使用 Dumpling 导出数据
使用数据导出工具 Dumpling,你可以把存储在 TiDB 或 MySQL 中的数据导出为 SQL 或 CSV 格式,用于逻辑全量备份。Dumpling 也支持将数据导出到 Amazon S3 中。
下图展示了使用 Dumpling 导出数据的场景。
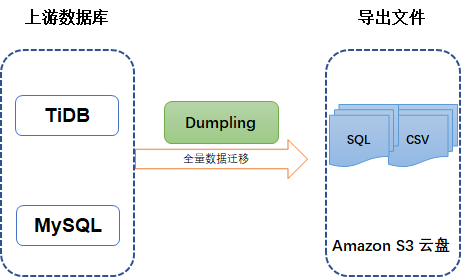
要快速了解 Dumpling 的基本功能,建议先观看下面的培训视频(时长 28 分钟)。注意本视频只作为功能介绍、学习参考,具体操作步骤和最新功能,请以文档内容为准。
你可以通过下列任意方式获取 Dumpling:
- TiUP 执行
tiup install dumpling命令。获取后,使用tiup dumpling ...命令运行 Dumpling。 - 下载包含 Dumpling 的 tidb-toolkit 安装包。
更多详情,可以使用 --help 选项查看,或参考 Dumpling 主要选项表。
使用 Dumpling 时,需要在已经启动的集群上执行导出命令。
TiDB 还提供了其他工具,你可以根据需要选择使用:
- 如果需要直接备份 SST 文件(键值对),或者对延迟不敏感的增量备份,请使用备份工具 BR。
- 如果需要实时的增量备份,请使用 TiCDC。
- 所有的导出数据都可以用 TiDB Lightning 导回到 TiDB。
相比 Mydumper,Dumpling 做了如下改进:
- 支持导出多种数据形式,包括 SQL/CSV。
- 支持全新的 table-filter,筛选数据更加方便。
- 支持导出到 Amazon S3 云盘。
- 针对 TiDB 进行了更多优化:
- 支持配置 TiDB 单条 SQL 内存限制。
- 针对 TiDB v4.0.0 及更新版本支持自动调整 TiDB GC 时间。
- 使用 TiDB 的隐藏列
_tidb_rowid优化了单表内数据的并发导出性能。 - 对于 TiDB 可以设置 tidb_snapshot 的值指定备份数据的时间点,从而保证备份的一致性,而不是通过
FLUSH TABLES WITH READ LOCK来保证备份一致性。
从 TiDB/MySQL 导出数据
需要的权限
- SELECT
- RELOAD
- LOCK TABLES
- REPLICATION CLIENT
导出为 SQL 文件
本文假设在 127.0.0.1:4000 有一个 TiDB 实例,并且这个 TiDB 实例中有无密码的 root 用户。
Dumpling 默认导出数据格式为 SQL 文件。也可以通过设置 --filetype sql 导出数据到 SQL 文件:
dumpling \
-u root \
-P 4000 \
-h 127.0.0.1 \
--filetype sql \
-t 8 \
-o /tmp/test \
-r 200000 \
-F 256MiB
以上命令中:
-h、-P、-u分别代表地址、端口、用户。如果需要密码验证,可以使用-p $YOUR_SECRET_PASSWORD将密码传给 Dumpling。-o用于选择存储导出文件的目录,支持本地文件路径或外部存储 URL 格式。-t用于指定导出的线程数。增加线程数会增加 Dumpling 并发度提高导出速度,但也会加大数据库内存消耗,因此不宜设置过大。一般不超过 64。-r用于指定单个文件的最大行数,指定该参数后 Dumpling 会开启表内并发加速导出,同时减少内存使用。-F选项用于指定单个文件的最大大小,单位为MiB,可接受类似5GiB或8KB的输入。如果你想使用 TiDB Lightning 将该文件加载到 TiDB 实例中,建议将-F选项的值保持在 256 MiB 或以下。
导出为 CSV 文件
假如导出数据的格式是 CSV(使用 --filetype csv 即可导出 CSV 文件),还可以使用 --sql <SQL> 导出指定 SQL 选择出来的记录,例如,导出 test.sbtest1 中所有 id < 100 的记录:
./dumpling \
-u root \
-P 4000 \
-h 127.0.0.1 \
-o /tmp/test \
--filetype csv \
--sql 'select * from `test`.`sbtest1` where id < 100'
输出文件格式
metadata:此文件包含导出的起始时间,以及 master binary log 的位置。
```shell
cat metadata
```
```shell
Started dump at: 2020-11-10 10:40:19
SHOW MASTER STATUS:
Log: tidb-binlog
Pos: 420747102018863124
Finished dump at: 2020-11-10 10:40:20
```
{schema}-schema-create.sql:创建 schema 的 SQL 文件。
```shell
cat test-schema-create.sql
```
```shell
CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET utf8mb4 */;
```
{schema}.{table}-schema.sql:创建 table 的 SQL 文件
```shell
cat test.t1-schema.sql
```
```shell
CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
```
{schema}.{table}.{0001}.{sql|csv}:数据源文件
```shell
cat test.t1.0.sql
```
```shell
/*!40101 SET NAMES binary*/;
INSERT INTO `t1` VALUES
(1);
```
*-schema-view.sql、*-schema-trigger.sql、*-schema-post.sql:其他导出文件
导出到 Amazon S3 云盘
Dumpling 在 v4.0.8 及更新版本支持导出到 Amazon S3 云盘。如果需要将数据备份到 Amazon S3 后端存储,那么需要在 -o 参数中指定 Amazon S3 的存储路径。
可以参照 AWS 官方文档 - 如何创建 S3 存储桶在指定的 Region 区域中创建一个 S3 桶 Bucket。如有需要,还可以参照 AWS 官方文档 - 创建文件夹在 Bucket 中创建一个文件夹 Folder。
将有权限访问该 Amazon S3 后端存储的账号的 SecretKey 和 AccessKey 作为环境变量传入 Dumpling 节点。
export AWS_ACCESS_KEY_ID=${AccessKey}
export AWS_SECRET_ACCESS_KEY=${SecretKey}
Dumpling 同时还支持从 ~/.aws/credentials 读取凭证文件。更多 Dumpling 存储配置可以参考外部存储。
在进行 Dumpling 备份时,显式指定参数 --s3.region,即表示 Amazon S3 存储所在的区域,例如 ap-northeast-1。
./dumpling \
-u root \
-P 4000 \
-h 127.0.0.1 \
-r 200000 \
-o "s3://${Bucket}/${Folder}" \
--s3.region "${region}"
筛选导出的数据
使用 --where 选项筛选数据
默认情况下,Dumpling 会导出排除系统数据库(包括 mysql 、sys 、INFORMATION_SCHEMA 、PERFORMANCE_SCHEMA、METRICS_SCHEMA 和 INSPECTION_SCHEMA)外所有其他数据库。你可以使用 --where <SQL where expression> 来指定要导出的记录。
./dumpling \
-u root \
-P 4000 \
-h 127.0.0.1 \
-o /tmp/test \
--where "id < 100"
上述命令将会导出各个表的 id < 100 的数据。注意 --where 参数无法与 --sql 一起使用。
使用 --filter 选项筛选数据
Dumpling 可以通过 --filter 指定 table-filter 来筛选特定的库表。table-filter 的语法与 .gitignore 相似,详细语法参考表库过滤。
./dumpling \
-u root \
-P 4000 \
-h 127.0.0.1 \
-o /tmp/test \
-r 200000 \
--filter "employees.*" \
--filter "*.WorkOrder"
上述命令将会导出 employees 数据库的所有表,以及所有数据库中的 WorkOrder 表。
使用 -B 或 -T 选项筛选数据
Dumpling 也可以通过 -B 或 -T 选项导出特定的数据库/数据表。
例如通过指定:
-B employees导出employees数据库-T employees.WorkOrder导出employees.WorkOrder数据表
通过并发提高 Dumpling 的导出效率
默认情况下,导出的文件会存储到 ./export-<current local time> 目录下。常用选项如下:
-t用于指定导出的线程数。增加线程数会增加 Dumpling 并发度提高导出速度,但也会加大数据库内存消耗,因此不宜设置过大。-r选项用于指定单个文件的最大记录数,或者说,数据库中的行数。开启后 Dumpling 会开启表内并发,提高导出大表的速度。当上游为 TiDB 且版本为 v3.0 或更新版本时,该参数大于 0 表示使用 TiDB region 信息划分表内并发,具体取值将不再生效。--compress gzip选项可以用于压缩导出的数据。压缩可以显著降低导出数据的大小,同时如果存储的写入 I/O 带宽不足,可以使用该选项来加速导出。但该选项也有副作用,由于该选项会对每个文件单独压缩,因此会增加 CPU 消耗。
利用以上选项可以提高 Dumpling 的导出速度。
调整 Dumpling 的数据一致性选项
Dumpling 通过 --consistency <consistency level> 标志控制导出数据“一致性保证”的方式。对于 TiDB 来说,默认情况下,会通过获取某个时间戳的快照来保证一致性(即 --consistency snapshot)。在使用 snapshot 来保证一致性的时候,可以使用 --snapshot 选项指定要备份的时间戳。还可以使用以下的一致性级别:
flush:使用FLUSH TABLES WITH READ LOCK短暂地中断备份库的 DML 和 DDL 操作、保证备份连接的全局一致性和记录 POS 信息。所有的备份连接启动事务后释放该锁。推荐在业务低峰或者 MySQL 备份库上进行全量备份。snapshot:获取指定时间戳的一致性快照并导出。lock:为待导出的所有表上读锁。none:不做任何一致性保证。auto:对 MySQL 使用flush,对 TiDB 使用snapshot。
操作完成之后,你可以在 /tmp/test 查看导出的文件:
$ ls -lh /tmp/test | awk '{print $5 "\t" $9}'
140B metadata
66B test-schema-create.sql
300B test.sbtest1-schema.sql
190K test.sbtest1.0.sql
300B test.sbtest2-schema.sql
190K test.sbtest2.0.sql
300B test.sbtest3-schema.sql
190K test.sbtest3.0.sql
导出 TiDB 的历史数据快照
Dumpling 可以通过 --snapshot 指定导出某个 tidb_snapshot 的数据。
--snapshot 选项可设为 TSO(SHOW MASTER STATUS 输出的 Position 字段)或有效的 datetime 时间(YYYY-MM-DD hh:mm:ss 形式),例如:
./dumpling --snapshot 417773951312461825
./dumpling --snapshot "2020-07-02 17:12:45"
即可导出 TSO 为 417773951312461825 或 2020-07-02 17:12:45 时的 TiDB 历史数据快照。
控制导出 TiDB 大表时的内存使用
Dumpling 导出 TiDB 较大单表时,可能会因为导出数据过大导致 TiDB 内存溢出 (OOM),从而使连接中断导出失败。可以通过以下参数减少 TiDB 的内存使用。
- 设置
-r参数,可以划分导出数据区块减少 TiDB 扫描数据的内存开销,同时也可开启表内并发提高导出效率。 - 调小
--tidb-mem-quota-query参数到8589934592(8GB) 或更小。可控制 TiDB 单条查询语句的内存使用。 - 调整
--params "tidb_distsql_scan_concurrency=5"参数,即设置导出时的 session 变量tidb_distsql_scan_concurrency从而减少 TiDB scan 操作的并发度。
导出大规模数据时的 TiDB GC 设置
如果导出的 TiDB 版本为 v4.0.0 或更新版本,并且 Dumpling 可以访问 TiDB 集群的 PD 地址,Dumpling 会自动配置延长 GC 时间且不会对原集群造成影响。
其他情况下,假如导出的数据量非常大,可以提前调长 GC 时间,以避免因为导出过程中发生 GC 导致导出失败:
SET GLOBAL tidb_gc_life_time = '720h';
操作结束之后,再恢复 GC 时间为默认值 10m:
SET GLOBAL tidb_gc_life_time = '10m';
Dumpling 主要选项表
| 主要选项 | 用途 | 默认值 |
|---|---|---|
| -V 或 --version | 输出 Dumpling 版本并直接退出 | |
| -B 或 --database | 导出指定数据库 | |
| -T 或 --tables-list | 导出指定数据表 | |
| -f 或 --filter | 导出能匹配模式的表,语法可参考 table-filter | [\*.\*,!/^(mysql|sys|INFORMATION_SCHEMA|PERFORMANCE_SCHEMA|METRICS_SCHEMA|INSPECTION_SCHEMA)$/.\*](导出除系统库外的所有库表) |
| --case-sensitive | table-filter 是否大小写敏感 | false,大小写不敏感 |
| -h 或 --host | 连接的数据库主机的地址 | "127.0.0.1" |
| -t 或 --threads | 备份并发线程数 | 4 |
| -r 或 --rows | 将 table 划分成 row 行数据,一般针对大表操作并发生成多个文件。 | |
| -L 或 --logfile | 日志输出地址,为空时会输出到控制台 | "" |
| --loglevel | 日志级别 {debug,info,warn,error,dpanic,panic,fatal} | "info" |
| --logfmt | 日志输出格式 {text,json} | "text" |
| -d 或 --no-data | 不导出数据,适用于只导出 schema 场景 | |
| --no-header | 导出 csv 格式的 table 数据,不生成 header | |
| -W 或 --no-views | 不导出 view | true |
| -m 或 --no-schemas | 不导出 schema,只导出数据 | |
| -s 或--statement-size | 控制 INSERT SQL 语句的大小,单位 bytes | |
| -F 或 --filesize | 将 table 数据划分出来的文件大小,需指明单位(如 128B, 64KiB, 32MiB, 1.5GiB) | |
| --filetype | 导出文件类型(csv/sql) | "sql" |
| -o 或 --output | 导出本地文件路径或外部存储 URL | "./export-${time}" |
| -S 或 --sql | 根据指定的 sql 导出数据,该选项不支持并发导出 | |
| --consistency | flush: dump 前用 FTWRL snapshot: 通过 TSO 来指定 dump 某个快照时间点的 TiDB 数据 lock: 对需要 dump 的所有表执行 lock tables read 命令 none: 不加锁 dump,无法保证一致性 auto: 对 MySQL 使用 --consistency flush;对 TiDB 使用 --consistency snapshot | "auto" |
| --snapshot | snapshot tso,只在 consistency=snapshot 下生效 | |
| --where | 对备份的数据表通过 where 条件指定范围 | |
| -p 或 --password | 连接的数据库主机的密码 | |
| -P 或 --port | 连接的数据库主机的端口 | 4000 |
| -u 或 --user | 连接的数据库主机的用户名 | "root" |
| --dump-empty-database | 导出空数据库的建库语句 | true |
| --ca | 用于 TLS 连接的 certificate authority 文件的地址 | |
| --cert | 用于 TLS 连接的 client certificate 文件的地址 | |
| --key | 用于 TLS 连接的 client private key 文件的地址 | |
| --csv-delimiter | csv 文件中字符类型变量的定界符 | '"' |
| --csv-separator | csv 文件中各值的分隔符,如果数据中可能有逗号,建议源文件导出时分隔符使用非常见组合字符 | ',' |
| --csv-null-value | csv 文件空值的表示 | "\N" |
| --escape-backslash | 使用反斜杠 (\) 来转义导出文件中的特殊字符 | true |
| --output-filename-template | 以 golang template 格式表示的数据文件名格式 支持 {{.DB}}、{{.Table}}、{{.Index}} 三个参数 分别表示数据文件的库名、表名、分块 ID | '{{.DB}}.{{.Table}}.{{.Index}}' |
| --status-addr | Dumpling 的服务地址,包含了 Prometheus 拉取 metrics 信息及 pprof 调试的地址 | ":8281" |
| --tidb-mem-quota-query | 单条 dumpling 命令导出 SQL 语句的内存限制,单位为 byte。对于 v4.0.10 或以上版本,若不设置该参数,默认使用 TiDB 中的 mem-quota-query 配置项值作为内存限制值。对于 v4.0.10 以下版本,该参数值默认为 32 GB | 34359738368 |
| --params | 为需导出的数据库连接指定 session 变量,可接受的格式: "character_set_client=latin1,character_set_connection=latin1" |