TiFlash 存算分离架构与 S3 支持
TiFlash 默认使用存算一体的架构进行部署,即 TiFlash 节点既是存储节点,也是计算节点。从 TiDB v7.0.0 开始,TiFlash 支持存算分离架构,并将数据存储在 Amazon S3 或兼容 S3 API 的对象存储中(比如 MinIO)。
架构介绍
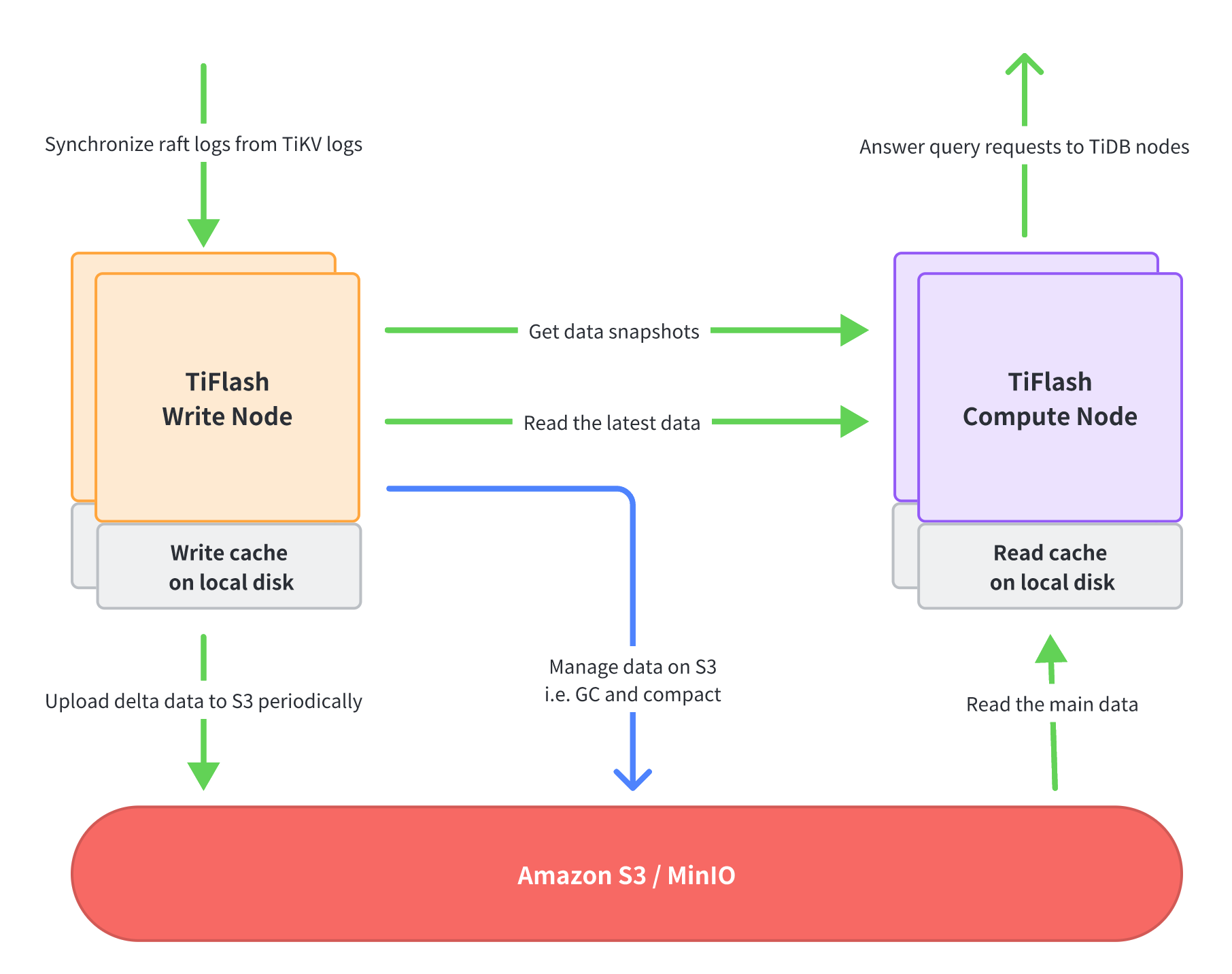
如图,在存算分离架构中,TiFlash 原有进程的不同部分的功能,被拆分到两种不同的节点中,分别是 Write Node 和 Compute Node。这两种节点可以分别部署,各自扩展,即你可以选择部署任意数量的 Write Node 或者 Compute Node。
TiFlash Write Node
负责接收 TiKV 的 Raft logs 数据,将数据转换成列存格式,并每隔一小段时间将这段时间的所有数据更新打包上传到 S3 中。此外,Write Node 也负责管理 S3 上的数据,比如不断整理数据使之具有更好的查询性能,以及删除无用的数据等。
Write Node 利用本地磁盘(通常是 NVMe SSD)来缓存最新写入的数据,从而避免过多使用内存。
TiFlash Compute Node
负责执行从 TiDB 节点发过来的查询请求。它首先访问 Write Node 以获取数据的快照 (data snapshots),然后分别从 Write Node 读取最新的数据(即尚未上传到 S3 的数据),从 S3 读取剩下的大部分数据。
Compute Node 利用本地磁盘(通常是 NVMe SSD)来作为数据文件的缓存,从而避免相同的数据反复从远端(Write Node 或者 S3)读取,以提高查询性能。
Compute Node 是无状态节点,它拥有秒级的扩容和缩容速度。你可以利用这个特性降低成本:
- 在查询负载较低时,减少 Compute Node 的数量,从而节省成本。在没有查询时,甚至可以停掉所有 Compute Node。
- 在查询负载变高时,快速增加 Compute Node 的数量,保证查询性能。
使用场景
TiFlash 存算分离架构适用于高性价比的数据分析服务的场景。在这个架构下,存储和计算资源可以单独按需扩展。在这些场景将会有较大收益:
数据量虽然很大,但是只有少量数据被频繁查询;其他大部分数据属于冷数据,很少被查询。此时经常被查询的数据通常已被缓存在 Compute Node 的本地 SSD 上,可以提供较快查询性能;而其他大部分冷数据则存储在成本较低的 S3 或者其他对象存储上,从而节省存储成本。
计算资源需求有明显的波峰和波谷。比如重型的对账查询通常放在晚上执行,此时对计算资源要求较高,可以考虑临时扩展 Compute Node;其他时间可以用较少的 Compute Node 完成查询任务。
准备条件
准备一个 S3 的 bucket,用于存储 TiFlash 数据。
你也可以使用已有的 bucket,但需要为每个 TiDB 集群预留专门的 key 前缀。关于 S3 bucket 的更多信息,请参考 AWS 文档。
也可以使用兼容 S3 的其他对象存储,比如 MinIO。
TiFlash 将使用以下 S3 API 接口进行数据读写,需要确保部署 TiFlash 的节点有这些接口的权限:
- PutObject
- GetObject
- CopyObject
- DeleteObject
- ListObjectsV2
- GetObjectTagging
- PutBucketLifecycle
确保 TiDB 集群中没有任何存算一体架构的 TiFlash 节点。如果有,则需要将所有表的 TiFlash 副本数设置为 0,然后缩容掉所有 TiFlash 节点。比如:
SELECT * FROM INFORMATION_SCHEMA.TIFLASH_REPLICA; # 查询所有带有 TiFlash 副本的表 ALTER TABLE table_name SET TIFLASH REPLICA 0; # 将所有表的 TiFlash 副本数设置为 0tiup cluster scale-in mycuster -R tiflash # 缩容掉所有 TiFlash 节点 tiup cluster display mycluster # 等待所有 TiFlash 节点进入 Tombstone 状态 tiup cluster prune mycluster # 移除所有处于 Tombstone 状态的 TiFlash 节点
使用方式
默认情况下,TiUP 会将 TiFlash 部署为存算一体架构。如需将 TiFlash 部署为存算分离架构,请参考以下步骤手动进行配置:
准备 TiFlash 的拓扑配置文件,比如 scale-out.topo.yaml,配置内容如下:
tiflash_servers: # TiFlash 的拓扑配置中存在 storage.s3 配置,说明部署时使用存算分离架构 # 配置了 flash.disaggregated_mode: tiflash_compute,则节点类型是 Compute Node; # 配置了 flash.disaggregated_mode: tiflash_write,则节点类型是 Write Node # 172.31.8.1~2 是 TiFlash Write Node - host: 172.31.8.1 config: flash.disaggregated_mode: tiflash_write # 这是一个 Write Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 的 endpoint 地址 storage.s3.bucket: mybucket # TiFlash 的所有数据存储在这个 bucket 中 storage.s3.root: /cluster1_data # S3 bucket 中存储数据的根目录 storage.s3.access_key_id: {ACCESS_KEY_ID} # 访问 S3 的 ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # 访问 S3 的 SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Write Node 的本地数据目录,和存算一体的配置方式相同 - host: 172.31.8.2 config: flash.disaggregated_mode: tiflash_write # 这是一个 Write Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 的 endpoint 地址 storage.s3.bucket: mybucket # TiFlash 的所有数据存储在这个 bucket 中 storage.s3.root: /cluster1_data # S3 bucket 中存储数据的根目录 storage.s3.access_key_id: {ACCESS_KEY_ID} # 访问 S3 的 ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # 访问 S3 的 SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Write Node 的本地数据目录,和存算一体的配置方式相同 # 172.31.9.1~2 是 TiFlash Compute Node - host: 172.31.9.1 config: flash.disaggregated_mode: tiflash_compute # 这是一个 Compute Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 的 endpoint 地址 storage.s3.bucket: mybucket # TiFlash 的所有数据存储在这个 bucket 中 storage.s3.root: /cluster1_data # S3 bucket 中存储数据的根目录 storage.s3.access_key_id: {ACCESS_KEY_ID} # 访问 S3 的 ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # 访问 S3 的 SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Compute Node 的本地数据目录,和存算一体的配置方式相同 storage.remote.cache.dir: /data1/tiflash/cache # Compute Node 的本地数据缓存目录 storage.remote.cache.capacity: 858993459200 # 800 GiB - host: 172.31.9.2 config: flash.disaggregated_mode: tiflash_compute # 这是一个 Compute Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 的 endpoint 地址 storage.s3.bucket: mybucket # TiFlash 的所有数据存储在这个 bucket 中 storage.s3.root: /cluster1_data # S3 bucket 中存储数据的根目录 storage.s3.access_key_id: {ACCESS_KEY_ID} # 访问 S3 的 ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # 访问 S3 的 SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Compute Node 的本地数据目录,和存算一体的配置方式相同 storage.remote.cache.dir: /data1/tiflash/cache # Compute Node 的本地数据缓存目录 storage.remote.cache.capacity: 858993459200 # 800 GiB注意以上
ACCESS_KEY_ID和SECRET_ACCESS_KEY是直接写在配置文件中的。你也可以选择使用环境变量的方式单独配置。如果两种方式都配置了,环境变量的优先级高于配置文件。如需通过环境变量配置,请在所有部署了 TiFlash 进程的机器上,切换到启动 TiFlash 进程的用户环境(通常是
tidb),然后修改~/.bash_profile,增加这些配置:export S3_ACCESS_KEY_ID={ACCESS_KEY_ID} export S3_SECRET_ACCESS_KEY={SECRET_ACCESS_KEY}storage.s3.endpoint支持使用http模式和https模式连接 S3,可以直接通过修改 URL 来选择。比如https://s3.{region}.amazonaws.com。
执行扩容 TiFlash 节点,并重新设置 TiFlash 副本数:
tiup cluster scale-out mycluster ./scale-out.topo.yamlALTER TABLE table_name SET TIFLASH REPLICA 1;修改 TiDB 配置,用存算分离的方式查询 TiFlash。
以编辑模式打开 TiDB 配置文件:
tiup cluster edit-config mycluster在 TiDB 配置文件中添加以下配置项:
server_configs: tidb: disaggregated-tiflash: true # 使用存算分离的方式查询 TiFlash重启 TiDB:
tiup cluster reload mycluster -R tidb
使用限制
- TiFlash 不支持在存算一体架构和存算分离架构之间原地切换。在切换到存算分离架构前,需要将原有存算一体架构的 TiFlash 节点全部删除。
- 从一种架构迁移到另外一种架构后,需要重新同步所有 TiFlash 的数据。
- 同一个 TiDB 集群只允许存在相同架构的 TiFlash 节点,不允许两种架构同时存在。
- 存算分离架构只支持使用 S3 API 的对象存储,存算一体架构只支持本地存储。
- 使用 S3 存储的情况下,TiFlash 节点无法获取非本节点文件的密钥,因此无法启用静态加密功能。