使用 Grafana 监控 TiDB 的最佳实践
使用 TiUP 部署 TiDB 集群时,如果在拓扑配置中添加了 Grafana 和 Prometheus,会部署一套 Grafana + Prometheus 的监控平台,用于收集和展示 TiDB 集群各个组件和机器的 metric 信息。本文主要介绍使用 TiDB 监控的最佳实践,旨在帮助 TiDB 用户高效利用丰富的 metric 信息来分析 TiDB 的集群状态或进行故障诊断。
监控架构
Prometheus 是一个拥有多维度数据模型和灵活查询语句的时序数据库。Grafana 是一个开源的 metric 分析及可视化系统。
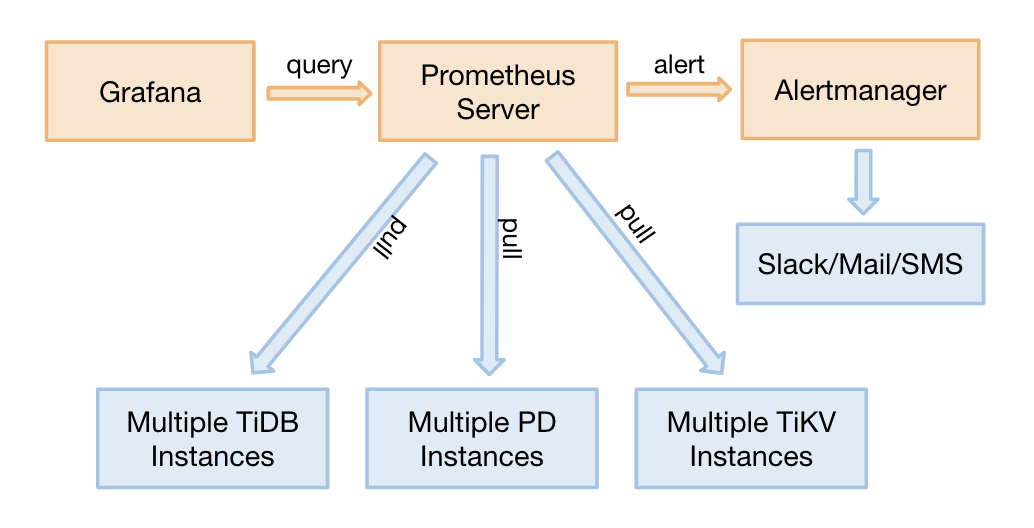
从 TiDB 2.1.3 版本开始,监控可以支持 pull,这是一个非常好的调整,它有以下几个优点:
- 如果 Prometheus 需要迁移,无需重启整个 TiDB 集群。调整前,因为组件要调整 push 的目标地址,迁移 Prometheus 需要重启整个集群。
- 支持部署 2 套独立的 Grafana + Prometheus 的监控平台(非 HA),防止监控的单点。
- 去掉了 Pushgateway 这个单点组件。
监控数据的来源与展示
TiDB 的 3 个核心组件(TiDB server、TiKV server 和 PD server)可以通过 HTTP 接口来获取 metric 数据。这些 metric 均是从程序代码中上传的,默认端口如下:
| 组件 | 端口 |
|---|---|
| TiDB server | 10080 |
| TiKV server | 20180 |
| PD server | 2379 |
下面以 TiDB server 为例,展示如何通过 HTTP 接口查看一个语句的 QPS 数据:
curl http://__tidb_ip__:10080/metrics |grep tidb_executor_statement_total
# 可以看到实时 QPS 数据,并根据不同 type 对 SQL 语句进行了区分,value 是 counter 类型的累计值(科学计数法)。
tidb_executor_statement_total{type="Delete"} 520197
tidb_executor_statement_total{type="Explain"} 1
tidb_executor_statement_total{type="Insert"} 7.20799402e+08
tidb_executor_statement_total{type="Select"} 2.64983586e+08
tidb_executor_statement_total{type="Set"} 2.399075e+06
tidb_executor_statement_total{type="Show"} 500531
tidb_executor_statement_total{type="Use"} 466016
这些数据会存储在 Prometheus 中,然后在 Grafana 上进行展示。在面板上点击鼠标右键会出现 Edit 按钮(或直接按 E 键),如下图所示:
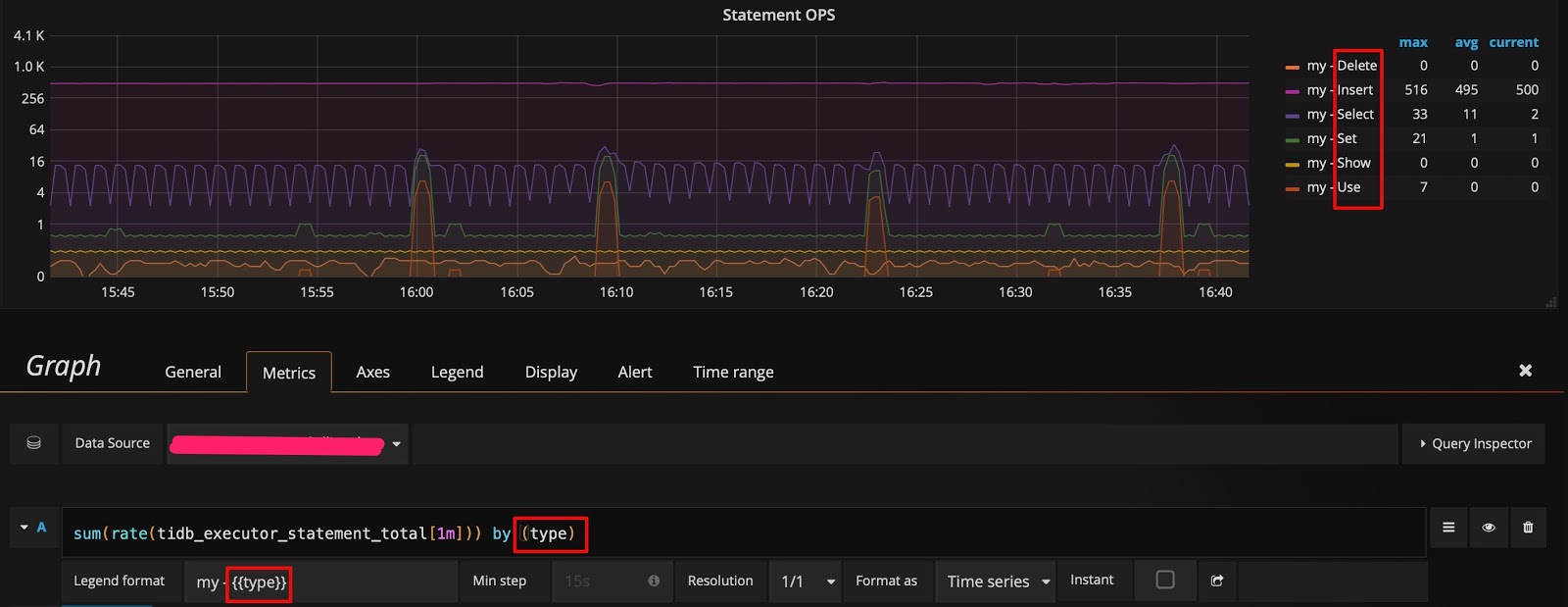
点击 Edit 按钮之后,在 Metrics 面板上可以看到利用该 metric 的 query 表达式。面板上一些细节的含义如下:
rate[1m]:表示 1 分钟的增长速率,只能用于 counter 类型的数据。sum:表示 value 求和。by type:表示将求和后的数据按 metric 原始值中的 type 进行分组。Legend format:表示指标名称的格式。Resolution:默认打点步长是 15s,Resolution 表示是否将多个样本数据合并成一个点。
Metrics 面板中的表达式如下:
Prometheus 支持很多表达式与函数,更多表达式请参考 Prometheus 官网页面。
Grafana 使用技巧
本小节介绍高效利用 Grafana 监控分析 TiDB 指标的七个技巧。
技巧 1:查看所有维度并编辑表达式
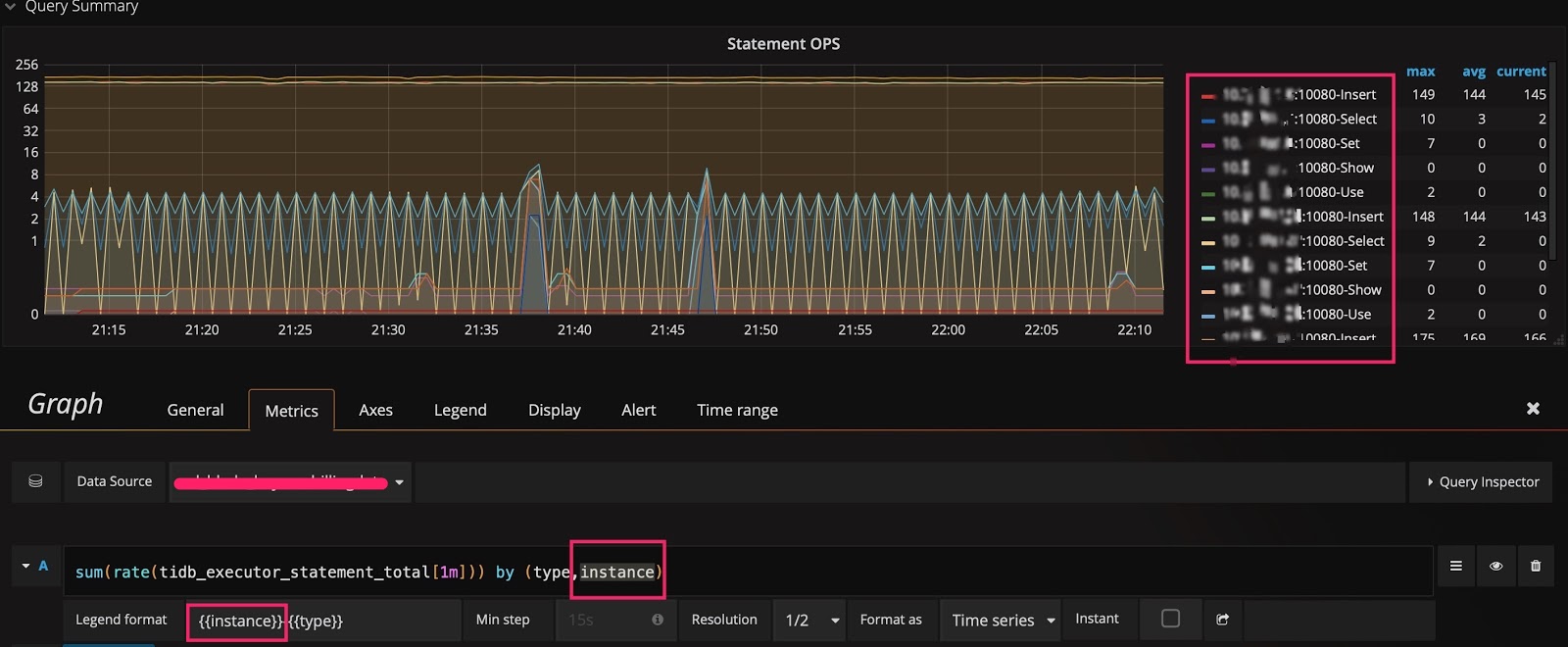
在监控数据的来源与展示一节的示例中,数据是按照 type 进行分组的。如果你想知道是否还能按其它维度分组,并快速查看还有哪些维度,可采用以下技巧:在 query 的表达式上只保留指标名称,不做任何计算,Legend format 也留空。这样就能显示出原始的 metric 数据。比如,下图能看到有 3 个维度(instance、job 和 type):
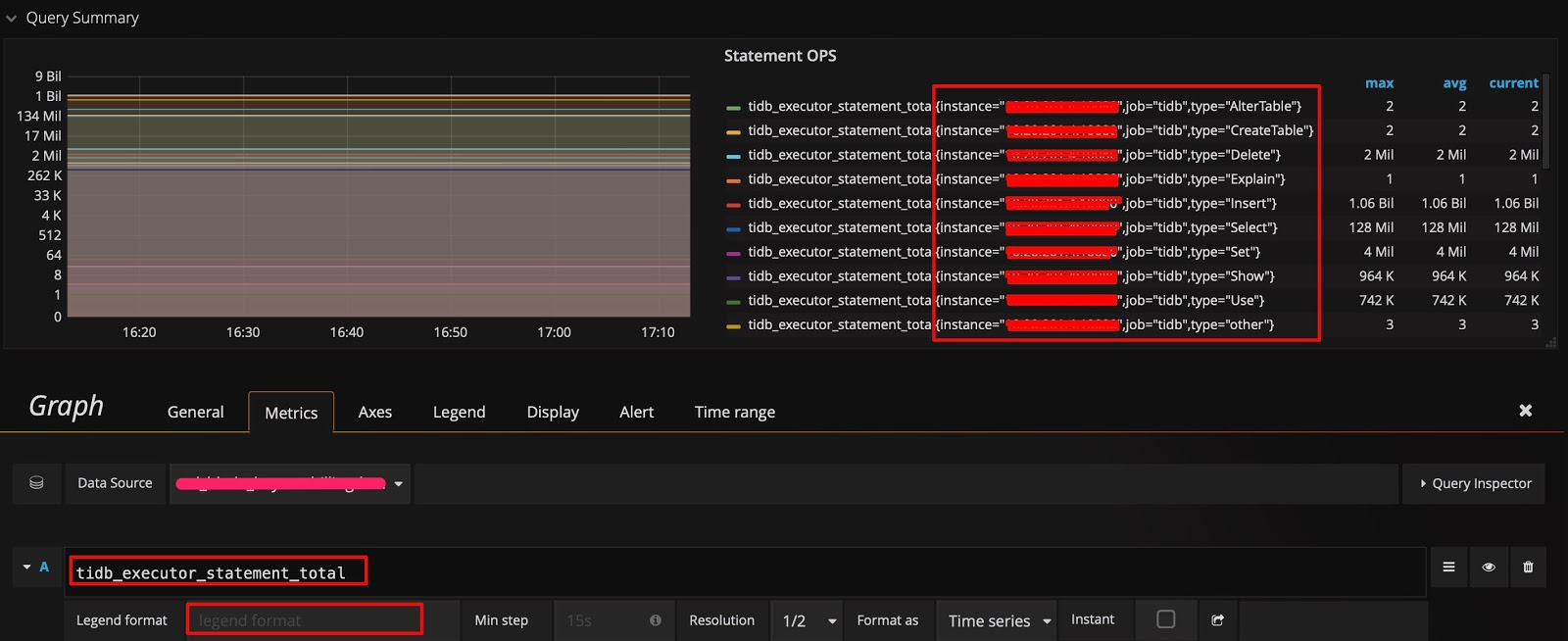
然后调整表达式,在原有的 type 后面加上 instance 这个维度,在 Legend format 处增加 {{instance}},就可以看到每个 TiDB server 上执行的不同类型 SQL 语句的 QPS 了。如下图所示:
技巧 2:调整 Y 轴标尺的计算方式
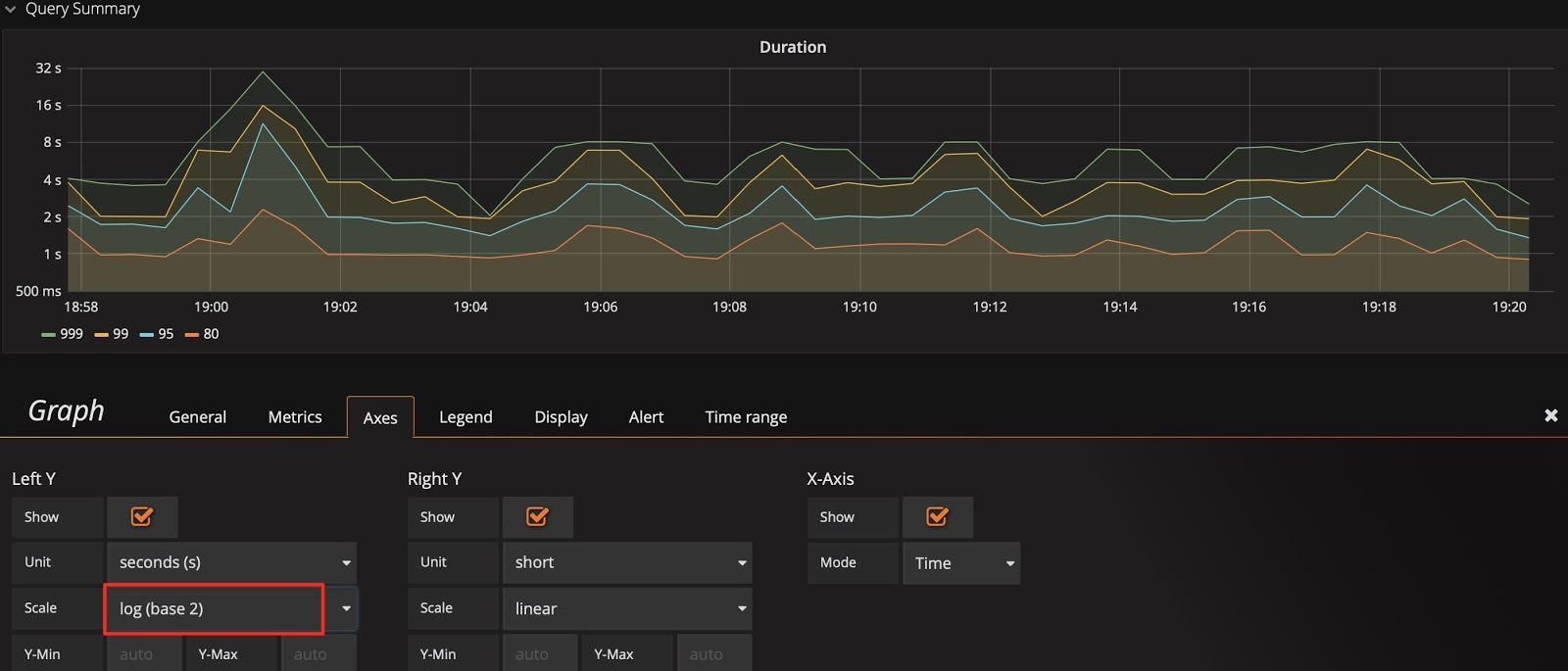
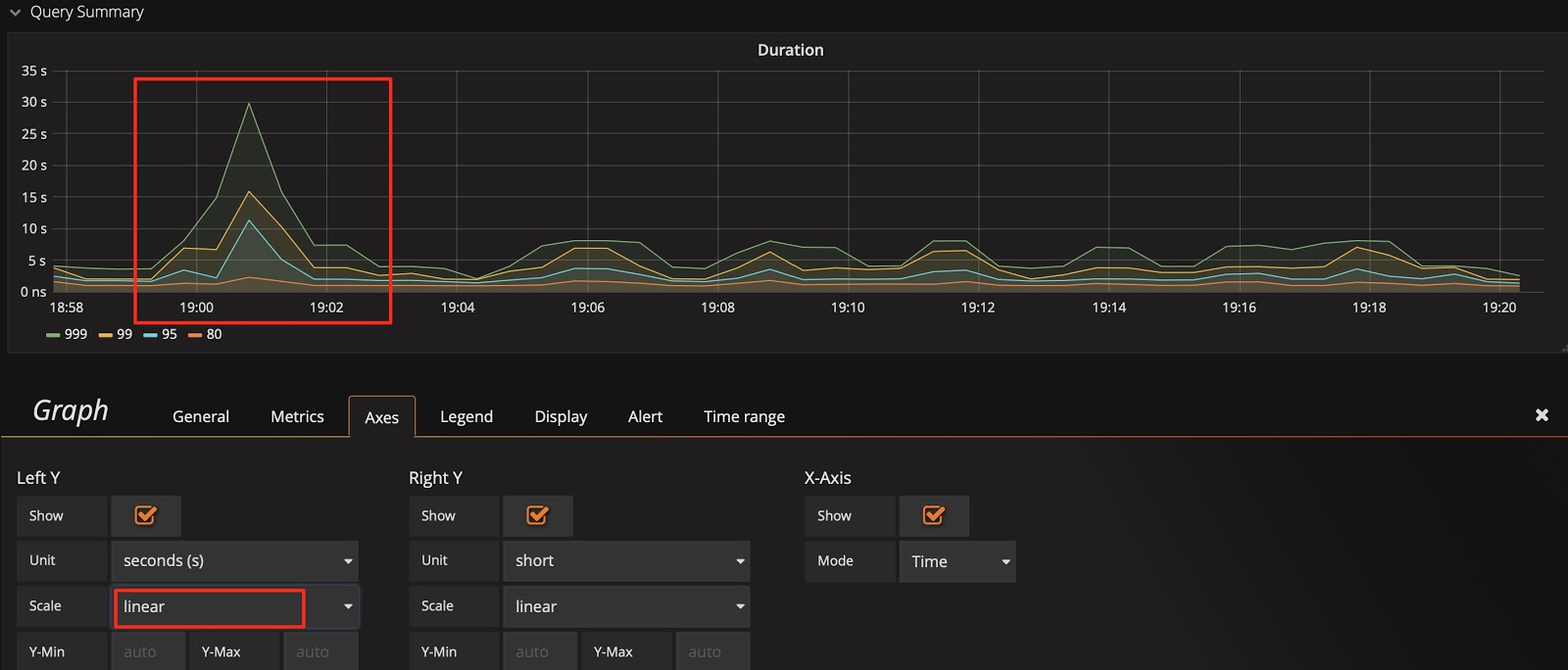
以 Query Duration 指标为例,默认的比例尺采用 2 的对数计算,显示上会将差距缩小。为了观察到明显的变化,可以将比例尺改为线性,从下面两张图中可以看到显示上的区别,明显发现那个时刻有个 SQL 语句运行较慢。
当然也不是所有场景都适合用线性,比如观察 1 个月的性能趋势,用线性可能就会有很多噪点,不好观察。
标尺默认的比例尺为 2 的对数:
将标尺的比例尺调整为线性:
技巧 3:调整 Y 轴基线,放大变化
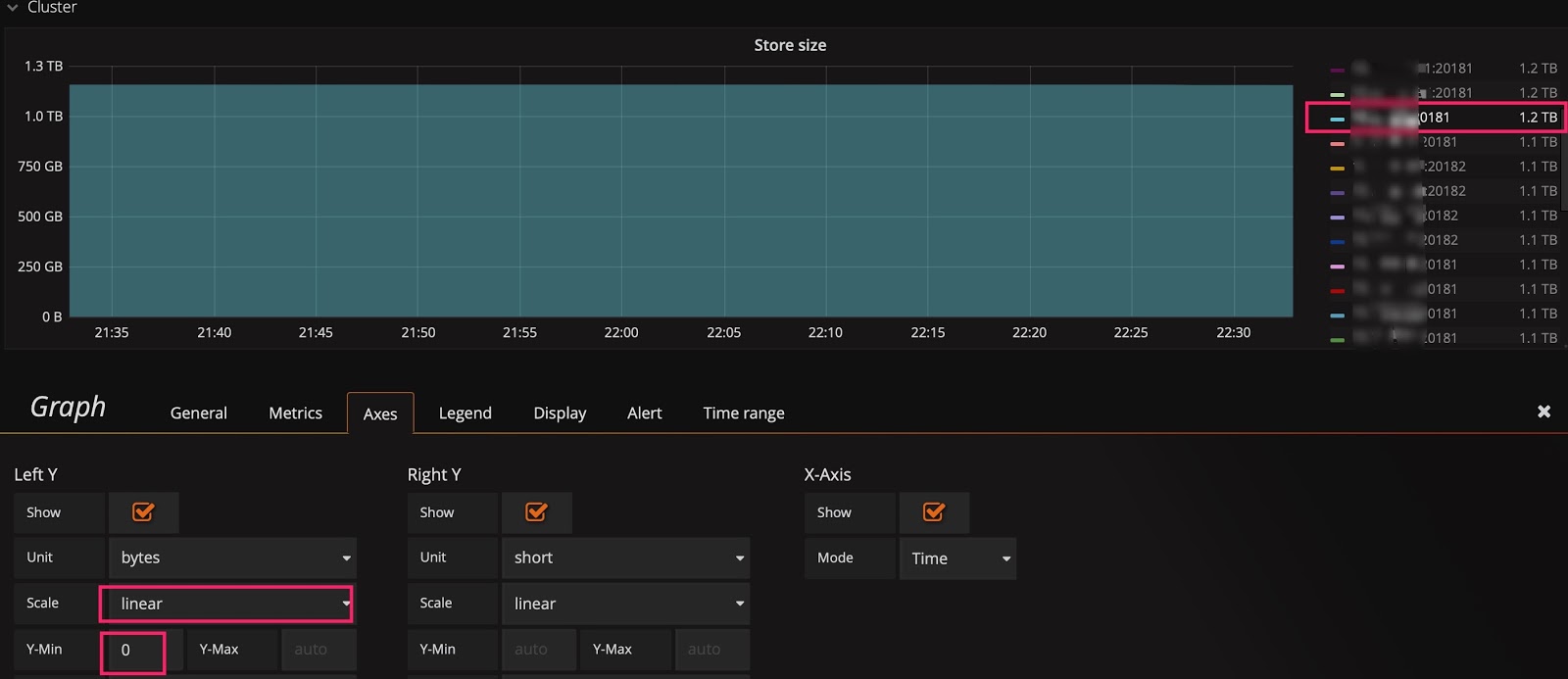
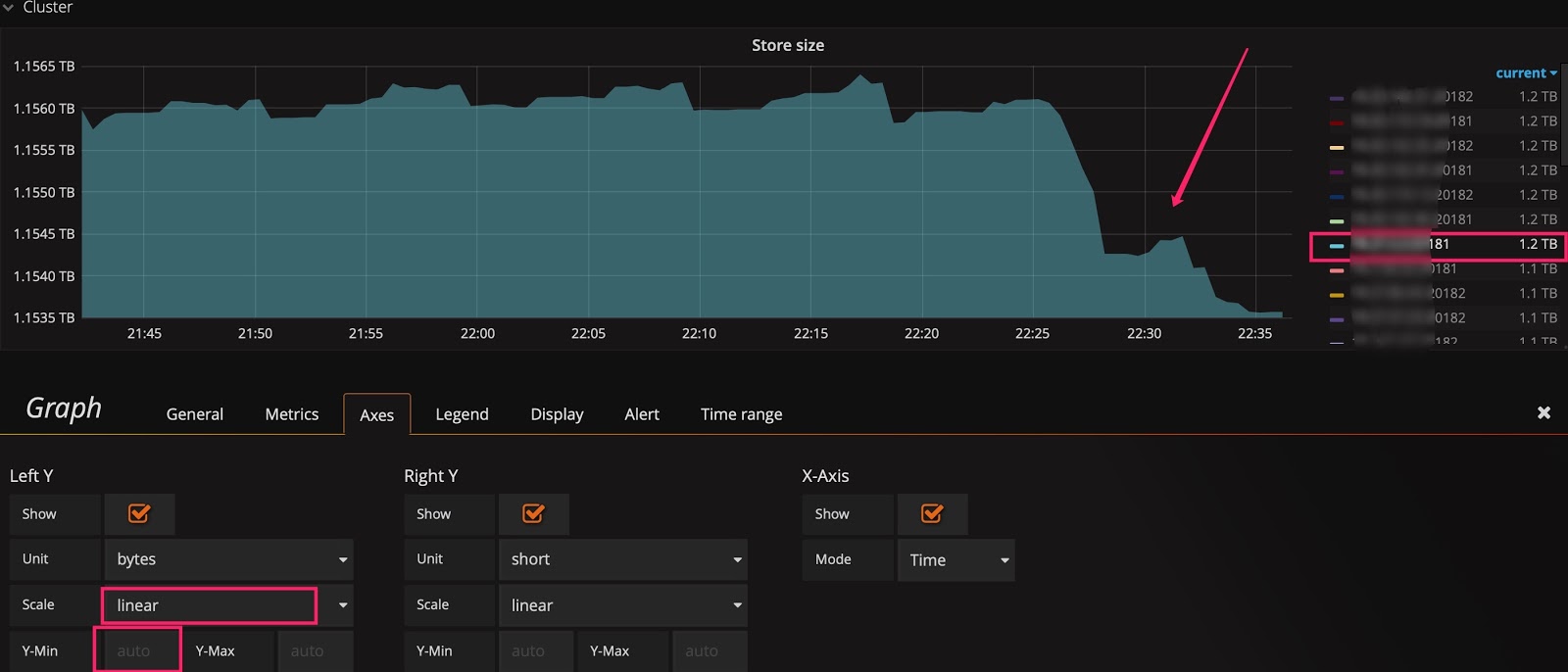
有时已经用了线性比例尺,却还是看不出变化趋势。比如下图中,在扩容后想观察 Store size 的实时变化效果,但由于基数较大,观察不到微弱的变化。这时可以将 Y 轴最小值从 0 改为 auto,将上部放大。观察下面两张图的区别,可以看出数据已开始迁移了。
基线默认为 0:
将基线调整为 auto:
技巧 4:标尺联动
在 Settings 面板中,有一个 Graph Tooltip 设置项,默认使用 Default。
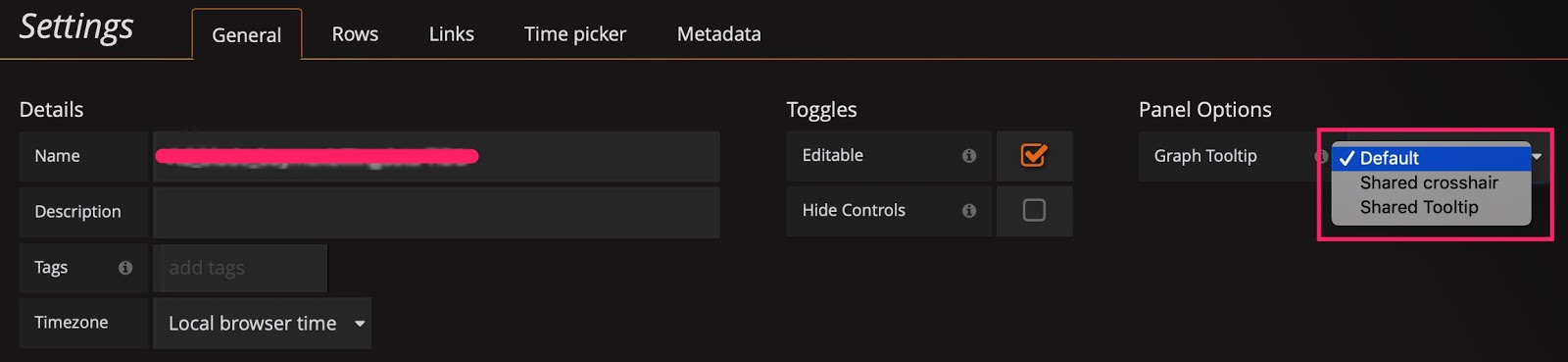
下面将图形展示工具分别调整为 Shared crosshair 和 Shared Tooltip 看看效果。可以看到标尺能联动展示了,方便排查问题时确认 2 个指标的关联性。
将图形展示工具调整为 Shared crosshair:

将图形展示工具调整为 Shared Tooltip:

技巧 5:手动输入 ip:端口号 查看历史信息
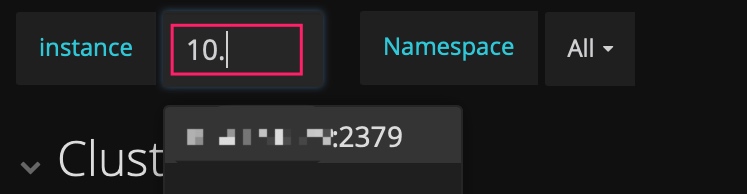
PD 的 dashboard 只展示当前 leader 的 metric 信息,而有时想看历史上 PD leader 当时的状况,但是 instance 下拉列表中已不存在这个成员了。此时,可以手动输入 ip:2379 来查看当时的数据。
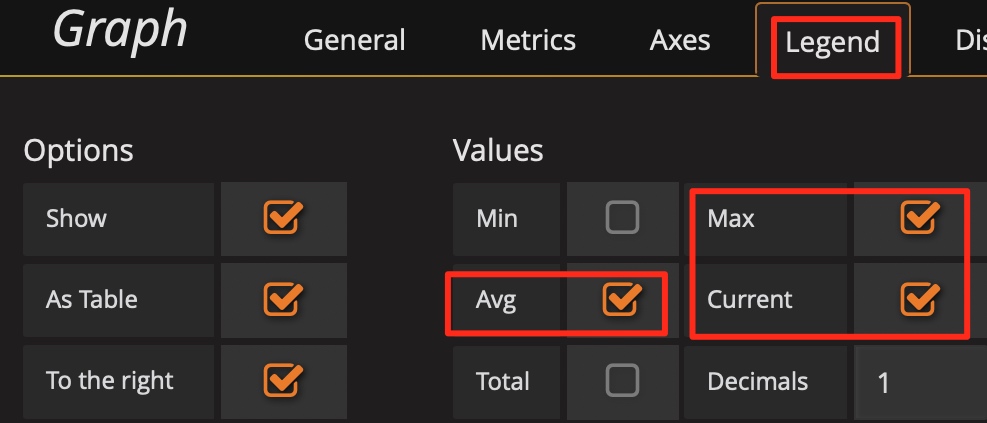
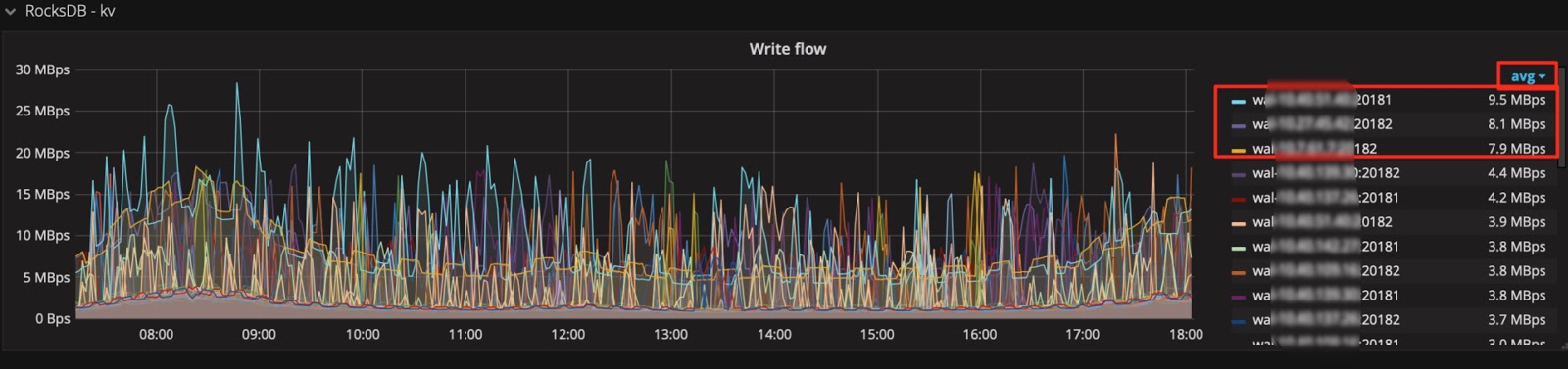
技巧 6:巧用 Avg 函数
通常默认图例中只有 Max 和 Current 函数。当指标波动较大时,可以增加 Avg 等其它汇总函数的图例,来看一段时间的整体趋势。
增加 Avg 等汇总函数:
然后查看整体趋势:
技巧 7:使用 Prometheus 的 API 接口获得表达式的结果
Grafana 通过 Prometheus 的接口获取数据,你也可以用该接口来获取数据,这个用法还可以衍生出许多功能:
- 自动获取集群规模、状态等信息。
- 对表达式稍加改动给报表提供数据,如统计每天的 QPS 总量、每天的 QPS 峰值和每天的响应时间。
- 将重要的指标进行定期健康巡检。
Prometheus 的 API 接口如下:
curl -u user:pass 'http://__grafana_ip__:3000/api/datasources/proxy/1/api/v1/query_range?query=sum(tikv_engine_size_bytes%7Binstancexxxxxxxxx20180%22%7D)%20by%20(instance)&start=1565879269&end=1565882869&step=30' |python -m json.tool
{
"data": {
"result": [
{
"metric": {
"instance": "xxxxxxxxxx:20180"
},
"values": [
[
1565879269,
"1006046235280"
],
[
1565879299,
"1006057877794"
],
[
1565879329,
"1006021550039"
],
[
1565879359,
"1006021550039"
],
[
1565882869,
"1006132630123"
]
]
}
],
"resultType": "matrix"
},
"status": "success"
}
总结
Grafana + Prometheus 监控平台是一套非常强大的组合工具,用好这套工具可以为分析节省很多时间,提高效率,更重要的是,我们可以更容易发现问题。在运维 TiDB 集群,尤其是数据量大的情况下,这套工具能派上大用场。