TiDB Snapshot Backup and Restore Architecture
This document introduces the architecture and process of TiDB snapshot backup and restore using a Backup & Restore (BR) tool as an example.
Architecture
The TiDB snapshot backup and restore architecture is as follows:
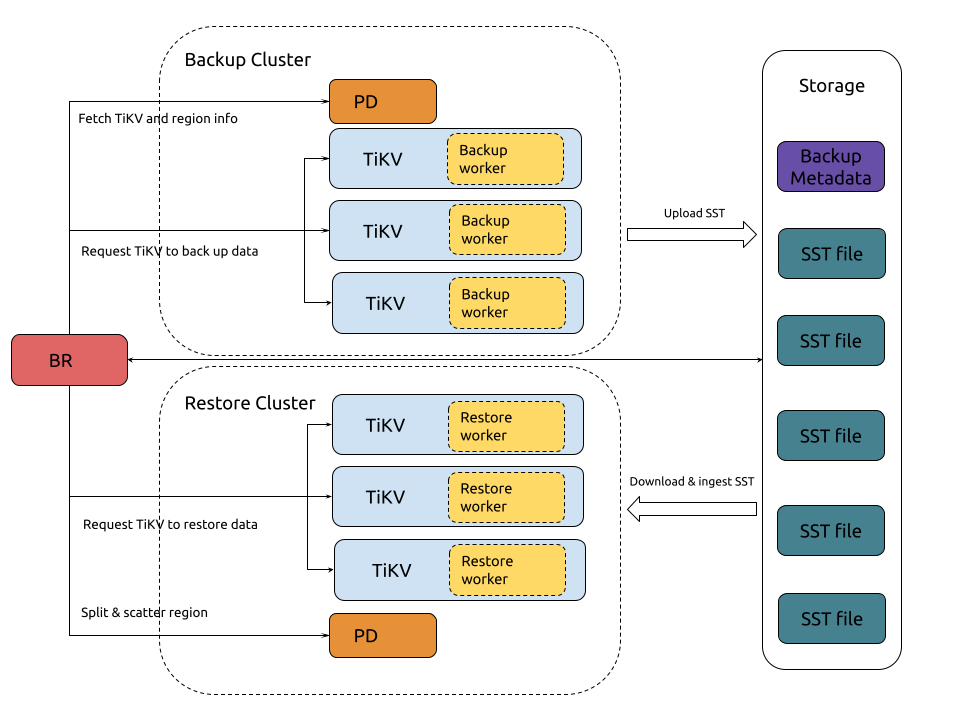
Process of backup
The process of a cluster snapshot backup is as follows:
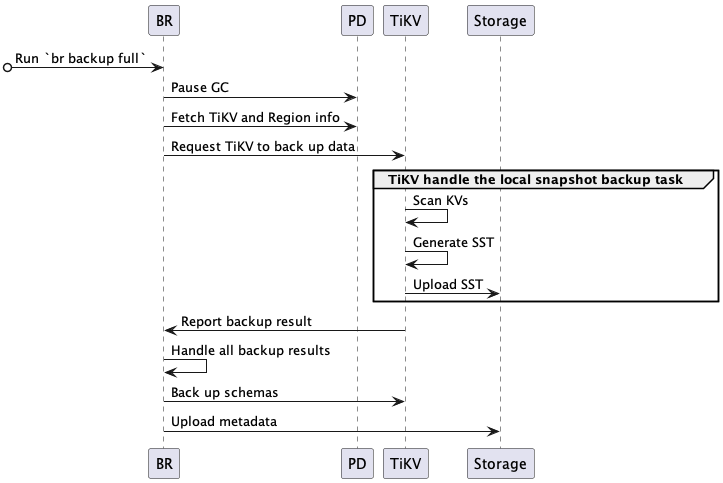
The complete backup process is as follows:
BR receives the
br backup fullcommand.- Gets the backup time point and storage path.
BR schedules the backup data.
- Pause GC: BR configures the TiDB GC time to prevent the backup data from being cleaned up by TiDB GC mechanism.
- Fetch TiKV and Region info: BR accesses PD to get all TiKV nodes addresses and Region distribution of data.
- Request TiKV to back up data: BR creates a backup request and sends it to all TiKV nodes. The backup request includes the backup time point, Regions to be backed up, and the storage path.
TiKV accepts the backup request and initiates a backup worker.
TiKV backs up the data.
- Scan KVs: the backup worker reads data corresponding to the backup time point from the Region where the leader locates.
- Generate SST: the backup worker saves the data to SST files, which are stored in the memory.
- Upload SST: the backup worker uploads the SST files to the storage path.
BR receives the backup result from each TiKV node.
- If some data fails to be backed up due to Region changes, for example, a TiKV node is down, BR will retry the backup.
- If there is any data fails to be backed up and cannot be retried, the backup task fails.
- After all data is backed up, BR will then back up the metadata.
BR backs up the metadata.
- Back up schemas: BR backs up the table schemas and calculates the checksum of the table data.
- Upload metadata: BR generates the backup metadata and uploads it to the storage path. The backup metadata includes the backup timestamp, the table and corresponding backup files, data checksum, and file checksum.
Process of restore
The process of a cluster snapshot restore is as follows:
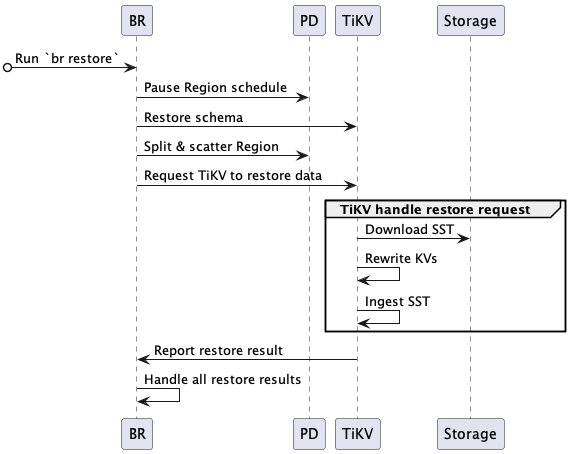
The complete restore process is as follows:
BR receives the
br restorecommand.- Gets the data storage path and the database or table to be restored.
- Checks whether the table to be restored exists and whether it meets the requirements for restore.
BR schedules the restore data.
- Pause Region schedule: BR requests PD to pause the automatic Region scheduling during restore.
- Restore schema: BR gets the schema of the backup data and the database and table to be restored. Note that the ID of a newly created table might be different from that of the backup data.
- Split & scatter Region: BR requests PD to allocate Regions (split Region) based on backup data, and schedules Regions to be evenly distributed to storage nodes (scatter Region). Each Region has a specified data range
[start key, end key). - Request TiKV to restore data: BR creates a restore request and sends it to the corresponding TiKV nodes according to the result of Region split. The restore request includes the data to be restored and rewrite rules.
TiKV accepts the restore request and initiates a restore worker.
- The restore worker calculates the backup data that needs to be read to restore.
TiKV restores the data.
- Download SST: the restore worker downloads corresponding SST files from the storage path to a local directory.
- Rewrite KVs: the restore worker rewrites the KV data according to the new table ID, that is, replace the original table ID in the Key-Value with the new table ID. The restore worker also rewrites the index ID in the same way.
- Ingest SST: the restore worker ingests the processed SST files into RocksDB.
- Report restore result: the restore worker reports the restore result to BR.
BR receives the restore result from each TiKV node.
- If some data fails to be restored due to
RegionNotFoundorEpochNotMatch, for example, a TiKV node is down, BR will retry the restore. - If there is any data fails to be restored and cannot be retried, the restore task fails.
- After all data is restored, the restore task succeeds.
- If some data fails to be restored due to
Backup files
Types of backup files
Snapshot backup generates the following types of files:
SSTfile: stores the data that the TiKV node backs up. The size of anSSTfile equals to that of a Region.backupmetafile: stores the metadata of a backup task, including the number of all backup files, and the key range, the size, and the Hash (sha256) value of each backup file.backup.lockfile: prevents multiple backup tasks from storing data at the same directory.
Naming format of SST files
When data is backed up to Google Cloud Storage (GCS) or Azure Blob Storage, SST files are named in the format of storeID_regionID_regionEpoch_keyHash_timestamp_cf. The fields in the name are explained as follows:
storeIDis the TiKV node ID.regionIDis the Region ID.regionEpochis the version number of Region.keyHashis the Hash (sha256) value of the startKey of a range, which ensures the uniqueness of a file.timestampis the Unix timestamp of an SST file when it is generated by TiKV.cfindicates the Column Family of RocksDB (only restores data whosecfisdefaultorwrite).
When data is backed up to Amazon S3 or a network disk, the SST files are named in the format of regionID_regionEpoch_keyHash_timestamp_cf. The fields in the name are explained as follows:
regionIDis the Region ID.regionEpochis the version number of Region.keyHashis the Hash (sha256) value of the startKey of a range, which ensures the uniqueness of a file.timestampis the Unix timestamp of an SST file when it is generated by TiKV.cfindicates the Column Family of RocksDB (only restores data whosecfisdefaultorwrite).
Storage format of SST files
- For details about the storage format of SST files, see RocksDB BlockBasedTable format.
- For details about the encoding format of backup data in SST files, see mapping of table data to Key-Value.
Structure of backup files
When you back up data to GCS or Azure Blob Storage, the SST files, backupmeta files, and backup.lock files are stored in the same directory as the following structure:
.
└── 20220621
├── backupmeta
|—— backup.lock
├── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
└── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
When you back up data to Amazon S3 or a network disk, the SST files are stored in sub-directories based on the storeID. The structure is as follows:
.
└── 20220621
├── backupmeta
|—— backup.lock
├── store1
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store100
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store2
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store3
├── store4
└── store5