TiDB Scheduler 扩展调度器
TiDB Scheduler 是 Kubernetes 调度器扩展 的 TiDB 实现。TiDB Scheduler 用于向 Kubernetes 添加新的调度规则。本文介绍 TiDB Scheduler 扩展调度器的工作原理。
TiDB 集群调度需求
TiDB 集群包括 PD,TiKV 以及 TiDB 三个核心组件,每个组件又是由多个节点组成,PD 是一个 Raft 集群,TiKV 是一个多 Raft Group 集群,并且这两个组件都是有状态的。默认 Kubernetes 的调度器的调度规则无法满足 TiDB 集群的高可用调度需求,需要扩展 Kubernetes 的调度规则。
目前,可通过修改 TidbCluster 的 metadata.annotations 来按照特定的维度进行调度,比如:
metadata:
annotations:
pingcap.com/ha-topology-key: kubernetes.io/hostname
或者修改 tidb-cluster chart 的 values.yaml :
haTopologyKey: kubernetes.io/hostname
上述配置按照节点(默认值)维度进行调度,若要按照其他维度调度,比如: pingcap.com/ha-topology-key: zone,表示按照 zone 调度,还需给各节点打如下标签:
kubectl label nodes node1 zone=zone1
不同节点可有不同的标签,也可有相同的标签,如果某一个节点没有打该标签,则调度器不会调度 pod 到该节点。
目前,TiDB Scheduler 实现了如下几种自定义的调度规则(下述示例基于节点调度,基于其他维度的调度规则相同)。
PD 组件
调度规则一:确保每个节点上调度的 PD 实例个数小于 Replicas / 2。例如:
| PD 集群规模(Replicas) | 每个节点最多可调度的 PD 实例数量 |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
| 5 | 2 |
| ... |
TiKV 组件
调度规则二:如果 Kubernetes 节点数小于 3 个(Kubernetes 集群节点数小于 3 个是无法实现 TiKV 高可用的),则可以任意调度;否则,每个节点上可调度的 TiKV 个数的计算公式为:ceil(Replicas/3) 。例如:
| TiKV 集群规模(Replicas) | 每个节点最多可调度的 TiKV 实例数量 | 最佳调度分布 |
|---|---|---|
| 3 | 1 | 1,1,1 |
| 4 | 2 | 1,1,2 |
| 5 | 2 | 1,2,2 |
| 6 | 2 | 2,2,2 |
| 7 | 3 | 2,2,3 |
| 8 | 3 | 2,3,3 |
| ... |
TiDB 组件
调度规则三:在 TiDB 实例滚动更新的时候,尽量将其调度回原来的节点。
这样实现了稳定调度,对于手动将 Node IP + NodePort 挂载在 LB 后端的场景比较有帮助,避免升级集群后 Node IP 发生变更时需要重新调整 LB,这样可以减少滚动更新时对集群的影响。
工作原理
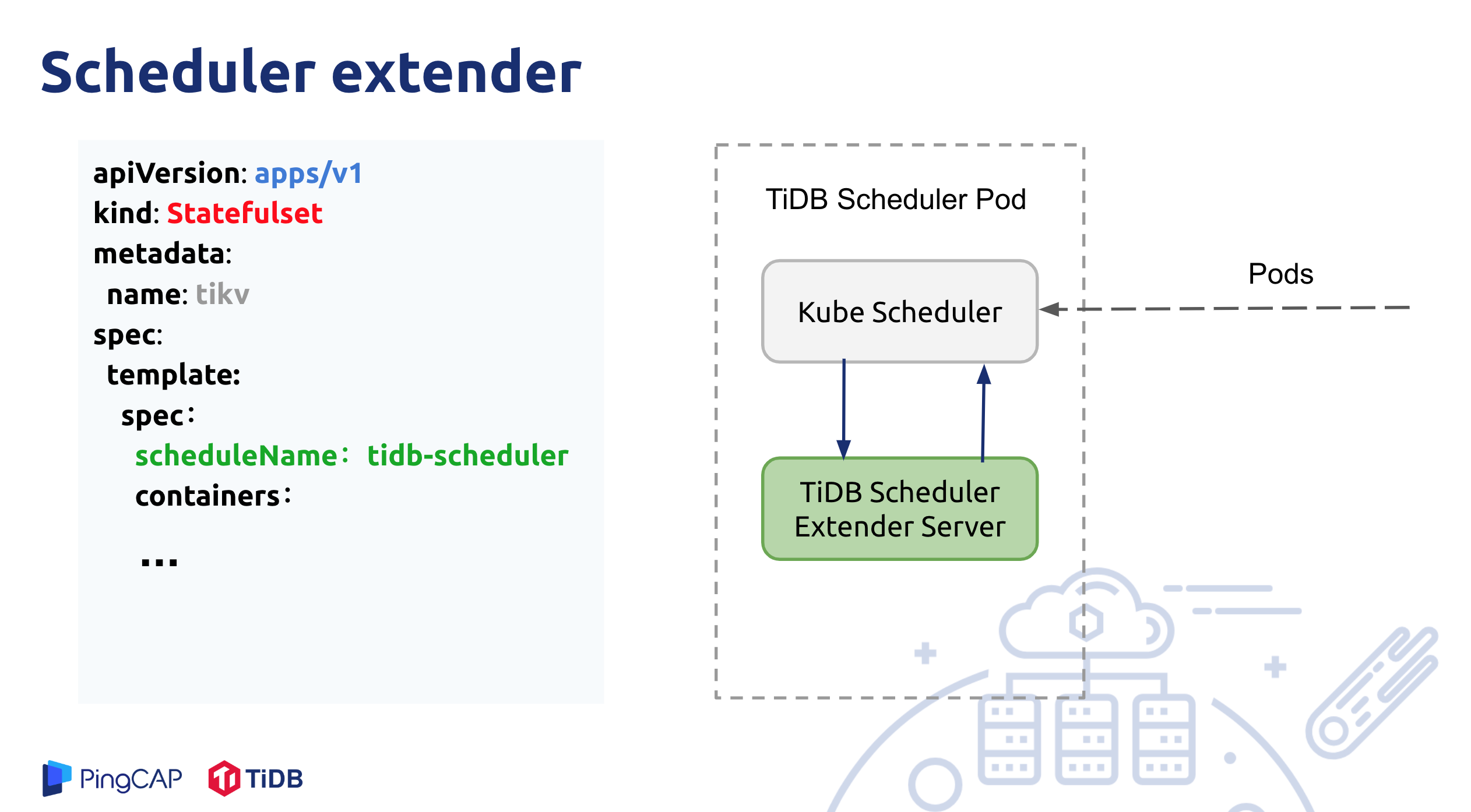
TiDB Scheduler 通过实现 Kubernetes 调度器扩展(Scheduler extender)来添加自定义调度规则。
TiDB Scheduler 组件部署为一个或者多个 Pod,但同时只有一个 Pod 在工作。Pod 内部有两个 Container,一个 Container 是原生的 kube-scheduler;另外一个 Container 是 tidb-scheduler,实现为一个 Kubernetes scheduler extender。
TiDB Operator 创建的 PD、TiDB、TiKV Pod 的 .spec.schedulerName 属性会被设置为 tidb-scheduler,即都用 TiDB Scheduler 自定义调度器来调度。如果是测试集群,并且不要求高可用,可以将 .spec.schedulerName 改成 default-scheduler 使用 Kubernetes 内置的调度器。
一个 Pod 的调度流程是这样的:
kube-scheduler拉取所有.spec.schedulerName为tidb-scheduler的 Pod,对于每个 Pod 会首先经过 Kubernetes 默认调度规则过滤;- 在这之后,
kube-scheduler会发请求到tidb-scheduler服务,tidb-scheduler会通过一些自定义的调度规则(见上述介绍)对发送过来的节点进行过滤,最终将剩余可调度的节点返回给kube-scheduler; - 最终由
kube-scheduler决定最终调度的节点。
如果出现 Pod 无法调度,请参考此文档诊断和解决。