TiKV 简介
TiKV 是一个分布式事务型的键值数据库,提供了满足 ACID 约束的分布式事务接口,并且通过 Raft 协议 保证了多副本数据一致性以及高可用。TiKV 作为 TiDB 的存储层,为用户写入 TiDB 的数据提供了持久化以及读写服务,同时还存储了 TiDB 的统计信息数据。
整体架构
与传统的整节点备份方式不同,TiKV 参考 Spanner 设计了 multi-raft-group 的副本机制。将数据按照 key 的范围划分成大致相等的切片(下文统称为 Region),每一个切片会有多个副本(通常是 3 个),其中一个副本是 Leader,提供读写服务。TiKV 通过 PD 对这些 Region 以及副本进行调度,以保证数据和读写负载都均匀地分散在各个 TiKV 上,这样的设计保证了整个集群资源的充分利用并且可以随着机器数量的增加水平扩展。
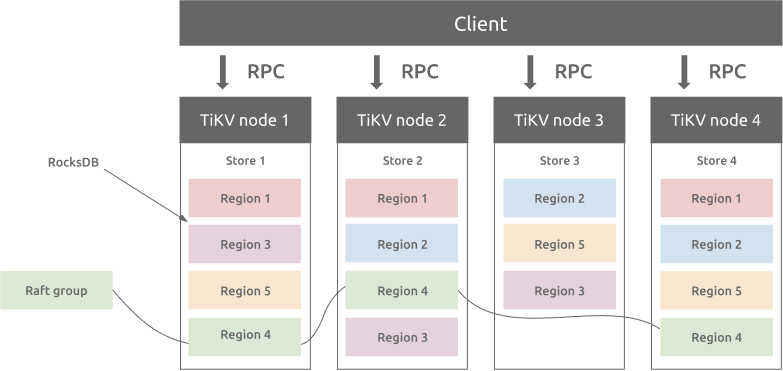
Region 与 RocksDB
虽然 TiKV 将数据按照范围切割成了多个 Region,但是同一个节点的所有 Region 数据仍然是不加区分地存储于同一个 RocksDB 实例上,而用于 Raft 协议复制所需要的日志则存储于另一个 RocksDB 实例。这样设计的原因是因为随机 I/O 的性能远低于顺序 I/O,所以 TiKV 使用同一个 RocksDB 实例来存储这些数据,以便不同 Region 的写入可以合并在一次 I/O 中。
Region 与 Raft 协议
Region 与副本之间通过 Raft 协议来维持数据一致性,任何写请求都只能在 Leader 上写入,并且需要写入多数副本后(默认配置为 3 副本,即所有请求必须至少写入两个副本成功)才会返回客户端写入成功。
当某个 Region 的大小超过一定限制(默认是 144MB)后,TiKV 会将它分裂为两个或者更多个 Region,以保证各个 Region 的大小是大致接近的,这样更有利于 PD 进行调度决策。同样,当某个 Region 因为大量的删除请求导致 Region 的大小变得更小时,TiKV 会将比较小的两个相邻 Region 合并为一个。
当 PD 需要把某个 Region 的一个副本从一个 TiKV 节点调度到另一个上面时,PD 会先为这个 Raft Group 在目标节点上增加一个 Learner 副本(虽然会复制 Leader 的数据,但是不会计入写请求的多数副本中)。当这个 Learner 副本的进度大致追上 Leader 副本时,Leader 会将它变更为 Follower,之后再移除操作节点的 Follower 副本,这样就完成了 Region 副本的一次调度。
Leader 副本的调度原理也类似,不过需要在目标节点的 Learner 副本变为 Follower 副本后,再执行一次 Leader Transfer,让该 Follower 主动发起一次选举成为新 Leader,之后新 Leader 负责删除旧 Leader 这个副本。
分布式事务
TiKV 支持分布式事务,用户(或者 TiDB)可以一次性写入多个 key-value 而不必关心这些 key-value 是否处于同一个数据切片 (Region) 上,TiKV 通过两阶段提交保证了这些读写请求的 ACID 约束,详见 TiDB 乐观事务模型。
计算加速
TiKV 通过协处理器 (Coprocessor) 可以为 TiDB 分担一部分计算:TiDB 会将可以由存储层分担的计算下推。能否下推取决于 TiKV 是否可以支持相关下推。计算单元仍然是以 Region 为单位,即 TiKV 的一个 Coprocessor 计算请求中不会计算超过一个 Region 的数据。