两地三中心部署
本文档简要介绍两地三中心部署的架构模型及配置。
简介
两地三中心架构,即生产数据中心、同城灾备中心、异地灾备中心的高可用容灾方案。在这种模式下,两个城市的三个数据中心互联互通,如果一个数据中心发生故障或灾难,其他数据中心可以正常运行并对关键业务或全部业务实现接管。相比同城多中心方案,两地三中心具有跨城级高可用能力,可以应对城市级自然灾害。
TiDB 分布式数据库通过 Raft 算法原生支持两地三中心架构的建设,并保证数据库集群数据的一致性和高可用性。而且因同城数据中心网络延迟相对较小,可以把业务流量同时派发到同城两个数据中心,并通过控制 Region Leader 和 PD Leader 分布实现同城数据中心共同负载业务流量的设计。
架构
本文以北京和西安为例,阐述 TiDB 分布式数据库两地三中心架构的部署模型。
本例中,北京有两个机房 IDC1 和 IDC2,异地西安一个机房 IDC3。北京同城两机房之间网络延迟低于 3 ms,北京与西安之间的网络使用 ISP 专线,延迟约 20 ms。
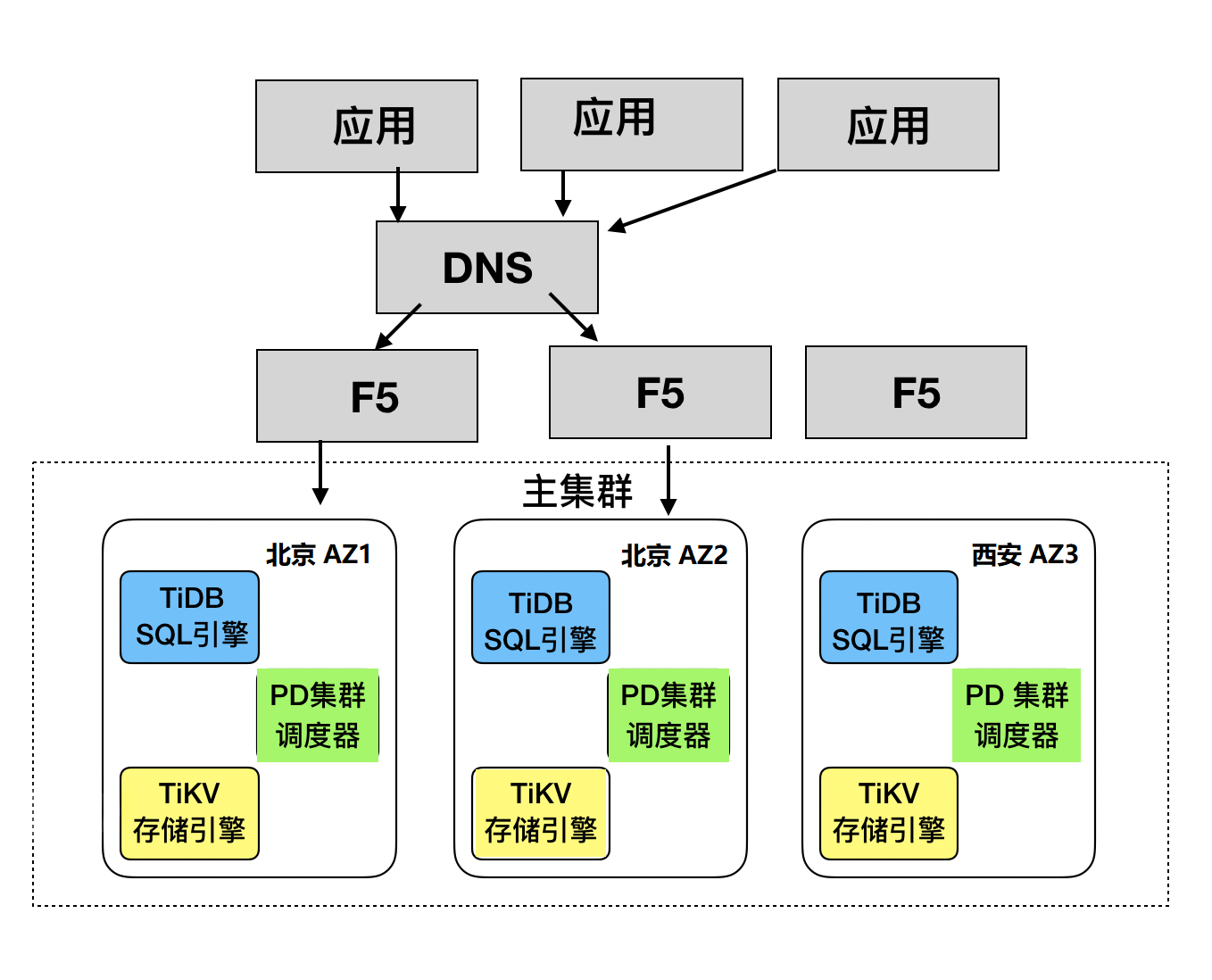
下图为集群部署架构图,具体如下:
- 集群采用两地三中心部署方式,分别为北京 IDC1,北京 IDC2,西安 IDC3;
- 集群采用 5 副本模式,其中 IDC1 和 IDC2 分别放 2 个副本,IDC3 放 1 个副本;TiKV 按机柜打 Label,既每个机柜上有一份副本。
- 副本间通过 Raft 协议保证数据的一致性和高可用,对用户完全透明。
该架构具备高可用能力,同时通过 PD 调度限制了 Region Leader 尽量只出现在同城的两个数据中心,这相比于三数据中心,即 Region Leader 分布不受限制的方案有以下优缺点:
优点
- Region Leader 都在同城低延迟机房,数据写入速度更优。
- 两中心可同时对外提供服务,资源利用率更高。
- 可保证任一数据中心失效后,服务可用并且不发生数据丢失。
缺点
- 因为数据一致性是基于 Raft 算法实现,当同城两个数据中心同时失效时,因为异地灾备中心只剩下一份副本,不满足 Raft 算法大多数副本存活的要求。最终将导致集群暂时不可用,需要从一副本恢复集群,只会丢失少部分还没同步的热数据。这种情况出现的概率是比较小的。
- 由于使用到了网络专线,导致该架构下网络设施成本较高。
- 两地三中心需设置 5 副本,数据冗余度增加,增加空间成本。
详细示例
北京、西安两地三中心配置详解:
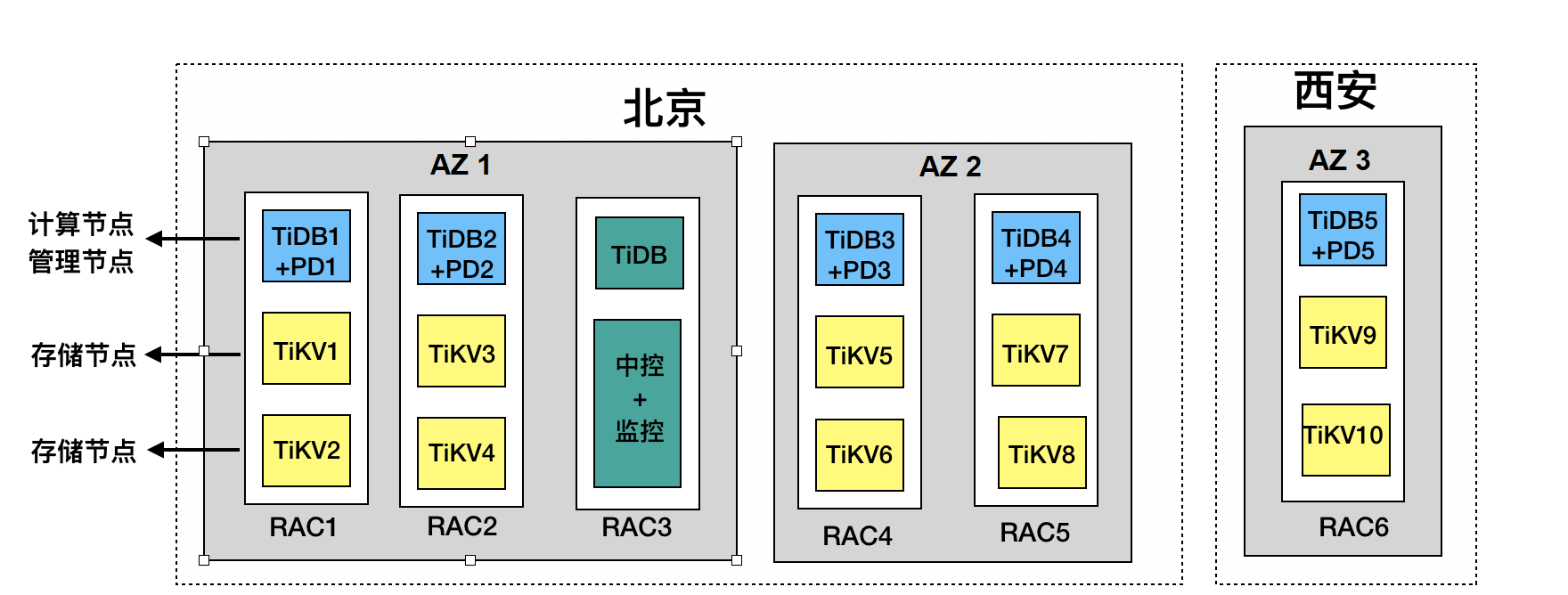
- 如上图所示,北京有两个机房 IDC1 和 IDC2,机房 IDC1 中有三套机架 RAC1、RAC2、RAC3,机房 IDC2 有机架 RAC4、RAC5;西安机房 IDC3 有机架 RAC6。
- 如上图中 RAC1 机架所示,TiDB、PD 服务部署在同一台服务器上,还有两台 TiKV 服务器;每台 TiKV 服务器部署 2 个 TiKV 实例(tikv-server),RAC2、RAC4、RAC5、RAC6 类似。
- 机架 RAC3 上安放 TiDB Server 及中控 + 监控服务器。部署 TiDB Server,用于日常管理维护、备份使用。中控 + 监控服务器上部署 TiDB Ansible、Prometheus、Grafana 以及恢复工具;
- 另可增加备份服务器,其上部署 Mydumper 及 Drainer,Drainer 以输出 file 文件的方式将 binlog 数据保存到指定位置,实现增量备份的目的。
配置
示例
以下为一个 tiup topology.yaml 文件示例:
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb_cluster/tidb-deploy"
data_dir: "/data/tidb_cluster/tidb-data"
server_configs:
tikv:
server.grpc-compression-type: gzip
pd:
replication.location-labels: ["dc","rack","zone","host"]
schedule.tolerant-size-ratio: 20.0
pd_servers:
- host: 10.63.10.10
name: "pd-10"
- host: 10.63.10.11
name: "pd-11"
- host: 10.63.10.12
name: "pd-12"
- host: 10.63.10.13
name: "pd-13"
- host: 10.63.10.14
name: "pd-14"
tidb_servers:
- host: 10.63.10.10
- host: 10.63.10.11
- host: 10.63.10.12
- host: 10.63.10.13
- host: 10.63.10.14
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { dc: "1", zone: "1", rack: "1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { dc: "1", zone: "2", rack: "2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { dc: "2", zone: "3", rack: "3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { dc: "2", zone: "4", rack: "4", host: "33" }
- host: 10.63.10.34
config:
server.labels: { dc: "3", zone: "5", rack: "5", host: "34" }
raftstore.raft-min-election-timeout-ticks: 1000
raftstore.raft-max-election-timeout-ticks: 1200
monitoring_servers:
- host: 10.63.10.60
grafana_servers:
- host: 10.63.10.60
alertmanager_servers:
- host: 10.63.10.60
Labels 设计
在两地三中心部署方式下,对于 Labels 的设计需要充分考虑到系统的可用性和容灾能力,建议根据部署的物理结构来定义 DC、ZONE、RACK、HOST 四个等级。
PD 设置中添加 TiKV label 的等级配置。
server_configs:
pd:
replication.location-labels: ["dc","zone","rack","host"]
tikv_servers 设置基于 TiKV 真实物理部署位置的 Label 信息,方便 PD 进行全局管理和调度。
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { dc: "1", zone: "1", rack: "1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { dc: "1", zone: "2", rack: "2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { dc: "2", zone: "3", rack: "3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { dc: "2", zone: "4", rack: "4", host: "33" }
- host: 10.63.10.34
config:
server.labels: { dc: "3", zone: "5", rack: "5", host: "34" }
参数配置优化
在两地三中心的架构部署中,从性能优化的角度,除了常规参数配置外,还需要对集群中相关组件参数进行调整。
启用 TiKV gRPC 消息压缩。由于涉及到集群中的数据在网络中传输,需要开启 gRPC 消息压缩,降低网络流量。
server.grpc-compression-type: gzip调整 PD balance 缓冲区大小,提高 PD 容忍度,因为 PD 会根据节点情况计算出各个对象的 score 作为调度的依据,当两个 store 的 leader 或 Region 的得分差距小于指定倍数的 Region size 时,PD 会认为此时 balance 达到均衡状态。
schedule.tolerant-size-ratio: 20.0异地 DC3 TiKV 节点网络优化,单独修改异地 TiKV 此参数,拉长异地副本参与选举的时间,尽量避免异地 TiKV 中的副本参与 Raft 选举。
raftstore.raft-min-election-timeout-ticks: 1000 raftstore.raft-max-election-timeout-ticks: 1200调度设置。在集群启动后,通过
tiup ctl:<cluster-version> pd工具进行调度策略修改。修改 TiKV Raft 副本数按照安装时规划好的副本数进行设置,在本例中为 5 副本。config set max-replicas 5禁止向异地机房调度 Raft Leader,当 Raft Leader 在异地数据中心时,会造成不必要的本地数据中心与异地数据中心间的网络消耗,同时由于网络带宽和延迟的影响,也会对 TiDB 的集群性能产生影响。需要禁用异地中心的 Raft leader 的调度。
config set label-property reject-leader dc 3设置 PD 的优先级,为了避免出现异地数据中心的 PD 成为 Leader,可以将本地数据中心的 PD 优先级调高(数字越大,优先级越高),将异地的 PD 优先级调低。
member leader_priority PD-10 5 member leader_priority PD-11 5 member leader_priority PD-12 5 member leader_priority PD-13 5 member leader_priority PD-14 1