TiDB 全局排序
功能概览
TiDB 全局排序功能增强了数据导入和 DDL(数据定义语言)操作的稳定性和执行效率。全局排序作为分布式执行框架中的通用算子,通过分布式执行框架,在云上提供全局排序服务。
全局排序目前仅支持使用 Amazon S3 作为云存储,未来将扩展支持多种共享存储接口,例如 POSIX,实现与不同存储系统的无缝集成。全局排序功能可以灵活地为各种使用场景提供高效且适配的数据排序服务。
目标
全局排序功能旨在提高 IMPORT INTO 和 CREATE INDEX 的稳定性与效率。通过将任务需要处理的数据进行全局排序,可以提高数据写入 TiKV 的稳定性、可控性和可扩展性,从而提供更好的数据导入与 DDL 任务的用户体验及更高质量的服务。
全局排序功能在后端任务分布式并行执行框架中执行任务,确保后端任务所需处理的数据在全局范围内保持有序。
限制
目前,全局排序功能不支持在查询过程中对查询结果进行排序。
使用方法
要开启全局排序功能,执行以下步骤:
将
tidb_enable_dist_task的值设置为ON,以开启分布式执行框架:SET GLOBAL tidb_enable_dist_task = ON;将
tidb_cloud_storage_uri设置为正确的云存储路径。参见示例。SET GLOBAL tidb_cloud_storage_uri = 's3://my-bucket/test-data?role-arn=arn:aws:iam::888888888888:role/my-role'
实现原理
全局排序功能的算法如下图所示:
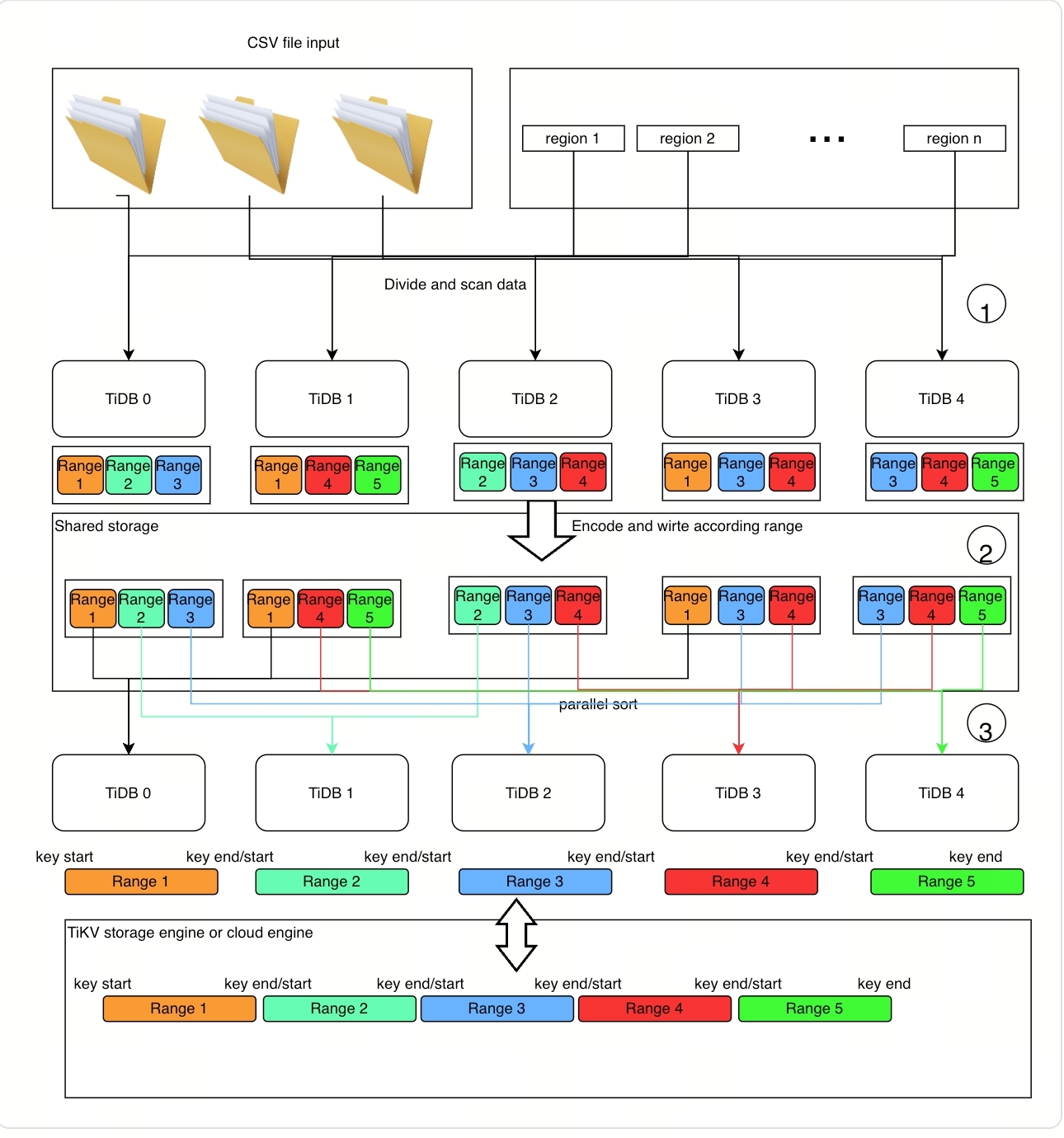
详细的实现原理如下:
第 1 步:扫描和准备数据
TiDB 节点扫描特定范围的数据后(数据源可以是 CSV 数据或者 TiKV 中的表数据):
- TiDB 节点将扫描的数据编码为键值对。
- TiDB 节点将键值对排序为多个块数据段(数据段局部有序),每个段是一个文件,并将这些文件上传到云存储中。
TiDB 节点记录了每个段的连续实际键值范围(称为统计信息文件),这是可扩展排序实现的关键准备工作。这些文件随实际数据一起上传到云存储中。
第 2 步:排序和分发数据
从第一步中,全局排序的程序获取了一个已排序块的列表及其对应的统计信息文件,这些文件记录了本地已排序块的数量。此外,全局排序程序还记录了一个实际数据范围,供 PD 用于数据拆分和打散。接下来将执行以下步骤:
- 将统计信息文件中的记录排序,划分为大小相近的范围,每个范围将作为一个并行执行的子任务。
- 将子任务分发给 TiDB 节点执行。
- 每个 TiDB 节点独立地对子任务的数据进行排序,并在没有重叠的情况下将数据导入到 TiKV 中。