SELECT
SELECT 语句用于从 TiDB 读取数据。
语法图
SelectStmt:

FromDual:

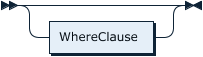
WhereClauseOptional:
SelectStmtOpts:

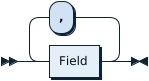
SelectStmtFieldList:
TableRefsClause:
- TableRefsClause
- AsOfClause
TableRefsClause ::=
TableRef AsOfClause? ( ',' TableRef AsOfClause? )*
AsOfClause ::=
'AS' 'OF' 'TIMESTAMP' Expression
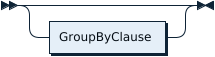
SelectStmtGroup:
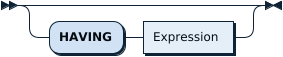
HavingClause:
OrderByOptional:
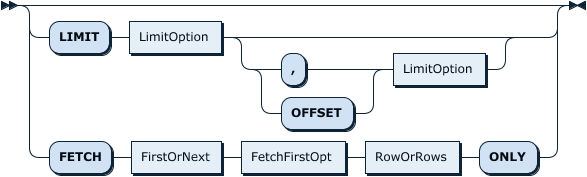
SelectStmtLimit:
FirstOrNext:

FetchFirstOpt:
RowOrRows:
SelectLockOpt:
- SelectLockOpt
- TableList
SelectLockOpt ::=
( ( 'FOR' 'UPDATE' ( 'OF' TableList )? 'NOWAIT'? )
| ( 'LOCK' 'IN' 'SHARE' 'MODE' ) )?
TableList ::=
TableName ( ',' TableName )*
WindowClauseOptional
TableSampleOpt
- TableSampleOpt
TableSampleOpt ::=
'TABLESAMPLE' 'REGIONS()'
语法元素说明
| 语法元素 | 说明 |
|---|---|
TableOptimizerHints | 用于控制优化器行为的 Hint,具体可参见 Optimizer Hints |
ALL、DISTINCT、DISTINCTROW | 查询结果集中可能会包含重复值。指定 DISTINCT/DISTINCTROW 则在查询结果中过滤掉重复的行;指定 ALL 则列出所有的行。默认为 ALL。 |
HIGH_PRIORITY | 该语句为高优先级语句,TiDB 在执行阶段会优先处理这条语句 |
SQL_CALC_FOUND_ROWS | TiDB 不支持该语法,并报错(若 tidb_enable_noop_functions 值设为 1 则不会报错) |
SQL_CACHE、SQL_NO_CACHE | 是否把请求结果缓存到 TiKV (RocksDB) 的 BlockCache 中。对于一次性的大数据量的查询,比如 count(*) 查询,为了避免冲掉 BlockCache 中用户的热点数据,建议填上 SQL_NO_CACHE |
STRAIGHT_JOIN | STRAIGHT_JOIN 会强制优化器按照 FROM 子句中所使用的表的顺序做联合查询。当优化器选择的 Join 顺序并不优秀时,你可以使用这个语法来加速查询的执行 |
select_expr | 投影操作列表,一般包括列名、表达式,或者是用 '*' 表示全部列 |
FROM table_references | 表示数据来源,数据来源可以是一个表 (select * from t;) 或者是多个表 (select * from t1 join t2;) 或者是 0 个表(select 1+1 from dual;,等价于 select 1+1;) |
WHERE where_condition | Where 子句用于设置过滤条件,查询结果中只会包含满足条件的数据 |
GROUP BY | GroupBy 子句用于对查询结果集进行分组 |
HAVING where_condition | Having 子句与 Where 子句作用类似,Having 子句可以让过滤 GroupBy 后的各种数据,Where 子句用于在聚合前过滤记录。 |
ORDER BY | OrderBy 子句用于指定结果排序顺序,可以按照列、表达式或者是 select_expr 列表中某个位置的字段进行排序。 |
LIMIT | Limit 子句用于限制结果条数。Limit 接受一个或两个数字参数,如果只有一个参数,那么表示返回数据的最大行数;如果是两个参数,那么第一个参数表示返回数据的第一行的偏移量(第一行数据的偏移量是 0),第二个参数指定返回数据的最大条目数。另支持 FETCH FIRST/NEXT n ROW/ROWS ONLY 语法,与 LIMIT n 效果相同,其中 n 可省略,省略时与 LIMIT 1 效果相同。 |
Window window_definition | 窗口函数的相关语法,用来进行一些分析型计算的操作,详情可见窗口函数 |
FOR UPDATE | 对查询结果集所有行上锁(对于在查询条件内,但是不在结果集的行,将不会加锁,如事务启动后由其他事务写入的行),以监测其他事务对这些的并发修改。当 TiDB 使用乐观事务模型时,语句执行期间不会检测锁,因此,不会像 PostgreSQL 之类的数据库一样,在当前事务结束前阻止其他事务执行 UPDATE、DELETE 和 SELECT FOR UPDATE。在事务的提交阶段 SELECT FOR UPDATE 读到的行,也会进行两阶段提交,因此,它们也可以参与事务冲突检测。如发生写入冲突,那么包含 SELECT FOR UPDATE 语句的事务会提交失败。如果没有冲突,事务将成功提交,当提交结束时,这些被加锁的行,会产生一个新版本,可以让其他尚未提交的事务,在将来提交时发现写入冲突。当 TiDB 使用悲观事务模型时,其行为与其他数据库基本相同,不一致之处参考和 MySQL InnoDB 的差异。TiDB 支持 FOR UPDATE NOWAIT 语法,详情可见 TiDB 中悲观事务模式的行为。 |
LOCK IN SHARE MODE | TiDB 出于兼容性解析这个语法,但是不做任何处理 |
TABLESAMPLE | 从表中获取一些行的样本数据。 |
示例
CREATE TABLE t1 (id INT NOT NULL PRIMARY KEY AUTO_INCREMENT, c1 INT NOT NULL);
Query OK, 0 rows affected (0.11 sec)
INSERT INTO t1 (c1) VALUES (1),(2),(3),(4),(5);
Query OK, 5 rows affected (0.03 sec)
Records: 5 Duplicates: 0 Warnings: 0
SELECT * FROM t1;
+----+----+
| id | c1 |
+----+----+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
+----+----+
5 rows in set (0.00 sec)
下面这个例子使用 tiup bench tpcc prepare 生成的数据,其中第一个查询展示了 TABLESAMPLE 的用法。
mysql> SELECT AVG(s_quantity), COUNT(s_quantity) FROM stock TABLESAMPLE REGIONS();
+-----------------+-------------------+
| AVG(s_quantity) | COUNT(s_quantity) |
+-----------------+-------------------+
| 59.5000 | 4 |
+-----------------+-------------------+
1 row in set (0.00 sec)
mysql> SELECT AVG(s_quantity), COUNT(s_quantity) FROM stock;
+-----------------+-------------------+
| AVG(s_quantity) | COUNT(s_quantity) |
+-----------------+-------------------+
| 54.9729 | 1000000 |
+-----------------+-------------------+
1 row in set (0.52 sec)
MySQL 兼容性
- 不支持
SELECT ... INTO @variable语法。 - 不支持
SELECT ... GROUP BY ... WITH ROLLUP语法。 - 不支持 MySQL 5.7 中支持的
SELECT .. GROUP BY expr语法,而是匹配 MySQL 8.0 的行为,不按照默认的顺序进行排序。 SELECT ... TABLESAMPLE ...是 TiDB 的扩展语法,MySQL 不支持该语法。