三节点混合部署的最佳实践
在对性能要求不高且需要控制成本的场景下,将 TiDB、TiKV、PD 混合部署在三台机器上是一个可行的方案。
本文以 TPC-C 作为工作负载,提供一些在三节点混合部署场景下部署和参数调整的建议。
部署环境和测试方法
三台物理机,每台机器有 16 个 CPU 核心且内存为 32 GB。每节点(台机器)上混合部署 1 TiDB (实例)+ 1 TiKV (实例)+ 1 PD(实例)。
由于 PD 和 TiKV 都会存储信息到磁盘,磁盘的写入读取延迟会直接影响到 PD 和 TiKV 的服务延迟,为了防止 PD 和 TiKV 对磁盘资源的争抢导致相互影响,推荐 PD 和 TiKV 采用不同的磁盘。
在 TiUP bench 中使用 TPC-C 5000 Warehouse 数据,每次以 terminals 参数为 128 的并发度测试 12 小时。主要观察集群性能的稳定性指标。
下图是默认参数配置下,12 小时内集群的 QPS 监控,可以看倒有比较明显的抖动。

调整参数后,稳定性得到了改善。

参数调整
上图中出现抖动的主要原因是,默认的线程池和后台任务资源分配针对的是资源比较充足的机器。在混合部署的场景下,因为可用资源需要被多个组件共享,所以需要通过配置参数进行限制。
本次测试最终采用的配置如下:
tikv:
readpool.unified.max-thread-count: 6
server.grpc-concurrency: 2
storage.scheduler-worker-pool-size: 2
gc.max-write-bytes-per-sec: 300K
rocksdb.max-background-jobs: 3
rocksdb.max-sub-compactions: 1
rocksdb.rate-bytes-per-sec: “200M”
tidb:
performance.committer-concurrency: 4
performance.max-procs: 8
接下来会分别介绍这几个参数的意义和调整方法。
TiKV 线程池大小配置
本节的配置项会调整一些与前台业务有关的线程池的资源配比。缩减这些线程池会损失一些性能,但在混合部署场景下可用资源有限,本身也难以达到很高的性能,所以选择牺牲一小部分性能去换取整体的稳定性。
可以先以默认配置为基础运行一次实际负载的测试,观察各线程池的实际使用量,再修改这些配置项,缩减利用率不高的线程池大小。
readpool.unified.max-thread-count
该参数默认取值为机器线程数的 80%,因为是混合部署场景,你需要手动计算并指定该值。可以先设置成期望 TiKV 使用的 CPU 线程数的 80%。
server.grpc-concurrency
该参数默认为 4。因为现有部署方案的 CPU 资源有限,实际请求数也不会很多。可以把该参数值调低,后续观察监控面板保持其使用率在 80% 以下即可。
本次测试最后选择设置该参数值为 2,通过 gRPC poll CPU 面板观察,利用率正好在 80% 左右。

storage.scheduler-worker-pool-size
在 TiKV 检测到机器 CPU 数大于或等于 16 时,该参数值默认为 8。CPU 数小于 16 时,该参数值默认为 4。它主要用于将复杂的事务请求转化为简单的 key-value 读写。但是 scheduler 线程池本身不进行任何写操作。
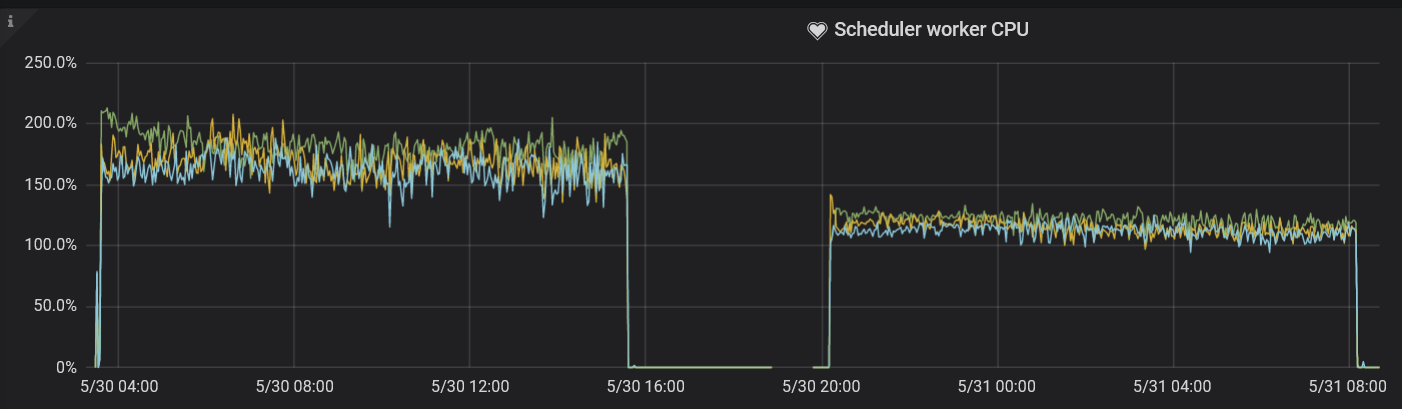
一般来说该线程池的利用率保持在 50% - 75% 之间是比较好的。和 gRPC 线程池情况类似,混合部署时该参数默认取值偏大,资源利用不充分。本次测试最后选择取值为 2,通过 Scheduler worker CPU 面板观察,利用率比较符合最佳实践。
TiKV 后台任务资源配置
除前台任务之外,TiKV 上还会持续地有后台任务进行数据整理和过期数据的清除。默认配置为这些后台任务分配了比较多的资源以应对大流量的写入。
混合部署场景下,默认配置就不是很合适了,需要通过以下参数对这些后台任务地资源使用量进行限制。
rocksdb.max-background-jobs 和 rocksdb.max-sub-compactions
RocksDB 线程池是进行 Compact 和 Flush 任务的线程池,默认大小为 8。这明显超出了实际可以使用的资源,需要限制。rocksdb.max-sub-compactions 是单个 compaction 任务的子任务并发数,默认值为 3,在写入流量不大的情况下可以进行限制。
这次测试最终将 rocksdb.max-background-jobs 设置为 3,将 rocksdb.max-sub-compactions 设置为 1。在 12 小时的 TPC-C 负载下没有发生 Write Stall,根据实际负载进行这两项参数的优化时,可以逐步调低这两个配置,并通过监控观察。
- 如果遇到了 Write Stall,可以先调大
rocksdb.max-background-jobs的取值。 - 如果还是存在问题,可将
rocksdb.max-sub-compactions设置为 2 或者 3。
rocksdb.rate-bytes-per-sec
该参数用于限制后台 compaction 任务的磁盘流量。默认配置下没有进行任何限制。为了避免 compaction 挤占前台服务资源,可以根据硬盘的顺序读写速度进行调整,为正常的服务保留足够多的磁盘带宽。
类似 compaction 线程池的调整方法,调整该参数值后,也根据是否存在 Write Stall 来判断取值是否合理。
gc.max_write_bytes_per_sec
因为 TiDB 使用的是 MVCC 的模型,TiKV 还需要周期性地在后台清除旧版本的数据。当可用资源有限的时候,这个操作会引起周期性的性能抖动。可以用 gc.max_write_bytes_per_sec 来限制这一操作的资源使用。

除了在配置文件中设置该参数之外,还可以通过 tikv-ctl 动态调节,为调整该参数提供便利:
tiup ctl:<cluster-version> tikv --host=${ip:port} modify-tikv-config -n gc.max_write_bytes_per_sec -v ${limit}
TiDB 参数调整
一般通过系统变量调整 TiDB 执行算子的优化参数,例如 tidb_hash_join_concurrency、tidb_index_lookup_join_concurrency 等。
本测试中没有对这些参数进行调整。如果实际的业务负载测试中,出现执行算子消耗过多 CPU 资源的情况,可以针对业务场景对特定的算子资源使用量进行限制。这部分内容可以参考 TiDB 系统变量文档。
performance.max-procs
该参数控制着整个 Go 进程能使用的 CPU 核心数量,默认情况下为当前机器或者 cgroups 的 CPU 数量。
Go 运行时会定期使用一定比例的线程进行 GC 等后台工作。在混合部署模式下,如果不对这一参数进行限制,GC 等后台操作会过多占用 CPU 资源。