TiDB Optimistic Transaction Model
This document introduces the principles of TiDB's optimistic transaction model. This document assumes that you have a basic understanding of TiDB architecture, Percolator, and the ACID properties of transactions.
In TiDB's optimistic transaction model, the two-phase commit begins right after the client executes the COMMIT statement. Therefore, the write-write conflict can be observed before the transactions are actually committed.
Principles of optimistic transactions
TiDB adopts Google's Percolator transaction model, a variant of two-phase commit (2PC) to ensure the correct completion of a distributed transaction. The procedure is as follows:
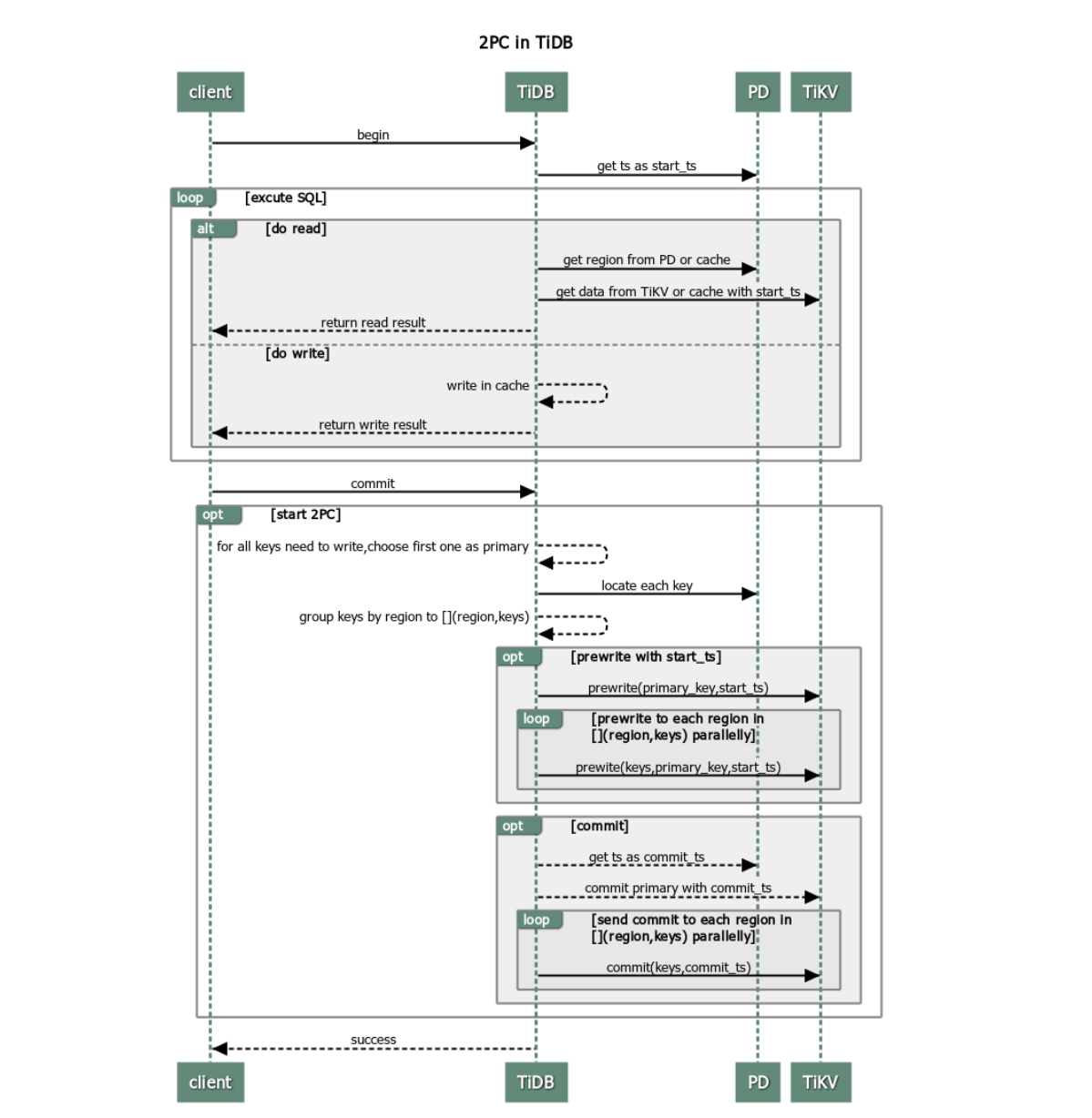
The client begins a transaction.
TiDB receives the start version number (monotonically increasing in time and globally unique) from PD and mark it as
start_ts.The client issues a read request.
- TiDB receives routing information (how data is distributed among TiKV nodes) from PD.
- TiDB receives the data of the
start_tsversion from TiKV.
The client issues a write request.
TiDB checks whether the written data satisfies consistency constraints (to ensure the data types are correct and the unique index is met etc.) Valid data is stored in the memory.
The client issues a commit request.
TiDB begins 2PC to ensure the atomicity of distributed transactions and persist data in store.
- TiDB selects a Primary Key from the data to be written.
- TiDB receives the information of Region distribution from PD, and groups all keys by Region accordingly.
- TiDB sends prewrite requests to all TiKV nodes involved. Then, TiKV checks whether there are conflict or expired versions. Valid data is locked.
- TiDB receives all responses in the prewrite phase and the prewrite is successful.
- TiDB receives a commit version number from PD and marks it as
commit_ts. - TiDB initiates the second commit to the TiKV node where Primary Key is located. TiKV checks the data, and clean the locks left in the prewrite phase.
- TiDB receives the message that reports the second phase is successfully finished.
TiDB returns a message to inform the client that the transaction is successfully committed.
TiDB asynchronously cleans the locks left in this transaction.
Advantages and disadvantages
From the process of transactions in TiDB above, it is clear that TiDB transactions have the following advantages:
- Simple to understand
- Implement cross-node transaction based on single-row transaction
- Decentralized lock management
However, TiDB transactions also have the following disadvantages:
- Transaction latency due to 2PC
- In need of a centralized version manager
- OOM (out of memory) when extensive data is written in the memory
To avoid potential problems in application, refer to transaction sizes to see more details.
Transaction retries
TiDB uses optimistic concurrency control by default whereas MySQL applies pessimistic concurrency control. This means that MySQL checks for conflicts during the execution of SQL statements, so there are few errors reported in heavy contention scenarios. For the convenience of MySQL users, TiDB provides a retry function that runs inside a transaction.
Automatic retry
If there is a conflict, TiDB retries the write operations automatically. You can set tidb_disable_txn_auto_retry and tidb_retry_limit to enable or disable this default function:
# Whether to disable automatic retry. ("on" by default)
tidb_disable_txn_auto_retry = off
# Set the maximum number of the retires. ("10" by default)
# When “tidb_retry_limit = 0”, automatic retry is completely disabled.
tidb_retry_limit = 10
You can enable the automatic retry in either session level or global level:
- Session level:
```sql
set @@tidb_disable_txn_auto_retry = off;
```
```sql
set @@tidb_retry_limit = 10;
```
- Global level:
```sql
set @@global.tidb_disable_txn_auto_retry = off;
```
```sql
set @@global.tidb_retry_limit = 10;
```
Limits of retry
By default, TiDB will not retry transactions because this might lead to lost updates and damaged REPEATABLE READ isolation.
The reason can be observed from the procedures of retry:
- Allocate a new timestamp and mark it as
start_ts. - Retry the SQL statements that contain write operations.
- Implement the two-phase commit.
In Step 2, TiDB only retries SQL statements that contain write operations. However, during retrying, TiDB receives a new version number to mark the beginning of the transaction. This means that TiDB retries SQL statements with the data in the new start_ts version. In this case, if the transaction updates data using other query results, the results might be inconsistent because the REPEATABLE READ isolation is violated.
If your application can tolerate lost updates, and does not require REPEATABLE READ isolation consistency, you can enable this feature by setting tidb_disable_txn_auto_retry = off.
Conflict detection
For the optimistic transaction, it is important to detect whether there are write-write conflicts in the underlying data. Although TiKV reads data for detection in the prewrite phase, a conflict pre-detection is also performed in the TiDB clusters to improve the efficiency.
Because TiDB is a distributed database, the conflict detection in the memory is performed in two layers:
- The TiDB layer. If a write-write conflict in the instance is observed after the primary write is issued, it is unnecessary to issue the subsequent writes to the TiKV layer.
- The TiKV layer. TiDB instances are unaware of each other, which means they cannot confirm whether there are conflicts or not. Therefore, the conflict detection is mainly performed in the TiKV layer.
The conflict detection in the TiDB layer is disabled by default. The specific configuration items are as follows:
[txn-local-latches]
# Whether to enable the latches for transactions. Recommended
# to use latches when there are many local transaction conflicts.
# ("false" by default)
enabled = false
# Controls the number of slots corresponding to Hash. ("204800" by default)
# It automatically adjusts upward to an exponential multiple of 2.
# Each slot occupies 32 Bytes of memory. If set too small,
# it might result in slower running speed and poor performance
# when data writing covers a relatively large range.
capacity = 2048000
The value of the capacity configuration item mainly affects the accuracy of conflict detection. During conflict detection, only the hash value of each key is stored in the memory. Because the probability of collision when hashing is closely related to the probability of misdetection, you can configure capacity to controls the number of slots and enhance the accuracy of conflict detection.
- The smaller the value of
capacity, the smaller the occupied memory and the greater the probability of misdetection. - The larger the value of
capacity, the larger the occupied memory and the smaller the probability of misdetection.
When you confirm that there is no write-write conflict in the upcoming transactions (such as importing data), it is recommended to disable the function of conflict detection.
TiKV also uses a similar mechanism to detect conflicts, but the conflict detection in the TiKV layer cannot be disabled. You can only configure scheduler-concurrency to control the number of slots that defined by the modulo operation:
# Controls the number of slots. ("2048000" by default)
scheduler-concurrency = 2048000
In addition, TiKV supports monitoring the time spent on waiting latches in scheduler.
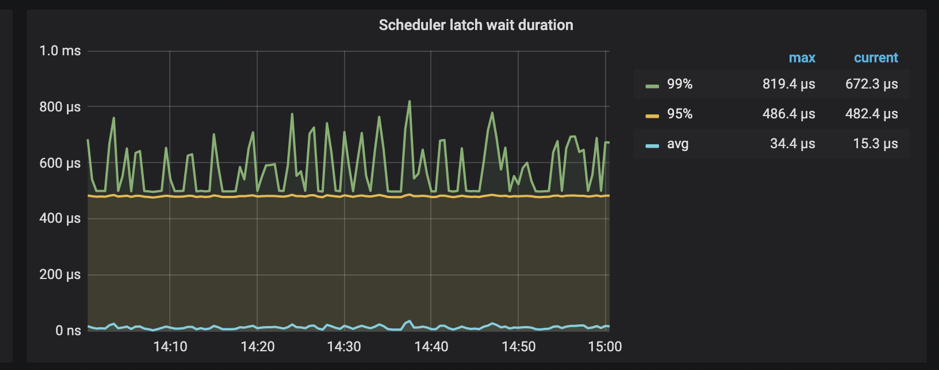
When Scheduler latch wait duration is high and there is no slow writes, it can be safely concluded that there are many write conflicts at this time.