TiCDC 架构设计与原理
TiCDC 软件架构
TiCDC 集群由多个 TiCDC 对等节点组成,是一种分布式无状态的架构设计。TiCDC 集群及节点内部组件的设计如下图所示:
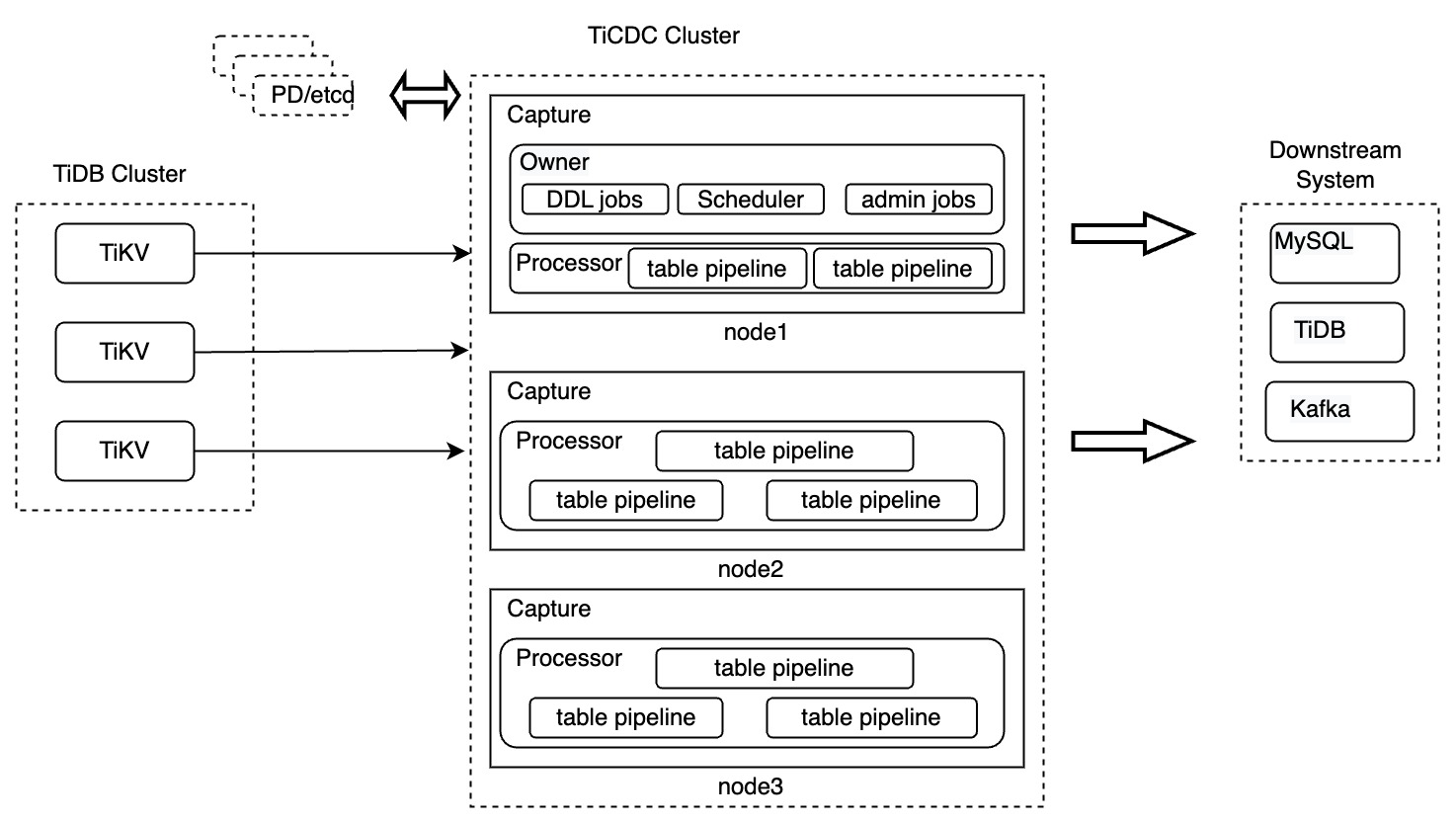
组件介绍
上图中,TiCDC 集群由多个运行了 TiCDC 实例的节点组成,每个 TiCDC 实例都运行一个 Capture 进程。多个 Capture 进程中会有一个被选举成为 Owner Capture,负责完成 TiCDC 集群的负载调度、DDL 语句同步和其它管理任务。
每个 Capture 进程包含一个或多个 Processor 线程,用于同步上游 TiDB 集群中的表数据。由于 TiCDC 同步数据的最小单位是表,所以 Processor 是由多条 table pipeline 构成的。
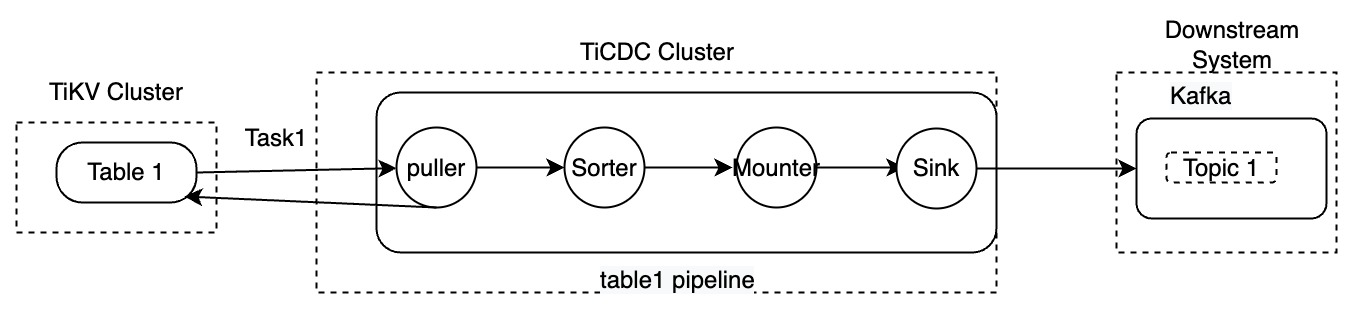
每条 pipeline 包含 Puller、Sorter、Mounter 和 Sink 模块,如下图。
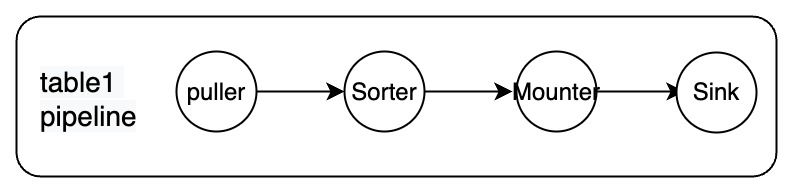
各个模块之间是串行的关系,组合在一起完成从上游拉取、排序、加载和同步数据到下游的过程,其中:
- Puller:从 TiKV 节点获取 DDL 和行变更信息。
- Sorter:将接收到的变更在 TiCDC 内按照时间戳进行升序排序。
- Mounter:将变更按照对应的 Schema 信息转换成 TiCDC 可以处理的格式。
- Sink:将对应的变更应用到下游系统。
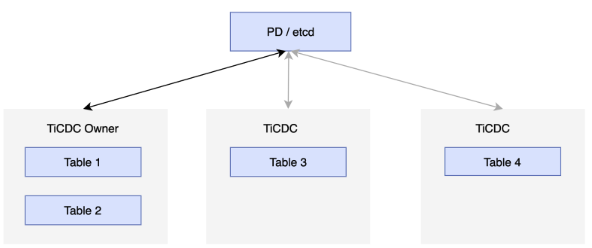
为了实现高可用,每个 TiCDC 集群都包含多个 TiCDC 节点,这些节点定期向 PD 集群中的 etcd 集群汇报自己的状态,并选举出其中一个节点作为 TiCDC 集群的 Owner。Owner 采用 etcd 统一存储状态来进行调度,并将调度结果直接写入 etcd。Processor 按照状态完成对应的任务,如果 Processor 所在节点出现异常,集群会将表调度到其他节点。如果 Owner 节点出现异常,其他节点的 Capture 进程会选举出新的 Owner,如下图所示:
Changefeed 和 Task
TiCDC 中的 Changefeed 和 Task 是两个逻辑概念,前者是分配同步任务的方式,后者是同步任务拆分后的子任务名称,具体描述如下:
Changefeed:代表一个同步任务,携带了需要同步的表信息,以及对应的下游信息和一些其他的配置信息。
Task:当 TiCDC 接收到对应的同步任务之后,就会把这个任务拆分为若干个称之为 Task 的子任务,分配给 TiCDC 集群的各个节点上的 Capture 进程进行处理。
例如:
cdc cli changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://127.0.0.1:9092/cdc-test?kafka-version=2.4.0&partition-num=6&max-message-bytes=67108864&replication-factor=1"
cat changefeed.toml
......
[sink]
dispatchers = [
{matcher = ['test1.tab1', 'test2.tab2'], topic = "{schema}_{table}"},
{matcher = ['test3.tab3', 'test4.tab4'], topic = "{schema}_{table}"},
]
关于命令中参数的详细释义,参考 TiCDC Changefeed 配置参数。
以上命令创建了一个到 Kafka 集群的 Changefeed 任务,需要同步 test1.tab1、test1.tab2、test3.tab3 和 test4.tab4 四张表。TiCDC 接收到这个命令之后的处理流程如下:
- TiCDC 将这个任务发送给 Owner Capture 进程。
- Owner Capture 进程将这个任务的相关定义信息保存在 PD 的 etcd 中。
- Owner Capture 将这个任务拆分成若干个 Task,并通知其他 Capture 进程各个 Task 需要完成的任务。
- 各个 Capture 进程开始从对应的 TiKV 节点拉取信息,进行处理后完成同步。
如果将 Changefeed 和 Task 也包含到上文中提及的架构图,完整的 TiCDC 架构图如下:
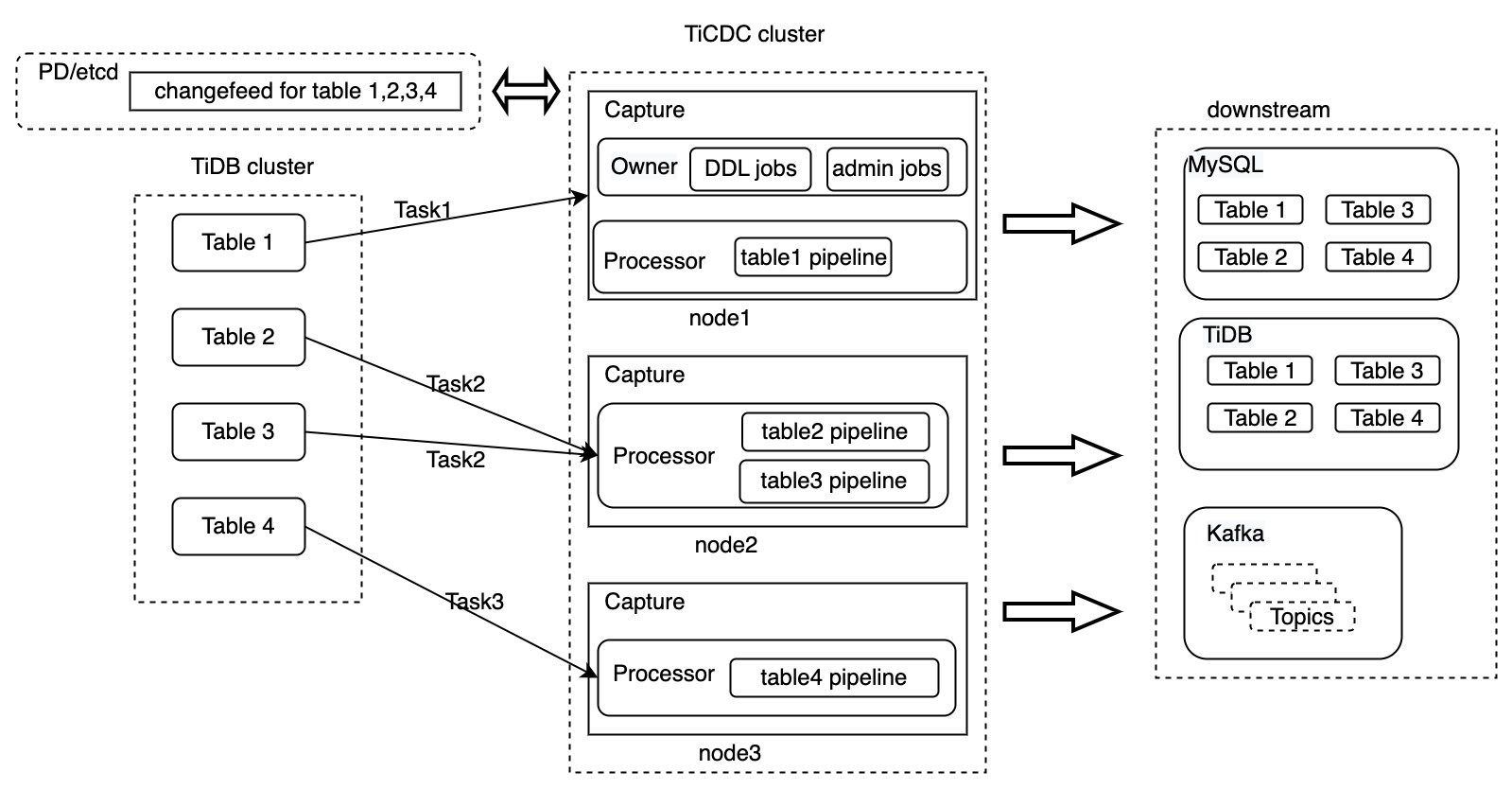
上图创建了一个 Changefeed,需要同步 4 张表,这个 Changefeed 被拆分成了 3 个任务,均匀的分发到了 TiCDC 集群的 3 个 Capture 节点上,在 TiCDC 对这些数据进行了处理之后,数据同步到了下游的系统。
目前 TiCDC 支持的下游系统包含 MySQL、TiDB 和 Kafka。上面的过程只是讲解了 Changefeed 级别数据流转的基本过程,接下来,本文将以处理表 table1 的任务 Task1 为例,从更加详细的层面来描述 TiCDC 处理数据的过程:
- 推流:发生数据改变时,TiKV 集群将数据主动推送给 Puller 模块。
- 增量扫:Puller 模块在发现收到的数据改变不连续的时候,向 TiKV 节点主动拉取需要的数据。
- 排序:Sorter 模块对获取的数据按照时间进行排序,并将排好序的数据发送给 Mounter。
- 装载:Mounter 模块收到数据变更后,根据表的 schema 信息,将数据变更装载成 TiCDC sink 可以理解的格式。
- 同步:Sink 模块根据下游的类型将数据变更同步到下游。
由于 TiCDC 的上游是支持事务的分布式关系型数据库 TiDB,在同步数据的时候,如何保证数据的一致性,以及在同步多张表的时候,如何保证事务的一致性,都是很大的挑战。下面的章节会介绍 TiCDC 在确保事务特性时所使用的关键技术和概念。
TiCDC 关键概念
当 TiCDC 对应的下游系统是关系型数据库时,TiCDC 在同步数据的时候会确保单表事务的数据一致性,以及多表事务的最终一致性。另外,TiCDC 会确保上游 TiDB 集群发生过的数据变更能够被 TiCDC 向任意下游最少同步一次。
架构相关概念
- Capture:TiCDC 节点的运行进程,多个 Capture 进程构成了 TiCDC 集群,Capture 进程负责 TiKV 的数据变更的同步,包括接收和主动拉取两种方式,并向下游同步数据。
- Capture Owner:是一种 Capture 的角色,每个 TiCDC 集群同一时刻最多只存在一个 Capture Owner 角色,负责集群内部的调度。
- Processor:是 Capture 内部的逻辑线程,每个 Processor 负责处理同一个同步流中一个或多个 table 的数据。一个 Capture 节点可以运行多个 Processor。
- ChangeFeed:一个由用户启动的从上游 TiDB 同步到下游的任务,其中包含多个 Task,Task 会分布在不同的 Capture 节点进行数据同步处理。
时间戳相关概念
由于 TiCDC 需要确保数据被至少一次同步到下游,并且确保一定的一致性,因此引入了一系列时间戳(Timestamp,简称 TS)来对数据同步的状态进行描述。
ResolvedTS
这个时间戳在 TiKV 和 TiCDC 中都存在。
TiKV 节点中的 ResolvedTS:代表某一个 Region leader 上开始时间最早的事务的开始时间,即:ResolvedTS = max(ResolvedTS, min(StartTS))。因为每个 TiDB 集群包含多个 TiKV 节点,所有 TiKV 节点上的 Region leader 的 ResolvedTS 的最小值,被称为 Global ResolvedTS。TiDB 集群确保 Global ResolvedTS 之前的事务都被提交了,或者可以认为这个时间戳之前不存在未提交的事务。
TiCDC 节点中的 ResolvedTS:
table ResolvedTS:每张表都会有的表级别 ResolvedTS,表示这张表已经从 TiKV 接收到的数据改变的最低水位,可以简单的认为和 TiKV 节点上这张表的各个 Region 的 ResolvedTS 的最小值是相同的。
global ResolvedTS:各个 TiCDC 节点上的 Processor ResolvedTS 的最小值。由于 TiCDC 每个节点上都会存在一个或多个 Processor,每个 Processor 又对应多个 table pipeline。
对于 TiCDC 节点来说,TiKV 节点发送过来的 ResolvedTS 信息是一种特殊的事件,它只包含一个格式为
<resolvedTS: 时间戳>的特殊事件。通常情况下,ResolvedTS 满足以下约束:table ResolvedTS >= global ResolvedTS
CheckpointTS
这个时间戳只在 TiCDC 中存在,它表示 TiCDC 已经同步给下游的数据的最低水位线,即 TiCDC 认为在这个时间戳之前的数据已经被同步到下游系统了。由于 TiCDC 同步数据的单位是表,所以 table CheckpointTS 表示表级别的同步数据的水位线,Processor CheckpointTS 表示各个 Processor 中最小的 table CheckpointTS;Global checkpointTS 表示各个 Processor checkpointTS 中最低的 checkpointTS。通常情况下,Checkpoint TS 满足以下约束:
table CheckpointTS >= global CheckpointTS
因为 TiCDC 只会复制小于 global ResolvedTS 的数据到下游,所以存在下面的约束:
table ResolvedTS >= global ResolvedTS >= table CheckpointTS >= global CheckpointTS
随着数据的改变和事务的提交,TiKV 节点上的 ResolvedTS 会不断的向前推进,TiCDC 节点的 Puller 模块也会不断的收到 TiKV 推流过来的数据,并且根据收到的信息决定是否执行增量扫的过程,从而确保数据改变都能够被发送到 TiCDC 节点上。Sorter 模块则负责将 Puller 模块收到的信息按照时间戳进行升序排序,从而确保数据在表级别是满足一致性的。接下来,Mounter 模块把上游的数据改变装配成 Sink 模块可以消费的格式,并发送给 Sink,而 Sink 则负责把 CheckpointTS 到 ResolvedTS 之间的数据改变,按照发生的 TS 顺序同步到下游,并在下游返回后推进 CheckpointTS。
上面的内容只介绍了和 DML 语句相关的数据改变,并没有包含 DDL 相关的内容。下面对 DDL 语句相关的关键概念进行介绍。
Barrier TS
当系统发生 DDL 变更或者用户使用了 TiCDC 的 Syncpoint 时会产生的一个时间戳。
- DDL:这个时间戳会用来确保在这个 DDL 语句之前的改变都被应用到下游,之后执行对应的 DDL 语句,在 DDL 语句同步完成之后再同步其他的数据改变。由于 DDL 语句的处理是 Owner 角色的 Capture 负责的,DDL 语句对应的 Barrier TS 只会由 Owner 节点产生。
- Syncpoint:当你启用 TiCDC 的 Syncpoint 特性后,TiCDC 会根据你指定的间隔产生一个 Barrier TS。等所有表都同步到这个 Barrier TS 后,TiCDC 将此刻的 global CheckpointTS 作为 Primary Ts 插入下游的 TiDB 记录 tsMap 信息的表中,然后 TiCDC 才会继续向下游同步数据。
一个 Barrier TS 被生成后, TiCDC 会保证只有小于 Barrier TS 的数据会被复制到下游,并且保证小于 Barrier TS 的数据全部被复制到下游之前,同步任务不会再推进。Owner 不断地比较 global CheckpointTS 和 Barrier TS 的大小,确定小于 Barrier TS 的数据是否已经被同步完成。如果 global CheckpointTS = Barrier TS,执行完对应的操作(如 DDL 或者记录 global CheckpointTS 到下游)后,同步继续;否则需要继续等待所有小于 Barrier TS 数据的同步完成。
主要流程
本章节将介绍 TiCDC 软件的常见操作所对应的主要流程,以帮助你更好的理解 TiCDC 的工作原理。
注意,下面所描述的启动流程只存在于 TiCDC 进程内部,对于用户是完全透明的。因此,你在启动 TiCDC 进程时无需关心自己启动的是什么节点。
启动 TiCDC 节点
启动非 Owner 的 TiCDC 节点:
- 启动 Capture 进程。
- 启动 processor。
- 接收 Owner 下发的 Task 调度命令。
- 根据调度命令启动或停止 tablePipeline。
启动 Owner 的 TiCDC 节点:
- 启动 Capture 进程。
- 当选 Owner 并启动对应的线程。
- 读取 Changefeed 信息。
- 启动 Changefeed 管理逻辑。
- 根据 Changefeed 配置和最新 CheckpointTS,读取 TiKV 中的 schema 信息,确定需要被同步的表。
- 读取各 Processor 当前同步的表的列表,分发需要添加的表。
- 更新进度信息。
停止 TiCDC 节点
通常来说,停止 TiCDC 节点是为了对 TiCDC 进行升级,或者对 TiCDC 所在的节点进行一些计划的维护操作。停止 TiCDC 节点的流程如下:
- 节点收到停止的信号。
- 节点将自己的服务状态置为不可用状态。
- 节点停止接收新的复制表任务。
- 通知 Owner 节点将自己节点的数据复制任务转移到其他节点。
- 复制任务转移到其他节点后,该节点停止完成。