TiDB性能チューニングの概要
このドキュメントでは、ユーザー応答時間、スループット、データベース時間などのパフォーマンス チューニングの基本概念を紹介し、パフォーマンス チューニングの一般的なプロセスについても説明します。
ユーザー応答時間とデータベース時間
ユーザー応答時間
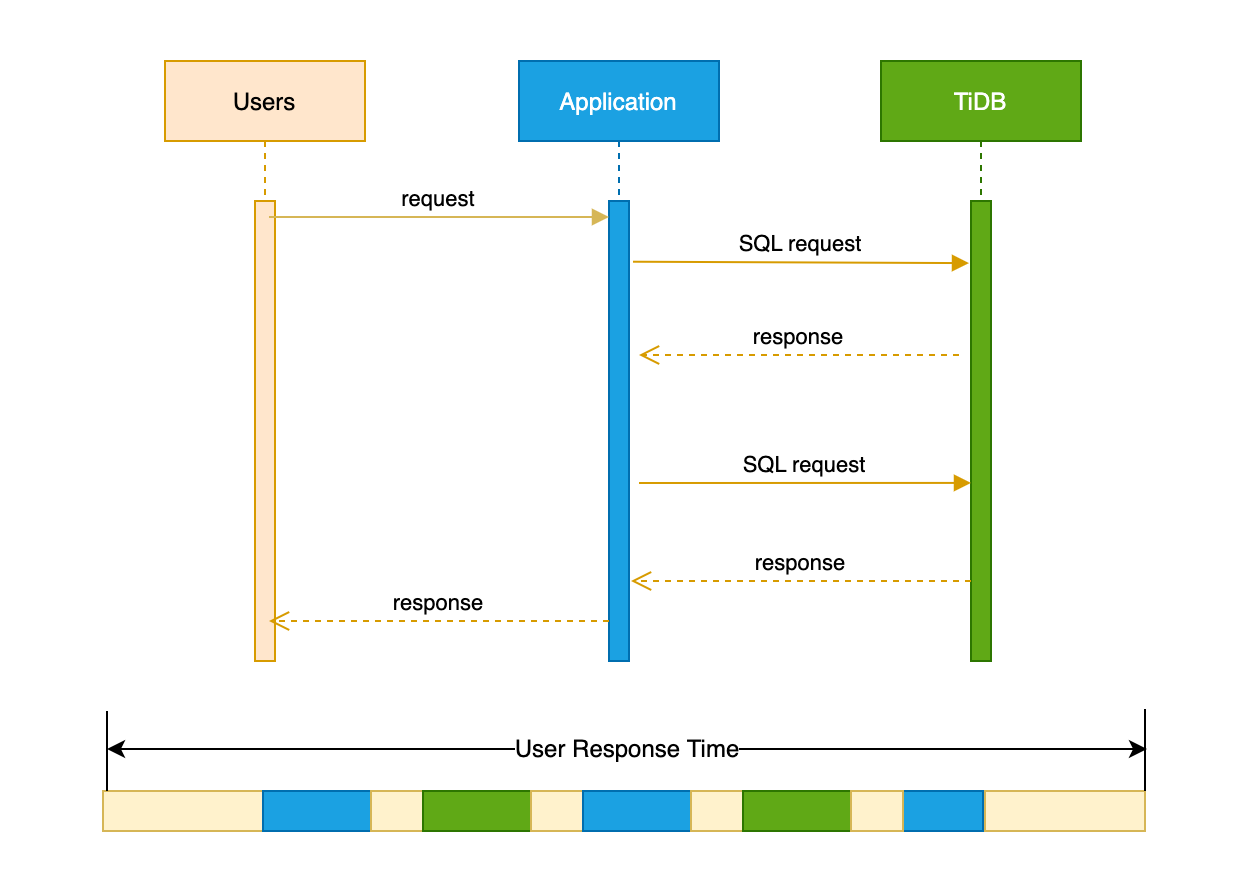
ユーザー応答時間は、アプリケーションが要求の結果をユーザーに返すのにかかる時間を示します。次の一連のタイミング図からわかるように、典型的なユーザー リクエストの時間には次のものが含まれます。
- ユーザーとアプリケーション間のネットワークレイテンシー
- アプリケーションの処理時間
- アプリケーションとデータベース間の対話中のネットワークレイテンシー
- データベースのサービス時間
ユーザーの応答時間は、ネットワークのレイテンシー時間と帯域幅、同時ユーザーの数と要求の種類、サーバーの CPU と I/O のリソース使用量など、要求チェーンのさまざまなサブシステムの影響を受けます。システム全体を効果的に最適化するには、まずユーザー応答時間のボトルネックを特定する必要があります。
指定した時間範囲 ( ΔT ) 内の合計ユーザー応答時間を取得するには、次の式を使用できます。
ΔTの合計ユーザー応答時間 = 平均 TPS (1 秒あたりのトランザクション) x 平均ユーザー応答時間 x ΔT .
データベース時間
データベース時間は、データベースによって提供される合計サービス時間を示します。 ΔTのデータベース時間は、データベースがすべてのアプリケーション要求を同時に処理するのにかかる時間の合計です。
データベース時間を取得するには、次のいずれかの方法を使用できます。
- 方法 1: 平均クエリレイテンシーに QPS と ΔT を掛ける、つまり
DB Time in ΔT = QPS × avg latency × ΔT - 方法 2: アクティブなセッションの平均数に ΔT、つまり
DB Time in ΔT = avg active connections × ΔTを掛けます。 - 方法 3: TiDB 内部 Prometheus メトリック TiDB_server_handle_query_duration_seconds_sum に基づいて時間を計算します。
ΔT DB Time = rate(TiDB_server_handle_query_duration_seconds_sum) × ΔT
ユーザー応答時間とシステム スループットの関係
ユーザー応答時間は、サービス時間、キューイング時間、およびユーザー要求を完了するための同時待機時間で構成されます。
User Response time = Service time + Queuing delay + Coherency delay
- サービス時間: 要求を処理するときにシステムが特定のリソースで消費する時間 (たとえば、データベースが SQL 要求を完了するために消費する CPU 時間)。
- 待ち行列遅延: 要求を処理するときに、システムが特定のリソースのサービスを待ち行列で待機する時間。
- コヒーレンシ遅延: 要求を処理するときに共有リソースにアクセスできるように、システムが他の同時実行タスクと通信および連携する時間。
システム スループットは、システムが 1 秒間に完了できる要求の数を示します。通常、ユーザーの応答時間とスループットは互いに反比例します。スループットが増加すると、それに応じてシステム リソースの使用率と、要求されたサービスのキューイングレイテンシーが増加します。リソースの使用率が特定の変曲点を超えると、キューイングのレイテンシーが劇的に増加します。
たとえば、OLTP 負荷を実行しているデータベース システムの場合、CPU 使用率が 65% を超えると、CPU キューイング スケジューリングのレイテンシーが大幅に増加します。これは、システムの同時リクエストが完全に独立しているわけではないためです。つまり、これらのリクエストが協力して共有リソースをめぐって競合する可能性があります。たとえば、異なるユーザーからの要求が、同じデータに対して相互に排他的なロック操作を実行する場合があります。リソースの使用率が増加すると、キューイングとスケジューリングのレイテンシーも増加し、共有リソースを時間内に解放できなくなり、他のタスクによる共有リソースの待機時間が長くなります。
パフォーマンス チューニング プロセス
パフォーマンス チューニング プロセスは、次の 6 つの手順で構成されます。
- 調整目標を定義します。
- パフォーマンスのベースラインを確立します。
- ユーザー応答時間のボトルネックを特定します。
- チューニング ソリューションを提案し、各ソリューションの利点、リスク、およびコストを評価します。
- チューニング ソリューションを実装します。
- チューニング結果を評価します。
パフォーマンス チューニング プロジェクトのチューニング目標を達成するには、通常、ステップ 2 からステップ 6 を複数回繰り返す必要があります。
ステップ 1. 調整目標を定義する
システムの種類が異なれば、チューニングの目的も異なります。たとえば、金融コア OLTP システムの場合、チューニングの目的は、トランザクションのロングテールレイテンシーを削減することです。金融決済システムの場合、チューニングの目的は、ハードウェア リソースをより有効に活用し、バッチ決済タスクの時間を短縮することです。
優れたチューニング目標は、簡単に定量化できる必要があります。例えば:
- 適切なチューニング目標: 午前 9 時から午前 10 時までのピーク時の営業時間中、転送トランザクションの p99レイテンシーを 200 ミリ秒未満にする必要があります。
- 調整目標が不十分: システムの応答が遅すぎるため、最適化する必要があります。
明確なチューニング目標を定義すると、その後のパフォーマンス チューニング手順をガイドするのに役立ちます。
ステップ 2. パフォーマンスのベースラインを確立する
パフォーマンスを効率的に調整するには、現在のパフォーマンス データを取得して、パフォーマンスのベースラインを確立する必要があります。キャプチャされるパフォーマンス データには、通常、次のものが含まれます。
ユーザー応答時間の平均値とロングテール値、およびアプリケーションのスループット
データベース時間、クエリレイテンシー、QPS などのデータベース パフォーマンス データ
TiDB は、パフォーマンス データを遅いクエリ ログ 、 Top SQL 、 継続的なパフォーマンス プロファイリング 、およびトラフィック ビジュアライザーなどのさまざまな次元で徹底的に測定および保存します。さらに、Prometheus に保存されているタイミング メトリック データの過去のバックトラックと比較を実行できます。
CPU、IO、ネットワークなどのリソースを含むリソース使用率
アプリケーション構成、データベース構成、オペレーティング システム構成などのConfiguration / コンフィグレーション情報
ステップ 3. ユーザー応答時間のボトルネックを特定する
パフォーマンス ベースラインのデータに基づいて、ユーザー応答時間のボトルネックを特定または推測します。
アプリケーションは通常、ユーザー要求の完全なチェーンを測定および記録しないため、ユーザーの応答時間をアプリケーション全体で効果的に分析することはできません。
対照的に、データベースには、クエリのレイテンシーやスループットなどのパフォーマンス メトリックの完全な記録があります。データベース時間に基づいて、ユーザー応答時間のボトルネックがデータベースにあるかどうかを判断できます。
- ボトルネックがデータベースにない場合は、データベース外で収集されたリソース使用率に依存するか、アプリケーションをプロファイリングして、データベース外のボトルネックを特定する必要があります。一般的なシナリオには、アプリケーションまたはプロキシサーバーのリソースが不十分である、アプリケーションのシリアル ポイントが原因でハードウェア リソースが十分に使用されていない、などがあります。
- データベースにボトルネックがある場合は、包括的なチューニング ツールを使用して、データベースのパフォーマンスを分析および診断できます。一般的なシナリオには、遅い SQL の存在、アプリケーションによるデータベースの不当な使用、データベース内の読み取りと書き込みのホットスポットの存在が含まれます。
分析と診断の方法とツールの詳細については、 パフォーマンス分析とチューニングを参照してください。
ステップ 4. チューニング ソリューションを提案し、各ソリューションの利点、リスク、およびコストを評価する
パフォーマンス分析によってシステムのボトルネックを特定した後、実際の状況に基づいて、費用対効果が高く、リスクが低く、最大のメリットを提供するチューニング ソリューションを提案できます。
アムダールの法則によると、パフォーマンス チューニングによる最大の利益は、システム全体における最適化された部分の割合に依存します。したがって、システムのボトルネックとそれに対応するパーセンテージをパフォーマンス データに基づいて特定し、ボトルネックが解決または最適化された後の利益を予測する必要があります。
ソリューションが最大のボトルネックを調整することによって最大の潜在的利益をもたらすことができる場合でも、このソリューションのリスクとコストを評価する必要があることに注意してください。例えば:
- リソース過負荷のシステムに対する最も単純な調整目的のソリューションは、その容量を拡張することですが、実際には、拡張ソリューションはコストがかかりすぎて採用できない場合があります。
- ビジネス モジュールのクエリが遅いためにモジュール全体の応答が遅くなる場合、新しいバージョンのデータベースにアップグレードすると、クエリが遅い問題は解決できますが、この問題が発生していないモジュールにも影響する可能性があります。したがって、このソリューションには高いリスクが伴う可能性があります。低リスクの解決策は、データベース バージョンのアップグレードをスキップし、現在のデータベース バージョンの既存のスロー クエリを書き直すことです。
ステップ 5. チューニング ソリューションを実装する
メリット、リスク、およびコストを考慮して、実装するチューニング ソリューションを 1 つ以上選択します。実装プロセスでは、本番システムへの変更を徹底的に準備し、変更を詳細に記録する必要があります。
リスクを軽減し、チューニング ソリューションの利点を検証するには、テスト環境とステージング環境の両方で検証を実行し、変更の回帰を完了することをお勧めします。たとえば、遅いクエリの選択されたチューニング ソリューションがクエリ アクセス パスを最適化するために新しいインデックスを作成することである場合、新しいインデックスが既存のデータ挿入ワークロードに明らかな書き込みホットスポットを導入せず、他の処理を遅くしないようにする必要があります。モジュール。
ステップ 6. チューニング結果の評価
チューニング ソリューションを適用した後、結果を評価する必要があります。
- チューニング目標が達成されると、チューニング プロジェクト全体が正常に完了します。
- 調整目標が達成されない場合は、調整目標が達成されるまで、このドキュメントのステップ 2 からステップ 6 を繰り返す必要があります。
チューニング目標を達成した後、ビジネスの成長に合わせてシステム容量をさらに計画する必要がある場合があります。