TiDB 内存控制文档
目前 TiDB 已经能够做到追踪单条 SQL 查询过程中的内存使用情况,当内存使用超过一定阈值后也能采取一些操作来预防 OOM 或者排查 OOM 原因。你可以使用系统变量 tidb_mem_oom_action 来控制查询超过内存限制后所采取的操作:
- 如果变量值为
LOG,那么当一条 SQL 的内存使用超过一定阈值(由 session 变量tidb_mem_quota_query控制)后,这条 SQL 会继续执行,但 TiDB 会在 log 文件中打印一条 LOG。 - 如果变量值为
CANCEL,那么当一条 SQL 的内存使用超过一定阈值后,TiDB 会立即中断这条 SQL 的执行,并给客户端返回一个错误,错误信息中会详细写明在这条 SQL 执行过程中占用内存的各个物理执行算子的内存使用情况。
如何配置一条 SQL 执行过程中的内存使用阈值
使用系统变量 tidb_mem_quota_query 来配置一条 SQL 执行过程中的内存使用阈值,单位为字节。例如:
配置整条 SQL 的内存使用阈值为 8GB:
SET tidb_mem_quota_query = 8 << 30;
配置整条 SQL 的内存使用阈值为 8MB:
SET tidb_mem_quota_query = 8 << 20;
配置整条 SQL 的内存使用阈值为 8KB:
SET tidb_mem_quota_query = 8 << 10;
如何配置 tidb-server 实例使用内存的阈值
可以在配置文件中设置 tidb-server 实例的内存使用阈值。相关配置项为 server-memory-quota 。
例如,配置 tidb-server 实例的内存使用总量,将其设置成为 32 GB:
[performance]
server-memory-quota = 34359738368
在该配置下,当 tidb-server 实例内存使用到达 32 GB 时,正在执行的 SQL 语句会被随机强制终止,直至 tidb-server 实例内存使用下降到 32 GB 以下。被强制终止的 SQL 操作会向客户端返回 Out Of Global Memory Limit! 错误信息。
tidb-server 内存占用过高时的报警
默认配置下,tidb-server 实例会在机器内存使用达到总内存量的 80% 时打印报警日志,并记录相关状态文件。该内存使用率可以通过系统变量 tidb_memory_usage_alarm_ratio 进行设置。具体报警规则请参考该变量的说明部分。
注意,当触发一次报警后,只有在内存使用率连续低于阈值超过 10 秒并再次达到阈值时,才会再次触发报警。此外,为避免报警时产生的状态文件积累过多,目前只会保留最近 5 次报警时所生成的状态文件。
下例通过构造一个占用大量内存的 SQL 语句触发报警,对该报警功能进行演示:
- 配置报警比例为
0.8:
```toml
mem-quota-query = 34359738368
[instance]
tidb_memory_usage_alarm_ratio = 0.8
```
创建单表
CREATE TABLE t(a int);并插入 1000 行数据。执行
select * from t t1 join t t2 join t t3 order by t1.a。该 SQL 语句会输出 1000000000 条记录,占用巨大的内存,进而触发报警。检查
tidb.log文件,其中会记录系统总内存、系统当前内存使用量、tidb-server 实例的内存使用量以及状态文件所在目录。[2020/11/30 15:25:17.252 +08:00] [WARN] [memory_usage_alarm.go:141] ["tidb-server has the risk of OOM. Running SQLs and heap profile will be recorded in record path"] ["is server-memory-quota set"=false] ["system memory total"=33682427904] ["system memory usage"=27142864896] ["tidb-server memory usage"=22417922896] [memory-usage-alarm-ratio=0.8] ["record path"="/tmp/1000_tidb/MC4wLjAuMDo0MDAwLzAuMC4wLjA6MTAwODA=/tmp-storage/record"]以上 Log 字段的含义如下:
is server-memory-quota set:表示配置项server-memory-quota是否被设置system memory total:表示当前系统的总内存system memory usage:表示当前系统的内存使用量tidb-server memory usage:表示 tidb-server 实例的内存使用量memory-usage-alarm-ratio:表示系统变量tidb_memory_usage_alarm_ratio的值record path:表示状态文件存放的目录
通过访问状态文件所在目录(该示例中的目录为
/tmp/1000_tidb/MC4wLjAuMDo0MDAwLzAuMC4wLjA6MTAwODA=/tmp-storage/record),可以得到一组文件,其中包括goroutinue、heap、running_sql3 个文件,文件以记录状态文件的时间为后缀。这 3 个文件分别用来记录报警时的 goroutine 栈信息,堆内存使用状态,及正在运行的 SQL 信息。其中running_sql文件内的日志格式请参考expensive-queries。
tidb-server 其它内存控制策略
流量控制
- TiDB 支持对读数据算子的动态内存控制功能。读数据的算子默认启用
tidb_distsql_scan_concurrency所允许的最大线程数来读取数据。当单条 SQL 语句的内存使用每超过tidb_mem_quota_query一次,读数据的算子就会停止一个线程。 - 流控行为由参数
tidb_enable_rate_limit_action控制。 - 当流控被触发时,会在日志中打印一条包含关键字
memory exceeds quota, destroy one token now的日志。
数据落盘
TiDB 支持对执行算子的数据落盘功能。当 SQL 的内存使用超过 Memory Quota 时,tidb-server 可以通过落盘执行算子的中间数据,缓解内存压力。支持落盘的算子有:Sort、MergeJoin、HashJoin、HashAgg。
- 落盘行为由参数
tidb_mem_quota_query、tidb_enable_tmp_storage_on_oom、tmp-storage-path、tmp-storage-quota共同控制。 - 当落盘被触发时,TiDB 会在日志中打印一条包含关键字
memory exceeds quota, spill to disk now或memory exceeds quota, set aggregate mode to spill-mode的日志。 - Sort、MergeJoin、HashJoin 落盘是从 v4.0.0 版本开始引入的,HashAgg 落盘是从 v5.2.0 版本开始引入的。
- 当包含 Sort、MergeJoin 或 HashJoin 的 SQL 语句引起内存 OOM 时,TiDB 默认会触发落盘。当包含 HashAgg 算子的 SQL 语句引起内存 OOM 时,TiDB 默认不触发落盘,请设置系统变量
tidb_executor_concurrency = 1来触发 HashAgg 落盘功能。
本示例通过构造一个占用大量内存的 SQL 语句,对 HashAgg 落盘功能进行演示:
- 将 SQL 语句的 Memory Quota 配置为 1GB(默认 1GB):
```sql
SET tidb_mem_quota_query = 1 << 30;
```
创建单表
CREATE TABLE t(a int);并插入 256 行不同的数据。尝试执行以下 SQL 语句:
```sql
[tidb]> explain analyze select /*+ HASH_AGG() */ count(*) from t t1 join t t2 join t t3 group by t1.a, t2.a, t3.a;
```
该 SQL 语句占用大量内存,返回 Out of Memory Quota 错误。
```sql
ERROR 1105 (HY000): Out Of Memory Quota![conn_id=3]
```
- 设置系统变量
tidb_executor_concurrency将执行器的并发度调整为 1。在此配置下,内存不足时 HashAgg 会自动尝试触发落盘。
```sql
SET tidb_executor_concurrency = 1;
```
- 执行相同的 SQL 语句,不再返回错误,可以执行成功。从详细的执行计划可以看出,HashAgg 使用了 600MB 的硬盘空间。
```sql
[tidb]> explain analyze select /*+ HASH_AGG() */ count(*) from t t1 join t t2 join t t3 group by t1.a, t2.a, t3.a;
```
```sql
+---------------------------------+-------------+----------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------+-----------+----------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+---------------------------------+-------------+----------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------+-----------+----------+
| HashAgg_11 | 204.80 | 16777216 | root | | time:1m37.4s, loops:16385 | group by:test.t.a, test.t.a, test.t.a, funcs:count(1)->Column#7 | 1.13 GB | 600.0 MB |
| └─HashJoin_12 | 16777216.00 | 16777216 | root | | time:21.5s, loops:16385, build_hash_table:{total:267.2µs, fetch:228.9µs, build:38.2µs}, probe:{concurrency:1, total:35s, max:35s, probe:35s, fetch:962.2µs} | CARTESIAN inner join | 8.23 KB | 4 KB |
| ├─TableReader_21(Build) | 256.00 | 256 | root | | time:87.2µs, loops:2, cop_task: {num: 1, max: 150µs, proc_keys: 0, rpc_num: 1, rpc_time: 145.1µs, copr_cache_hit_ratio: 0.00} | data:TableFullScan_20 | 885 Bytes | N/A |
| │ └─TableFullScan_20 | 256.00 | 256 | cop[tikv] | table:t3 | tikv_task:{time:23.2µs, loops:256} | keep order:false, stats:pseudo | N/A | N/A |
| └─HashJoin_14(Probe) | 65536.00 | 65536 | root | | time:728.1µs, loops:65, build_hash_table:{total:307.5µs, fetch:277.6µs, build:29.9µs}, probe:{concurrency:1, total:34.3s, max:34.3s, probe:34.3s, fetch:278µs} | CARTESIAN inner join | 8.23 KB | 4 KB |
| ├─TableReader_19(Build) | 256.00 | 256 | root | | time:126.2µs, loops:2, cop_task: {num: 1, max: 308.4µs, proc_keys: 0, rpc_num: 1, rpc_time: 295.3µs, copr_cache_hit_ratio: 0.00} | data:TableFullScan_18 | 885 Bytes | N/A |
| │ └─TableFullScan_18 | 256.00 | 256 | cop[tikv] | table:t2 | tikv_task:{time:79.2µs, loops:256} | keep order:false, stats:pseudo | N/A | N/A |
| └─TableReader_17(Probe) | 256.00 | 256 | root | | time:211.1µs, loops:2, cop_task: {num: 1, max: 295.5µs, proc_keys: 0, rpc_num: 1, rpc_time: 279.7µs, copr_cache_hit_ratio: 0.00} | data:TableFullScan_16 | 885 Bytes | N/A |
| └─TableFullScan_16 | 256.00 | 256 | cop[tikv] | table:t1 | tikv_task:{time:71.4µs, loops:256} | keep order:false, stats:pseudo | N/A | N/A |
+---------------------------------+-------------+----------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------+-----------+----------+
9 rows in set (1 min 37.428 sec)
```
其它
设置环境变量 GOMEMLIMIT 缓解 OOM 问题
Golang 自 Go 1.19 版本开始引入 GOMEMLIMIT 环境变量,该变量用来设置触发 Go GC 的内存上限。
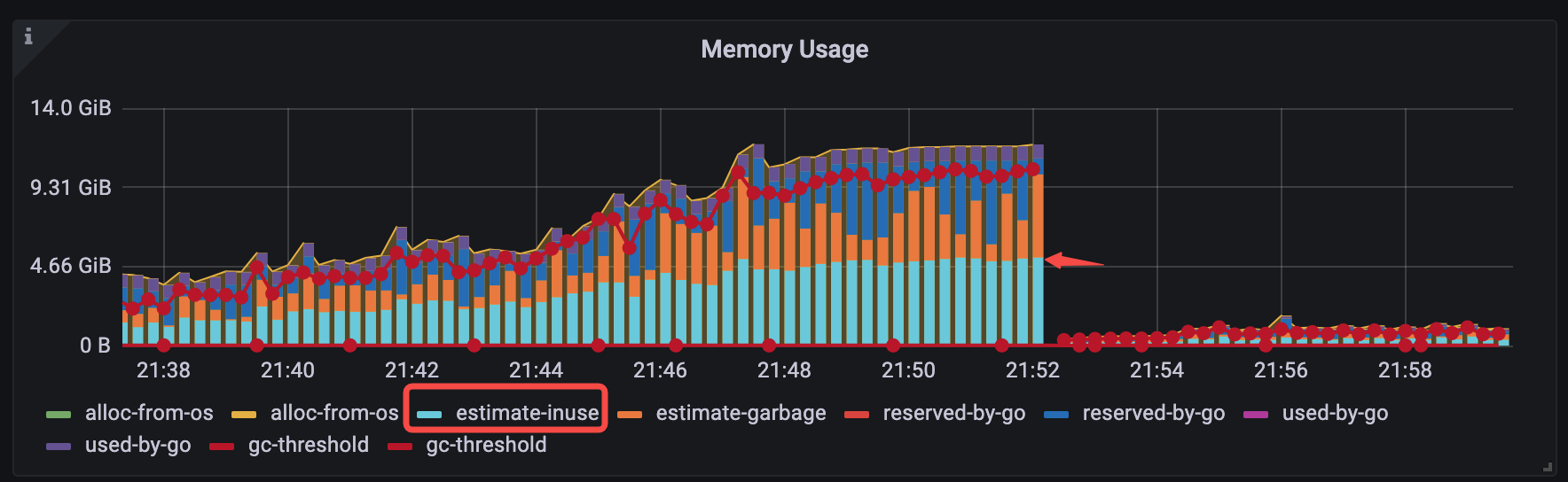
对于 v6.1.3 <= TiDB < v6.5.0 的版本,你可以通过手动设置 Go GOMEMLIMIT 环境变量的方式来缓解一类 OOM 问题。该类 OOM 问题具有一个典型特征:观察 Grafana 监控,OOM 前的时刻,TiDB-Runtime > Memory Usage 面板中 estimate-inuse 立柱部分在整个立柱中仅仅占一半。如下图所示:
为了验证 GOMEMLIMIT 在该类场景下的效果,以下通过一个对比实验进行说明:
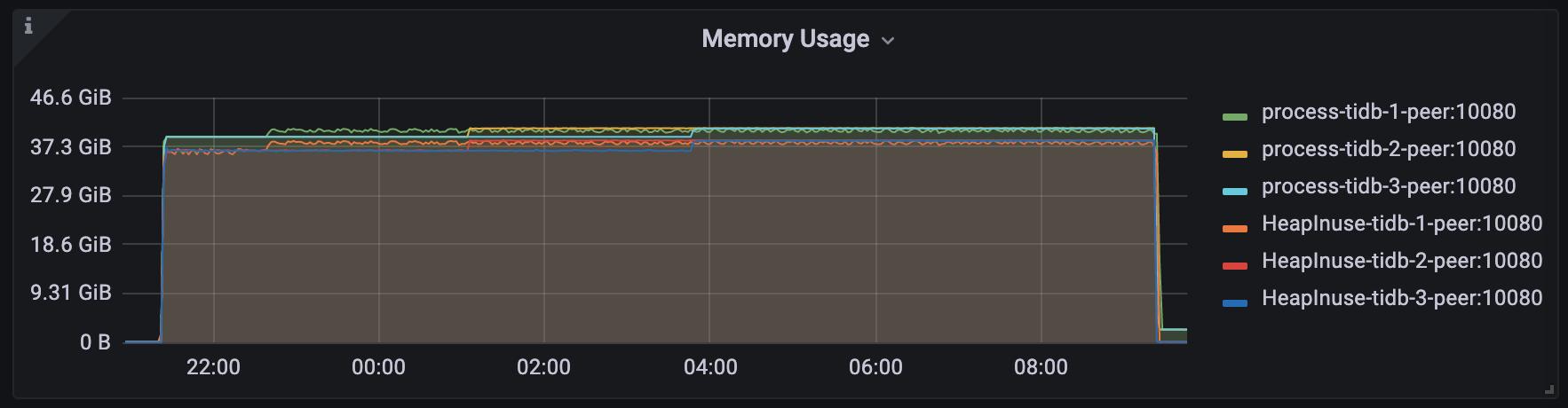
在 TiDB v6.1.2 下,模拟负载在持续运行几分钟后,TiDB server 会发生 OOM(系统内存约 48 GiB):
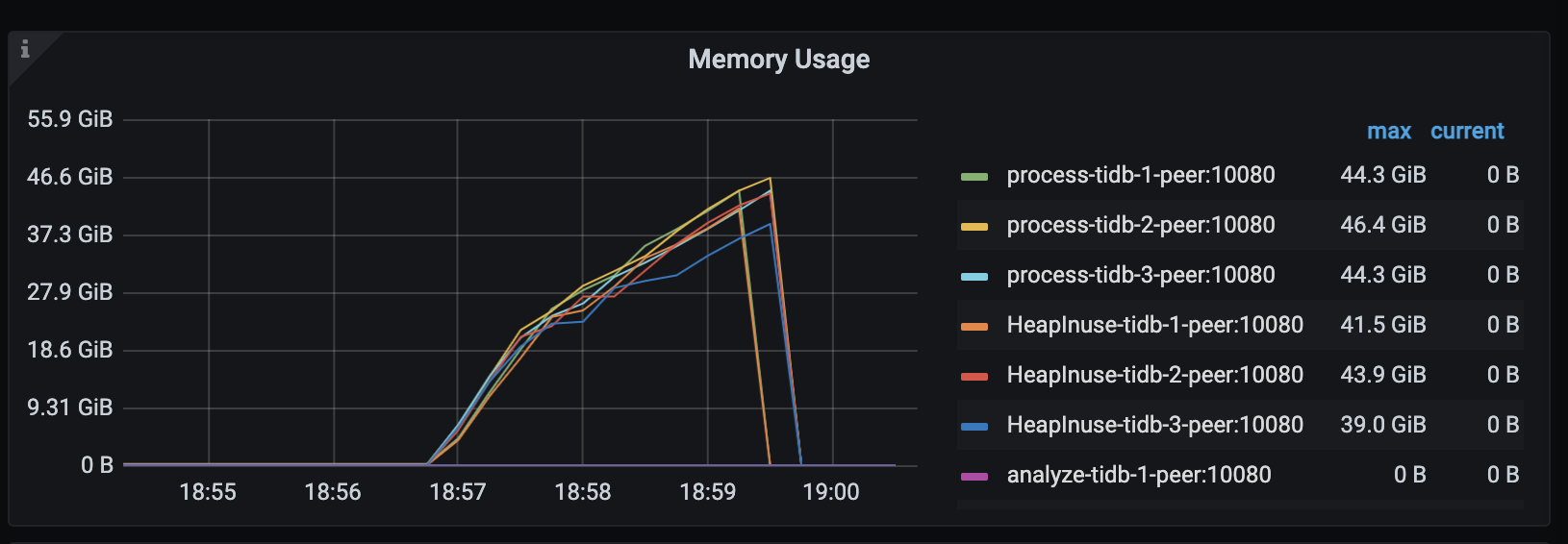
在 TiDB v6.1.3 下,设置
GOMEMLIMIT为 40000 MiB,模拟负载长期稳定运行、TiDB server 未发生 OOM 且进程最高内存用量稳定在 40.8 GiB 左右: