TiDB Binlog Kafka 部署方案
本文档介绍如何部署 Kafka 版本的 TiDB Binlog。
TiDB Binlog 简介
TiDB Binlog 是用于收集 TiDB 的 Binlog,并提供实时备份和同步功能的商业工具。
TiDB Binlog 支持以下功能场景:
- 数据同步:同步 TiDB 集群数据到其他数据库
- 实时备份和恢复:备份 TiDB 集群数据,同时可以用于 TiDB 集群故障时恢复
TiDB Binlog Kafka 架构
首先介绍 TiDB Binlog 的整体架构。
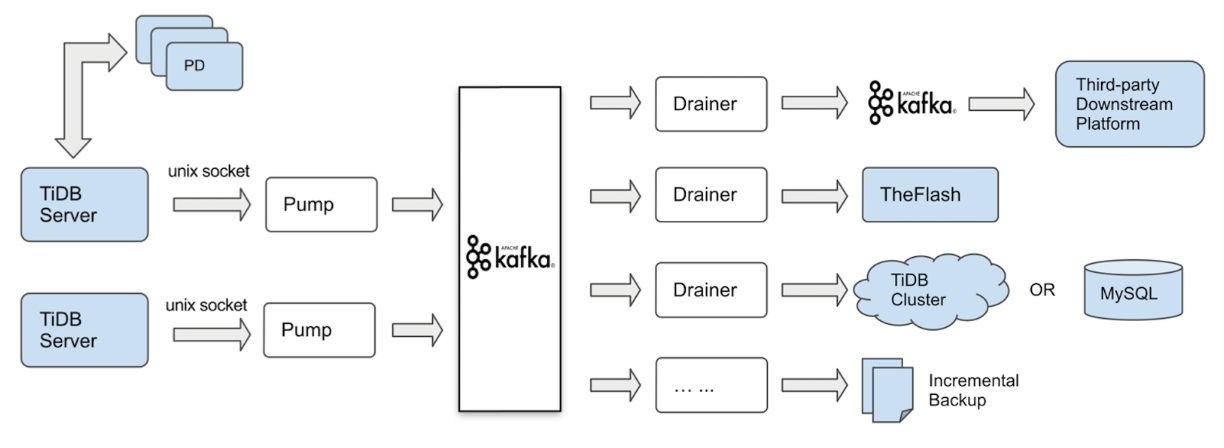
TiDB Binlog 集群主要分为三个组件:
Pump
Pump 是一个守护进程,在每个 TiDB 主机的后台运行。其主要功能是实时记录 TiDB 产生的 Binlog 并顺序写入 Kafka 中。
Drainer
Drainer 从 Kafka 中收集 Binlog,并按照 TiDB 中事务的提交顺序转化为指定数据库兼容的 SQL 语句,最后同步到目的数据库或者写到顺序文件。
Kafka & ZooKeeper
Kafka 集群用来存储由 Pump 写入的 Binlog 数据,并提供给 Drainer 进行读取。
TiDB Binlog 安装
以下为 TiDB Ansible 分支与 TiDB 版本的对应关系,版本选择可咨询官方 info@pingcap.com。
| TiDB Ansible 分支 | TiDB 版本 | 备注 |
|---|---|---|
| release-2.0 | 2.0 版本 | 最新 2.0 稳定版本,可用于生产环境。 |
下载官方 Binary
环境:CentOS 7+
下载压缩包:
wget https://download.pingcap.org/tidb-binlog-kafka-linux-amd64.tar.gz &&
wget https://download.pingcap.org/tidb-binlog-kafka-linux-amd64.sha256
检查文件完整性,返回 ok 则正确:
sha256sum -c tidb-binlog-kafka-linux-amd64.sha256
解开压缩包:
tar -xzf tidb-binlog-kafka-linux-amd64.tar.gz &&
cd tidb-binlog-kafka-linux-amd64
TiDB Binlog 部署
注意事项
需要为一个 TiDB 集群中的每台 TiDB server 部署一个 Pump,目前 TiDB server 只支持以 unix socket 的方式输出 Binlog。
手动部署时,启动顺序为:Pump > TiDB。停止顺序为 TiDB > Pump。
设置 TiDB 启动参数
binlog-socket为对应的 Pump 参数socket所指定的 unix socket 文件路径,最终部署结构如下图所示: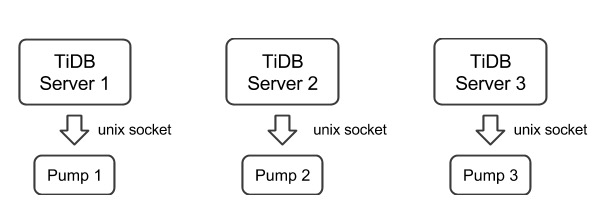
Drainer 不支持对 ignore schemas(在过滤列表中的 schemas)的 table 进行 rename DDL 操作。
在已有的 TiDB 集群中启动 Drainer,一般需要全量备份并且获取 savepoint,然后导入全量备份,最后启动 Drainer 从 savepoint 开始同步。
为了保证数据的完整性,在 Pump 运行 10 分钟左右后按顺序进行如下操作:
- 使用 binlogctl 工具生成 Drainer 初次启动所需的 position
- 全量备份,例如 Mydumper 备份 TiDB
- 全量导入备份到目标系统
- Kafka 版本 Drainer 启动的 savepoint 默认保存在下游 database tidb_binlog 下的 checkpoint 表中,如果 checkpoint 表中没有有效的数据,可以通过设置
initial-commit-ts启动 Drainer 从指定位置开始消费 -bin/drainer --config=conf/drainer.toml --initial-commit-ts=${position}
Drainer 输出为 pb,要在配置文件中设置如下参数:
[syncer] db-type = "pb" disable-dispatch = true [syncer.to] dir = "/path/pb-dir"Drainer 输出为 kafka,要在配置文件中设置如下参数:
[syncer] db-type = "kafka" # when db-type is kafka, you need to use this to config the down stream kafka, or it will be the same kafka addrs where drainer pull binlog from. [syncer.to] kafka-addrs = "127.0.0.1:9092" kafka-version = "0.8.2.0"输出到 kafka 的数据为按 ts 排好序的 protobuf 定义 binlog 格式,可以参考 driver 获取数据同步到下游。
Kafka 和 ZooKeeper 集群需要在部署 TiDB Binlog 之前部署好。Kafka 需要 0.9 及以上版本。
Kafka 集群配置推荐
| 名字 | 数量 | 内存 | CPU | 硬盘 |
|---|---|---|---|---|
| Kafka | 3+ | 16G | 8+ | 2+ 1TB |
| ZooKeeper | 3+ | 8G | 4+ | 2+ 300G |
Kafka 配置参数推荐
auto.create.topics.enable = true:如果还没有创建 topic,Kafka 会在 broker 上自动创建 topicbroker.id:用来标识 Kafka 集群的必备参数,不能重复,如broker.id = 1fs.file-max = 1000000:Kafka 会使用大量文件和网络 socket,建议修改成 1000000,通过vi /etc/sysctl.conf进行修改修改以下配置为1G, 否则很容易出现事务修改数据较多导致单个消息过大写 kafka 失败
message.max.bytes=1073741824replica.fetch.max.bytes=1073741824fetch.message.max.bytes=1073741824
使用 TiDB Ansible 部署 Pump
- 如无 Kafka 集群,可使用 kafka-ansible 部署 Kafka 集群。
- 使用 tidb-ansible 部署 TiDB 集群时,修改
tidb-ansible/inventory.ini文件,设置enable_binlog = True,并配置zookeeper_addrs变量为 Kafka 集群的 ZooKeeper 地址,这样部署 TiDB 集群时会部署 Pump。
配置样例:
# binlog trigger
enable_binlog = True
# ZooKeeper address of Kafka cluster, example:
# zookeeper_addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181"
# You can also append an optional chroot string to the URLs to specify the root directory for all Kafka znodes, example:
# zookeeper_addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181/kafka/123"
zookeeper_addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181"
使用 Binary 部署 Pump
使用样例:
假设我们有三个 PD,三个 ZooKeeper,一个 TiDB,各个节点信息如下:
TiDB="192.168.0.10"
PD1="192.168.0.16"
PD2="192.168.0.15"
PD3="192.168.0.14"
ZK1="192.168.0.13"
ZK2="192.168.0.12"
ZK3="192.168.0.11"
在 ip="192.168.0.10" 的机器上面部署 Drainer/Pump。
对应的 PD 集群的 ip="192.168.0.16,192.168.0.15,192.168.0.14"。
对应的 Kafka 集群的 ZooKeeper 的 ip="192.168.0.13,192.168.0.12,192.168.0.11"。以此为例,说明 Pump/Drainer 的使用。
Pump 命令行参数说明
Usage of Pump: -L string 日志输出信息等级设置: debug, info, warn, error, fatal (默认 "info") -V 打印版本信息 -addr string Pump 提供服务的 RPC 地址(-addr="192.168.0.10:8250") -advertise-addr string Pump 对外提供服务的 RPC 地址(-advertise-addr="192.168.0.10:8250") -config string 配置文件路径,如果你指定了配置文件,Pump 会首先读取配置文件的配置; 如果对应的配置在命令行参数里面也存在,Pump 就会使用命令行参数的配置来覆盖配置文件里面的。 -data-dir string Pump 数据存储位置路径 -enable-tolerant 开启 tolerant 后,如果 binlog 写入失败,Pump 不会报错(默认开启) -zookeeper-addrs string (-zookeeper_addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181") ZooKeeper 地址,该选项从 ZooKeeper 中获取 Kafka 地址,需要和 Kafka 中配置相同 -gc int 日志最大保留天数 (默认 7),设置为 0 可永久保存 -heartbeat-interval int Pump 向 PD 发送心跳间隔 (单位 秒) -log-file string log 文件路径 -log-rotate string log 文件切换频率,hour/day -metrics-addr string Prometheus pushgateway 地址,不设置则禁止上报监控信息 -metrics-interval int 监控信息上报频率 (默认 15,单位 秒) -pd-urls string PD 集群节点的地址 (-pd-urls="http://192.168.0.16:2379,http://192.168.0.15:2379,http://192.168.0.14:2379") -socket string unix socket 模式服务监听地址(默认 unix:///tmp/pump.sock)Pump 配置文件
# Pump Configuration. # Pump 提供服务的 RPC 地址("192.168.0.10:8250") addr = "192.168.0.10:8250" # Pump 对外提供服务的 RPC 地址("192.168.0.10:8250") advertise-addr = "" # binlog 最大保留天数 (默认 7),设置为 0 可永久保存 gc = 7 # Pump 数据存储位置路径 data-dir = "data.pump" # ZooKeeper 地址,该选项从 ZooKeeper 中获取 Kafka 地址,若 Kafka 中配置了命名空间,则此处需同样配置 # zookeeper-addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181" # 配置了命令空间的 ZooKeeper 地址配置示例 # zookeeper-addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181/kafka/123" # Pump 向 PD 发送心跳的间隔 (单位 秒) heartbeat-interval = 3 # PD 集群节点的地址 pd-urls = "http://192.168.0.16:2379,http://192.168.0.15:2379,http://192.168.0.14:2379" # unix socket 模式服务监听地址 (默认 unix:///tmp/pump.sock) socket = "unix:///tmp/pump.sock"启动示例
```bash
./bin/pump -config pump.toml
```
使用 Binary 部署 Drainer
Drainer 命令行参数说明
Usage of Drainer: -L string 日志输出信息等级设置:debug, info, warn, error, fatal (默认 "info") -V 打印版本信息 -addr string Drainer 提供服务的地址(-addr="192.168.0.10:8249") -c int 同步下游的并发数,该值设置越高同步的吞吐性能越好 (default 1) -config string 配置文件路径,Drainer 会首先读取配置文件的配置; 如果对应的配置在命令行参数里面也存在,Drainer 就会使用命令行参数的配置来覆盖配置文件里面的 -data-dir string Drainer 数据存储位置路径 (默认 "data.drainer") -zookeeper-addrs string (-zookeeper-addrs="192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181") ZooKeeper 地址,该选项从 ZooKeeper 中获取 Kafka 地址,需要和 Kafka 中配置相同 -dest-db-type string Drainer 下游服务类型 (默认为 mysql) -detect-interval int 向 PD 查询在线 Pump 的时间间隔 (默认 10,单位 秒) -disable-dispatch 是否禁用拆分单个 binlog 的 sqls 的功能,如果设置为 true,则按照每个 binlog 顺序依次还原成单个事务进行同步(下游服务类型为 mysql,该项设置为 False) -ignore-schemas string db 过滤列表 (默认 "INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql,test"), 不支持对 ignore schemas 的 table 进行 rename DDL 操作 -initial-commit-ts (默认为 0) 如果 Drainer 没有相关的断点信息,可以通过该项来设置相关的断点信息 -log-file string log 文件路径 -log-rotate string log 文件切换频率,hour/day -metrics-addr string Prometheus pushgateway 地址,不设置则禁止上报监控信息 -metrics-interval int 监控信息上报频率(默认 15,单位 秒) -pd-urls string PD 集群节点的地址 (-pd-urls="http://192.168.0.16:2379,http://192.168.0.15:2379,http://192.168.0.14:2379") -txn-batch int 输出到下游数据库一个事务的 SQL 数量(默认 1)Drainer 配置文件
# Drainer Configuration. # Drainer 提供服务的地址("192.168.0.10:8249") addr = "192.168.0.10:8249" # 向 PD 查询在线 Pump 的时间间隔 (默认 10,单位 秒) detect-interval = 10 # Drainer 数据存储位置路径 (默认 "data.drainer") data-dir = "data.drainer" # ZooKeeper 地址,该选项从 ZooKeeper 中获取 Kafka 地址,若 Kafka 中配置了命名空间,则此处需同样配置 # zookeeper-addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181" # 配置了命令空间的 ZooKeeper 地址配置示例 # zookeeper-addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181/kafka/123" # PD 集群节点的地址 pd-urls = "http://192.168.0.16:2379,http://192.168.0.15:2379,http://192.168.0.14:2379" # log 文件路径 log-file = "drainer.log" # Syncer Configuration. [syncer] ## db 过滤列表 (默认 "INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql,test"), ## 不支持对 ignore schemas 的 table 进行 rename DDL 操作 ignore-schemas = "INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql" # 输出到下游数据库一个事务的 SQL 数量 (default 1) txn-batch = 1 # 同步下游的并发数,该值设置越高同步的吞吐性能越好 (default 1) worker-count = 1 # 是否禁用拆分单个 binlog 的 sqls 的功能,如果设置为 true,则按照每个 binlog # 顺序依次还原成单个事务进行同步(下游服务类型为 mysql, 该项设置为 False) disable-dispatch = false # Drainer 下游服务类型(默认为 mysql) # 参数有效值为 "mysql", "pb" db-type = "mysql" # replicate-do-db prioritizes over replicate-do-table when they have the same db name # and we support regex expressions, # 以 '~' 开始声明使用正则表达式 #replicate-do-db = ["~^b.*","s1"] #[[syncer.replicate-do-table]] #db-name ="test" #tbl-name = "log" #[[syncer.replicate-do-table]] #db-name ="test" #tbl-name = "~^a.*" # db-type 设置为 mysql 时,下游数据库服务器参数 [syncer.to] host = "192.168.0.10" user = "root" password = "" port = 3306 # db-type 设置为 pb 时,存放 binlog 文件的目录 # [syncer.to] # dir = "data.drainer"启动示例
```bash
./bin/drainer -config drainer.toml
```
下载 PbReader 工具 (Linux)
PbReader 用于解析 Drainer 生成的 Pb 文件,并翻译成对应的 SQL 语句。
环境:CentOS 7+
下载 PbReader 压缩包:
wget https://download.pingcap.org/pb_reader-latest-linux-amd64.tar.gz &&
wget https://download.pingcap.org/pb_reader-latest-linux-amd64.sha256
检查文件完整性,返回 ok 则正确:
sha256sum -c pb_reader-latest-linux-amd64.sha256
解开压缩包:
tar -xzf pb_reader-latest-linux-amd64.tar.gz &&
cd pb_reader-latest-linux-amd64
PbReader 使用示例:
./bin/pbReader -binlog-file=${path}/binlog-0000000000000000
TiDB Binlog 监控
本部分主要介绍如何对 TiDB Binlog 的状态、性能做监控,并通过 Prometheus + Grafana 展现 metrics 数据。
Pump/Drainer 配置
使用 TiDB Ansible 部署的 Pump 服务已经在启动参数设置 metrics。启动 Drainer 时可以设置以下两个参数:
--metrics-addr:设为 Push Gateway 的地址--metrics-interval:设为 push 的频率,单位为秒,默认值为 15
Grafana 配置
进入 Grafana Web 界面(默认地址:
http://localhost:3000,默认账号:admin,密码:admin)点击 Grafana Logo -> 点击 Data Sources -> 点击 Add data source -> 填写 data source 信息
导入 dashboard 配置文件
点击 Grafana Logo -> 点击 Dashboards -> 点击 Import -> 选择需要的 dashboard 配置文件上传 -> 选择对应的 data source