TiDB Lightningの概要
TiDB Lightningは、TB 規模のデータを TiDB クラスターにインポートするために使用されるツールです。これは、TiDB クラスターへの初期データ インポートによく使用されます。
TiDB Lightningは、次のファイル形式をサポートしています。
- Dumplingによってエクスポートされたファイル
- CSVファイル
- Amazon Auroraによって生成された Apache Parquet ファイル
TiDB Lightningは、次のソースからデータを読み取ることができます。
TiDB Lightningアーキテクチャ
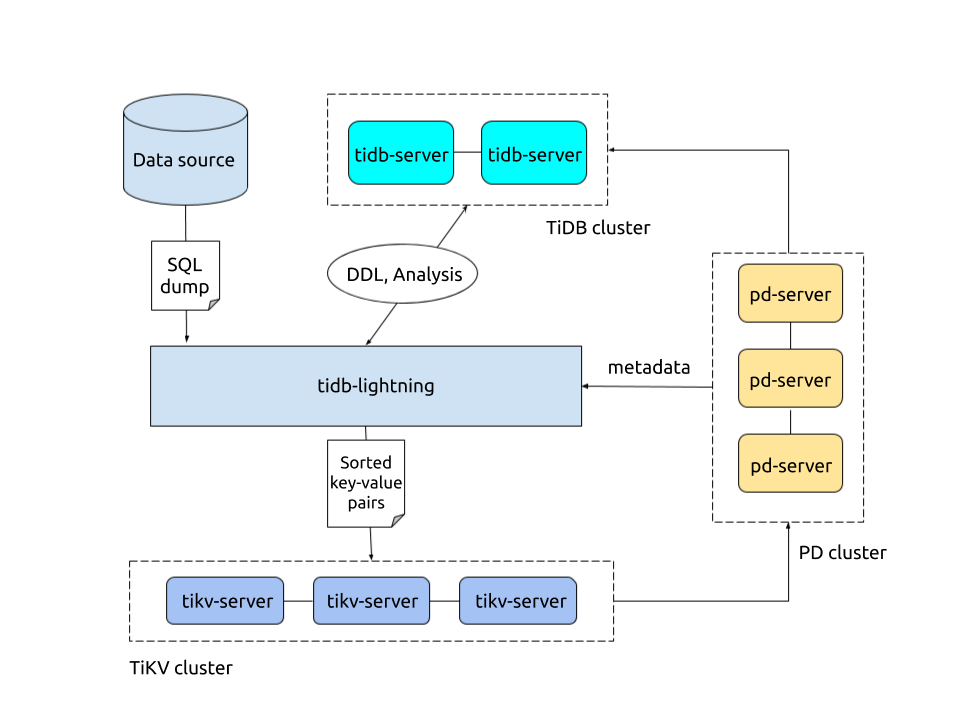
TiDB Lightningはbackendで設定される 2 つのインポート モードをサポートします。インポート モードは、データが TiDB にインポートされる方法を決定します。
物理インポート モード : TiDB Lightningは、最初にデータをキーと値のペアにエンコードしてローカルの一時ディレクトリに保存し、次にこれらのキーと値のペアを各 TiKV ノードにアップロードし、最後に TiKV 取り込みインターフェイスを呼び出してデータを TiKV の RocksDB に挿入します。初期インポートを実行する必要がある場合は、インポート速度が速い物理インポート モードを検討してください。
論理インポート モード : TiDB Lightningは最初にデータを SQL ステートメントにエンコードし、次にこれらの SQL ステートメントを直接実行してデータをインポートします。インポートするクラスタが本番環境にある場合、またはインポートするターゲット テーブルにすでにデータが含まれている場合は、論理インポート モードを使用します。
| インポート モード | 物理インポート モード | 論理インポート モード |
|---|---|---|
| スピード | 高速 (100~500 GiB/時) | 低 (10~50 GiB/時間) |
| リソース消費 | 高い | 低い |
| ネットワーク帯域幅の消費 | 高い | 低い |
| インポート中のACIDコンプライアンス | いいえ | はい |
| 対象テーブル | 空である必要があります | データを含めることができます |
| TiDB クラスターのバージョン | = 4.0.0 | 全て |
| インポート中に TiDB クラスターがサービスを提供できるかどうか | 限定サービス | はい |