TiCDC 简介
TiCDC 是一款 TiDB 增量数据同步工具,通过拉取上游 TiKV 的数据变更日志,TiCDC 可以将数据解析为有序的行级变更数据输出到下游。
TiCDC 适用场景
TiCDC 适用于以下场景:
- 提供多 TiDB 集群,跨区域数据高可用和容灾方案,保证在灾难发生时保证主备集群数据的最终一致性。
- 提供同步实时变更数据到异构系统的服务,为监控、缓存、全文索引、数据分析、异构数据库使用等场景提供数据源。
TiCDC 主要特性
核心能力
TiCDC 提供了以下核心能力:
- 提供 TiDB -> TiDB 之间数据容灾复制的能力,实现秒级别 RPO 和分钟级别 RTO
- 提供 TiDB 之间双向复制的能力,支持通过 TiCDC 构建多写多活的 TiDB 集群
- 提供 TiDB -> MySQL(或其他兼容 MySQL 协议的数据库)的低延迟的增量数据同步能力
- 提供 TiDB -> Kafka 增量数据同步能力,推荐的数据格式包含 Canal-JSON,Avro 等
- 提供 TiDB -> 存储服务(如:Amazon S3、GCS、Azure Blob Storage 和 NFS)增量数据同步能力。
- 提供表级别数据同步能力,支持同步过程中过滤数据库、表、DML、DDL 的能力
- 高可用架构,无单点故障;支持动态添加、删除 TiCDC 节点
- 支持通过 Open API 进行集群管理,包括查询任务状态;动态修改任务配置;动态创建、删除任务等
数据同步顺序性
- TiCDC 对于所有的 DDL/DML 都能对外输出至少一次。
- TiCDC 在 TiKV/TiCDC 集群故障期间可能会重复发相同的 DDL/DML。对于重复的 DDL/DML:
- MySQL sink 可以重复执行 DDL,对于在下游可重入的 DDL(譬如
TRUNCATE TABLE)直接执行成功;对于在下游不可重入的 DDL(譬如CREATE TABLE),执行失败,TiCDC 会忽略错误继续同步。 - Kafka sink 提供不同的数据分发策略:
- 可以按照表、主键或 ts 等策略分发数据到不同 Kafka partition。使用表、主键分发策略,可以保证某一行的更新数据被顺序的发送到相同 partition。
- 对所有的分发策略,TiCDC 都会定期发送 Resolved TS 消息到所有的 topic/partition,表示早于该 Resolved TS 的消息都已经发送到 topic/partition,消费程序可以利用 Resolved TS 对多个 topic/partition 的消息进行排序。
- Kafka sink 会发送重复的消息,但重复消息不会破坏 Resolved TS 的约束,比如在 changefeed 暂停重启后,可能会按顺序发送 msg1、msg2、msg3、msg2、msg3。你可以在 Kafka 消费端进行过滤。
- MySQL sink 可以重复执行 DDL,对于在下游可重入的 DDL(譬如
数据同步一致性
MySQL sink
- TiCDC 开启 redo log 后保证数据复制的最终一致性
- TiCDC 保证单行的更新与上游更新顺序一致。
- TiCDC 不保证下游事务的执行顺序和上游完全一致。
TiCDC 架构
TiCDC 作为 TiDB 的增量数据同步工具,通过 PD 内部的 etcd 实现高可用,通过多个 TiCDC 进程获取 TiKV 节点上的数据改变,在内部进行排序、合并等处理之后,通过多个同步任务 (Changefeed),同时向多个下游系统进行数据同步。
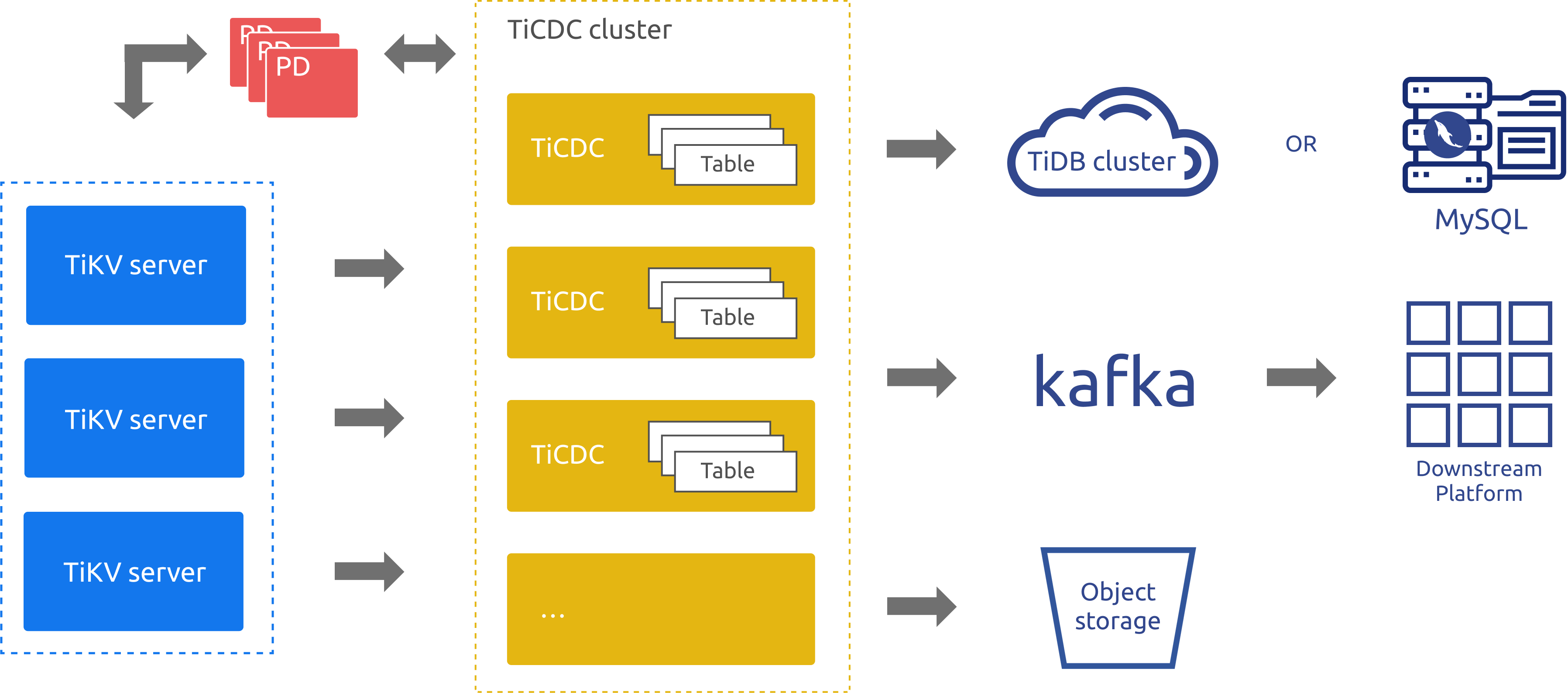
在以上架构图中:
- TiKV Server:代表 TiDB 集群中的 TiKV 节点,当数据发生改变时 TiKV 节点会主动将发生的数据改变以变更日志(KV change logs,简称 change logs)的方式发送给 TiCDC 节点。当然,当 TiCDC 节点发现收到的 change logs 并不是连续的,也会主动发起请求,获得需要的 change logs。
- TiCDC:代表运行了运行 TiCDC 进程的各个节点。每个节点都运行一个 TiCDC 进程,每个进程会从 TiKV 节点中拉取一个或者多个表中的数据改变,并通过 Sink 模块同步到下游系统。
- PD:代表 TiDB 集群中的调度模块,负责集群数据的事实调度,这个模块通常是由 3 个 PD 节点构成的,内部通过 etcd 集群来实现选举等高可用相关的能力。 TiCDC 集群使用了 PD 集群内置的 etcd 集群来保存自己的元数据信息,例如:节点的状态信息,changefeed 配置信息等。
另外,从上面的架构图中也可以看到,目前 TiCDC 支持将数据同步到 TiDB、MySQL 数据库、Kafka 以及存储服务等。
最佳实践
使用 TiCDC 在两个 TiDB 集群间同步数据时,当上下游的延迟超过 100 ms 时,推荐将 TiCDC 部署在下游 TiDB 集群所在的区域 (IDC, region)。
TiCDC 同步的表需要至少存在一个有效索引的表,有效索引的定义如下:
- 主键 (
PRIMARY KEY) 为有效索引。 - 唯一索引 (
UNIQUE INDEX) 中每一列在表结构中明确定义非空 (NOT NULL) 且不存在虚拟生成列 (VIRTUAL GENERATED COLUMNS)。
- 主键 (
在使用 TiCDC 实现容灾的场景下,为实现最终一致性,需要配置 redo log 并确保 redo log 写入的存储系统在上游发生灾难时可以正常读取。
使用 TiCDC 同步单行较大 (> 1k) 的宽表时,推荐设置 TiCDC 参数 per-table-memory-quota,使得
per-table-memory-quota=ticdcTotalMemory/ (tableCount* 2)。ticdcTotalMemory是一个 TiCDC 节点的内存,tableCount是一个 TiCDC 节点同步的目标表的数量。
暂不支持的场景
目前 TiCDC 暂不支持的场景如下:
- 暂不支持单独使用 RawKV 的 TiKV 集群。
- 暂不支持在 TiDB 中创建 SEQUENCE 的 DDL 操作和 SEQUENCE 函数。在上游 TiDB 使用 SEQUENCE 时,TiCDC 将会忽略掉上游执行的 SEQUENCE DDL 操作/函数,但是使用 SEQUENCE 函数的 DML 操作可以正确地同步。