zone","rack","host"]
pd_servers:
- host: 10.63.10.10
name: "pd-10"
- host: 10.63.10.11
name: "pd-11"
- host: 10.63.10.12
name: "pd-12"
- host: 10.63.10.13
name: "pd-13"
- host: 10.63.10.14
name: "pd-14"
tidb_servers:
- host: 10.63.10.10
- host: 10.63.10.11
- host: 10.63.10.12
- host: 10.63.10.13
- host: 10.63.10.14
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { az: "1", replication zone: "1", rack: "1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { az: "1", replication zone: "2", rack: "2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { az: "2", replication zone: "3", rack: "3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { az: "2", replication zone: "4", rack: "4", host: "33" }
- host: 10.63.10.34
config:
server.labels: { az: "3", replication zone: "5", rack: "5", host: "34" }
raftstore.raft-min-election-timeout-ticks: 1000
raftstore.raft-max-election-timeout-ticks: 1200
monitoring_servers:
- host: 10.63.10.60
grafana_servers:
- host: 10.63.10.60
alertmanager_servers:
- host: 10.63.10.60
Labels design
In the deployment of three AZs in two regions, the label design requires taking availability and disaster recovery into account. It is recommended that you define the four levels (az, replication zone, rack, and host) based on the physical structure of the deployment.
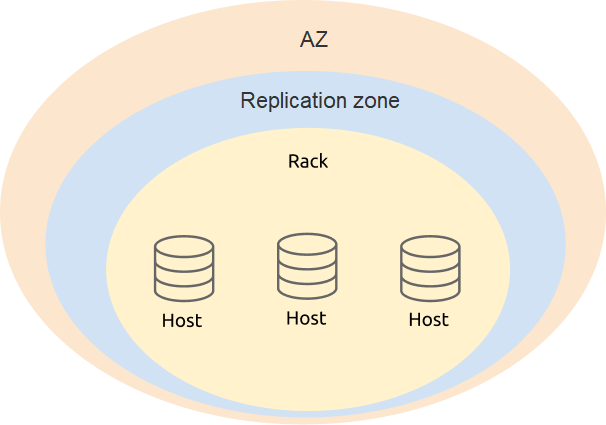
In the PD configuration, add level information of TiKV labels:
server_configs:
pd:
replication.location-labels: ["az","replication zone","rack","host"]
The configuration of tikv_servers is based on the label information of the real physical deployment location of TiKV, which makes it easier for PD to perform global management and scheduling.
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { az: "1", replication zone: "1", rack: "1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { az: "1", replication zone: "2", rack: "2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { az: "2", replication zone: "3", rack: "3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { az: "2", replication zone: "4", rack: "4", host: "33" }
- host: 10.63.10.34
config:
server.labels: { az: "3", replication zone: "5", rack: "5", host: "34" }
Optimize parameter configuration
In the deployment of three AZs in two regions, to optimize performance, you need to not only configure regular parameters, but also adjust component parameters.
Enable gRPC message compression in TiKV. Because data of the cluster is transmitted in the network, you can enable the gRPC message compression to lower the network traffic.
server.grpc-compression-type: gzipOptimize the network configuration of the TiKV node in another region (San Francisco). Modify the following TiKV parameters for AZ3 in San Francisco and try to prevent the replica in this TiKV node from participating in the Raft election.
raftstore.raft-min-election-timeout-ticks: 1000 raftstore.raft-max-election-timeout-ticks: 1200Configure scheduling. After the cluster is enabled, use the
tiup ctl:<cluster-version> pdtool to modify the scheduling policy. Modify the number of TiKV Raft replicas. Configure this number as planned. In this example, the number of replicas is five.config set max-replicas 5Forbid scheduling the Raft leader to AZ3. Scheduling the Raft leader to another region (AZ3) causes unnecessary network overhead between AZ1/AZ2 in Seattle and AZ3 in San Francisco. The network bandwidth and latency also affect the performance of the TiDB cluster.
config set label-property reject-leader dc 3Configure the priority of PD. To avoid the situation where the PD leader is in another region (AZ3), you can increase the priority of local PD (in Seattle) and decrease the priority of PD in another region (San Francisco). The larger the number, the higher the priority.
member leader_priority PD-10 5 member leader_priority PD-11 5 member leader_priority PD-12 5 member leader_priority PD-13 5 member leader_priority PD-14 1