Placement Rules 使用文档
Placement Rules 是 PD 在 4.0 版本引入的一套副本规则系统,用于指导 PD 针对不同类型的数据生成对应的调度。通过组合不同的调度规则,用户可以精细地控制任何一段连续数据的副本数量、存放位置、主机类型、是否参与 Raft 投票、是否可以担任 Raft leader 等属性。
Placement Rules 特性在 TiDB v5.0 及以上的版本中默认开启。如需关闭 Placement Rules 特性,请参考关闭 Placement Rules。
规则系统介绍
整个规则系统的配置由多条规则即 Rule 组成。每条 Rule 可以指定不同的副本数量、Raft 角色、放置位置等属性,以及这条规则生效的 key range。PD 在进行调度时,会先根据 Region 的 key range 在规则系统中查到该 Region 对应的规则,然后再生成对应的调度,来使得 Region 副本的分布情况符合 Rule。
多条规则的 key range 可以有重叠部分的,即一个 Region 能匹配到多条规则。这种情况下 PD 根据 Rule 的属性来决定规则是相互覆盖还是同时生效。如果有多条规则同时生效,PD 会按照规则的堆叠次序依次去生成调度进行规则匹配。
此外,为了满足不同来源的规则相互隔离的需求,支持更灵活的方式来组织规则,还引入了分组 (Group) 的概念。通常情况下,用户可根据规则的不同来源把规则放置在不同的 Group。
Placement Rules 示意图如下所示:
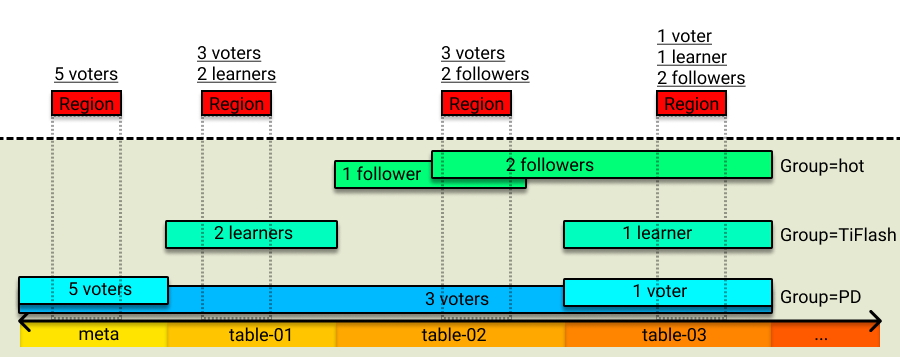
规则字段
以下是每条规则中各个字段的具体含义:
| 字段名 | 类型及约束 | 说明 |
|---|---|---|
GroupID | string | 分组 ID,标识规则的来源 |
ID | string | 分组内唯一 ID |
Index | int | 分组内堆叠次序 |
Override | true/false | 是否覆盖 index 的更小 Rule(限分组内) |
StartKey | string,十六进制编码 | 适用 Range 起始 key |
EndKey | string,十六进制编码 | 适用 Range 终止 key |
Role | string | 副本角色,包括 voter/leader/follower/learner |
Count | int,正整数 | 副本数量 |
LabelConstraint | []Constraint | 用于按 label 筛选节点 |
LocationLabels | []string | 用于物理隔离 |
IsolationLevel | string | 用于设置最小强制物理隔离级别 |
LabelConstraint 与 Kubernetes 中的功能类似,支持通过 in、notIn、exists 和 notExists 四种原语来筛选 label。这四种原语的意义如下:
in:给定 key 的 label value 包含在给定列表中。notIn:给定 key 的 label value 不包含在给定列表中。exists:包含给定的 label key。notExists:不包含给定的 label key。
LocationLabels 的意义和作用与 PD v4.0 之前的版本相同。比如配置 [zone,rack,host] 定义了三层的拓扑结构:集群分为多个 zone(可用区),每个 zone 下有多个 rack(机架),每个 rack 下有多个 host(主机)。PD 在调度时首先会尝试将 Region 的 Peer 放置在不同的 zone,假如无法满足(比如配置 3 副本但总共只有 2 个 zone)则保证放置在不同的 rack;假如 rack 的数量也不足以保证隔离,那么再尝试 host 级别的隔离,以此类推。
IsolationLevel 的意义和作用详细请参考配置集群拓扑。例如已配置 LocationLabels 为 [zone,rack,host] 的前提下,设置 IsolationLevel 为 zone,则 PD 在调度时会保证每个 Region 的所有 Peer 均被放置在不同的 zone。假如无法满足 IsolationLevel 的最小强制隔离级别限制(比如配置 3 副本但总共只有 2 个 zone),PD 也不会尝试补足,以满足该限制。IsolationLevel 默认值为空字符串,即禁用状态。
规则分组字段
以下是规则分组字段的含义:
| 字段名 | 类型及约束 | 说明 |
|---|---|---|
ID | string | 分组 ID,用于标识规则来源 |
Index | int | 不同分组的堆叠次序 |
Override | true/false | 是否覆盖 index 更小的分组 |
如果不单独设置规则分组,默认 Override=false,对应的行为是不同分组之间相互不影响,不同分组内的规则是同时生效的。
配置规则操作步骤
本节的操作步骤以使用 pd-ctl 工具为例,涉及到的命令也支持通过 HTTP API 进行调用。
开启 Placement Rules 特性
Placement Rules 特性在 TiDB v5.0 及以上的版本中默认开启。如需关闭 Placement Rules 特性,请参考关闭 Placement Rules。如需在关闭后重新开启该特性,可以集群初始化以前设置 PD 配置文件:
[replication]
enable-placement-rules = true
这样,PD 在初始化成功后会开启这个特性,并根据 max-replicas 及 location-labels 配置生成对应的规则:
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3,
"location_labels": ["zone", "rack", "host"],
"isolation_level": ""
}
如果是已经初始化过的集群,也可以通过 pd-ctl 进行在线开启:
pd-ctl config placement-rules enable
PD 同样将根据系统的 max-replicas 及 location-labels 生成默认的规则。
关闭 Placement Rules 特性
使用 pd-ctl 可以关闭 Placement Rules 特性,切换为之前的调度策略。
pd-ctl config placement-rules disable
使用 pd-ctl 设置规则
pd-ctl 支持使用多种方式查看系统中的 Rule,输出是 json 格式的 Rule 或 Rule 列表:
- 查看所有规则列表
```bash
pd-ctl config placement-rules show
```
- 查看 PD Group 的所有规则列表
```bash
pd-ctl config placement-rules show --group=pd
```
- 查看对应 Group 和 ID 的某条规则
```bash
pd-ctl config placement-rules show --group=pd --id=default
```
- 查看 Region 所匹配的规则列表
```bash
pd-ctl config placement-rules show --region=2
```
上面的例子中 `2` 为 Region ID。
新增和编辑规则是类似的,需要把对应的规则写进文件,然后使用 save 命令保存至 PD:
cat > rules.json <<EOF
[
{
"group_id": "pd",
"id": "rule1",
"role": "voter",
"count": 3,
"location_labels": ["zone", "rack", "host"]
},
{
"group_id": "pd",
"id": "rule2",
"role": "voter",
"count": 2,
"location_labels": ["zone", "rack", "host"]
}
]
EOF
pd-ctl config placement save --in=rules.json
以上操作会将 rule1、rule2 两条规则写入 PD,如果系统中已经存在 GroupID+ID 相同的规则,则会覆盖该规则。
如果需要删除某条规则,只需要将规则的 count 置为 0 即可,对应 GroupID+ID 相同的规则会被删除。以下命令将删除 pd/rule2 这条规则:
cat > rules.json <<EOF
[
{
"group_id": "pd",
"id": "rule2"
}
]
EOF
pd-ctl config placement save --in=rules.json
使用 pd-ctl 设置规则分组
- 查看所有的规则分组列表
```bash
pd-ctl config placement-rules rule-group show
```
- 查看指定 ID 的规则分组
```bash
pd-ctl config placement-rules rule-group show pd
```
- 设置规则分组的 index 和 override 属性
```bash
pd-ctl config placement-rules rule-group set pd 100 true
```
- 删除规则分组配置(如组内还有规则,则使用默认分组配置)
```bash
pd-ctl config placement-rules rule-group delete pd
```
使用 pd-ctl 批量更新分组及组内规则
使用 rule-bundle 子命令,可以方便地同时查看和修改规则分组及组内的所有规则。
该子命令中 get {group_id} 用来查询一个分组,输出结果为嵌套形式的规则分组和组内规则:
pd-ctl config placement-rules rule-bundle get pd
输出示例:
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3
}
]
}
rule-bundle get 子命令中可以添加 --out 参数来将输出写入文件,方便后续修改保存。
pd-ctl config placement-rules rule-bundle get pd --out="group.json"
修改完成后,使用 rule-bundle set 子命令将文件中的配置保存至 PD 服务器。与前面介绍的 save 不同,此命令会替换服务器端该分组内的所有规则。
pd-ctl config placement-rules rule-bundle set pd --in="group.json"
使用 pd-ctl 查看和修改所有配置
用户还可以使用 pd-ctl 查看和修改所有配置,即把全部配置保存至文件,修改后再覆盖保存。该操作同样使用 rule-bundle 子命令。
下面的命令将所有配置保存至 rules.json 文件:
pd-ctl config placement-rules rule-bundle load --out="rules.json"
编辑完文件后,使用下面的命令将配置保存至 PD 服务器:
pd-ctl config placement-rules rule-bundle save --in="rules.json"
使用 tidb-ctl 查询表相关的 key range
若需要针对元数据或某个特定的表进行特殊配置,可以通过 tidb-ctl 的 keyrange 命令来查询相关的 key。注意要添加 --encode 返回 PD 中的表示形式。
tidb-ctl keyrange --database test --table ttt --encode
global ranges:
meta: (6d00000000000000f8, 6e00000000000000f8)
table: (7400000000000000f8, 7500000000000000f8)
table ttt ranges: (NOTE: key range might be changed after DDL)
table: (7480000000000000ff2d00000000000000f8, 7480000000000000ff2e00000000000000f8)
table indexes: (7480000000000000ff2d5f690000000000fa, 7480000000000000ff2d5f720000000000fa)
index c2: (7480000000000000ff2d5f698000000000ff0000010000000000fa, 7480000000000000ff2d5f698000000000ff0000020000000000fa)
index c3: (7480000000000000ff2d5f698000000000ff0000020000000000fa, 7480000000000000ff2d5f698000000000ff0000030000000000fa)
index c4: (7480000000000000ff2d5f698000000000ff0000030000000000fa, 7480000000000000ff2d5f698000000000ff0000040000000000fa)
table rows: (7480000000000000ff2d5f720000000000fa, 7480000000000000ff2e00000000000000f8)
典型场景示例
本部分介绍 Placement Rules 的使用场景示例。
场景一:普通的表使用 3 副本,元数据使用 5 副本提升集群容灾能力
只需要增加一条规则,将 key range 限定在 meta 数据的范围,并把 count 值设为 5。添加规则示例如下:
{
"group_id": "pd",
"id": "meta",
"index": 1,
"override": true,
"start_key": "6d00000000000000f8",
"end_key": "6e00000000000000f8",
"role": "voter",
"count": 5,
"location_labels": ["zone", "rack", "host"]
}
场景二:5 副本按 2-2-1 的比例放置在 3 个数据中心,且第 3 个中心不产生 Leader
创建三条规则,分别设置副本数为 2、2、1,并且在每个规则内通过 label_constraints 将副本限定在对应的数据中心内。另外,不需要 leader 的数据中心将 role 改为 follower。
[
{
"group_id": "pd",
"id": "zone1",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 2,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone1"]}
],
"location_labels": ["rack", "host"]
},
{
"group_id": "pd",
"id": "zone2",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 2,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone2"]}
],
"location_labels": ["rack", "host"]
},
{
"group_id": "pd",
"id": "zone3",
"start_key": "",
"end_key": "",
"role": "follower",
"count": 1,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone3"]}
],
"location_labels": ["rack", "host"]
}
]
场景三:为某张表添加 2 个 TiFlash Learner 副本
为表的 row key 单独添加一条规则,限定数量为 2,并且通过 label_constraints 保证副本产生在 engine=tiflash 的节点。注意这里使用了单独的 group_id,保证这条规则不会与系统中其他来源的规则互相覆盖或产生冲突。
{
"group_id": "tiflash",
"id": "learner-replica-table-ttt",
"start_key": "7480000000000000ff2d5f720000000000fa",
"end_key": "7480000000000000ff2e00000000000000f8",
"role": "learner",
"count": 2,
"label_constraints": [
{"key": "engine", "op": "in", "values": ["tiflash"]}
],
"location_labels": ["host"]
}
场景四:为某张表在有高性能磁盘的北京节点添加 2 个 Follower 副本
这个例子展示了比较复杂的 label_constraints 配置,下面的例子限定了副本放置在 bj1 或 bj2 机房,且磁盘类型为 nvme。
{
"group_id": "follower-read",
"id": "follower-read-table-ttt",
"start_key": "7480000000000000ff2d00000000000000f8",
"end_key": "7480000000000000ff2e00000000000000f8",
"role": "follower",
"count": 2,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["bj1", "bj2"]},
{"key": "disk", "op": "in", "values": ["nvme"]}
],
"location_labels": ["host"]
}
场景五:将某张表迁移至 SSD 节点
与场景三不同,这个场景不是要在原有配置的基础上增加新副本,而是要强制覆盖一段数据的其它配置,因此需要通过配置规则分组来指定一个足够大的 index 以及设置 override 来覆盖原有规则。
规则:
{
"group_id": "ssd-override",
"id": "ssd-table-45",
"start_key": "7480000000000000ff2d5f720000000000fa",
"end_key": "7480000000000000ff2e00000000000000f8",
"role": "voter",
"count": 3,
"label_constraints": [
{"key": "disk", "op": "in", "values": ["ssd"]}
],
"location_labels": ["rack", "host"]
}
规则分组:
{
"id": "ssd-override",
"index": 1024,
"override": true,
}