TiDB TPC-H Performance Test Report -- TiDB v5.4 MPP mode vs. Greenplum 6.15.0 and Apache Spark 3.1.1
Test overview
This test aims at comparing the TPC-H 100 GB performance of TiDB v5.4 in the MPP mode with that of Greenplum and Apache Spark, two mainstream analytics engines, in their latest versions. The test result shows that the performance of TiDB v5.4 in the MPP mode is two to three times faster than that of the other two solutions under TPC-H workload.
In v5.0, TiDB introduces the MPP mode for TiFlash, which significantly enhances TiDB's Hybrid Transactional and Analytical Processing (HTAP) capabilities. Test objects in this report are as follows:
- TiDB v5.4 columnar storage in the MPP mode
- Greenplum 6.15.0
- Apache Spark 3.1.1 + Parquet
Test environment
Hardware prerequisite
| Instance type | Instance count |
|---|---|
| PD | 1 |
| TiDB | 1 |
| TiKV | 3 |
| TiFlash | 3 |
- CPU: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz, 40 cores
- Memory: 189 GB
- Disks: NVMe 3TB * 2
Software version
| Service type | Software version |
|---|---|
| TiDB | 5.4 |
| Greenplum | 6.15.0 |
| Apache Spark | 3.1.1 |
Parameter configuration
TiDB v5.4
For the v5.4 cluster, TiDB uses the default parameter configuration except for the following configuration items.
In the configuration file users.toml of TiFlash, configure max_memory_usage as follows:
[profiles.default]
max_memory_usage = 10000000000000
Set session variables with the following SQL statements:
set @@tidb_isolation_read_engines='tiflash';
set @@tidb_allow_mpp=1;
set @@tidb_mem_quota_query = 10 << 30;
All TPC-H test tables are replicated to TiFlash in columnar format, with no additional partitions or indexes.
Greenplum
Except for the initial 3 nodes, the Greenplum cluster is deployed using an additional master node. Each segment server contains 8 segments, which means 4 segments per NVMe SSD. So there are 24 segments in total. The storage format is append-only/column-oriented storage and partition keys are used as primary keys.
log_statement = all
gp_autostats_mode = none
statement_mem = 2048MB
gp_vmem_protect_limit = 16384
Apache Spark
The test of Apache Spark uses Apache Parquet as the storage format and stores the data on HDFS. The HDFS system consists of three nodes. Each node has two assigned NVMe SSD disks as the data disks. The Spark cluster is deployed in standalone mode, using NVMe SSD disks as the local directory of spark.local.dir to speed up the shuffle spill, with no additional partitions or indexes.
--driver-memory 20G
--total-executor-cores 120
--executor-cores 5
--executor-memory 15G
Test result
| Query ID | TiDB v5.4 | Greenplum 6.15.0 | Apache Spark 3.1.1 + Parquet |
|---|---|---|---|
| 1 | 8.08 | 64.1307 | 52.64 |
| 2 | 2.53 | 4.76612 | 11.83 |
| 3 | 4.84 | 15.62898 | 13.39 |
| 4 | 10.94 | 12.88318 | 8.54 |
| 5 | 12.27 | 23.35449 | 25.23 |
| 6 | 1.32 | 6.033 | 2.21 |
| 7 | 5.91 | 12.31266 | 25.45 |
| 8 | 6.71 | 11.82444 | 23.12 |
| 9 | 44.19 | 22.40144 | 35.2 |
| 10 | 7.13 | 12.51071 | 12.18 |
| 11 | 2.18 | 2.6221 | 10.99 |
| 12 | 2.88 | 7.97906 | 6.99 |
| 13 | 6.84 | 10.15873 | 12.26 |
| 14 | 1.69 | 4.79394 | 3.89 |
| 15 | 3.29 | 10.48785 | 9.82 |
| 16 | 5.04 | 4.64262 | 6.76 |
| 17 | 11.7 | 74.65243 | 44.65 |
| 18 | 12.87 | 64.87646 | 30.27 |
| 19 | 4.75 | 8.08625 | 4.7 |
| 20 | 8.89 | 15.47016 | 8.4 |
| 21 | 24.44 | 39.08594 | 34.83 |
| 22 | 1.23 | 7.67476 | 4.59 |
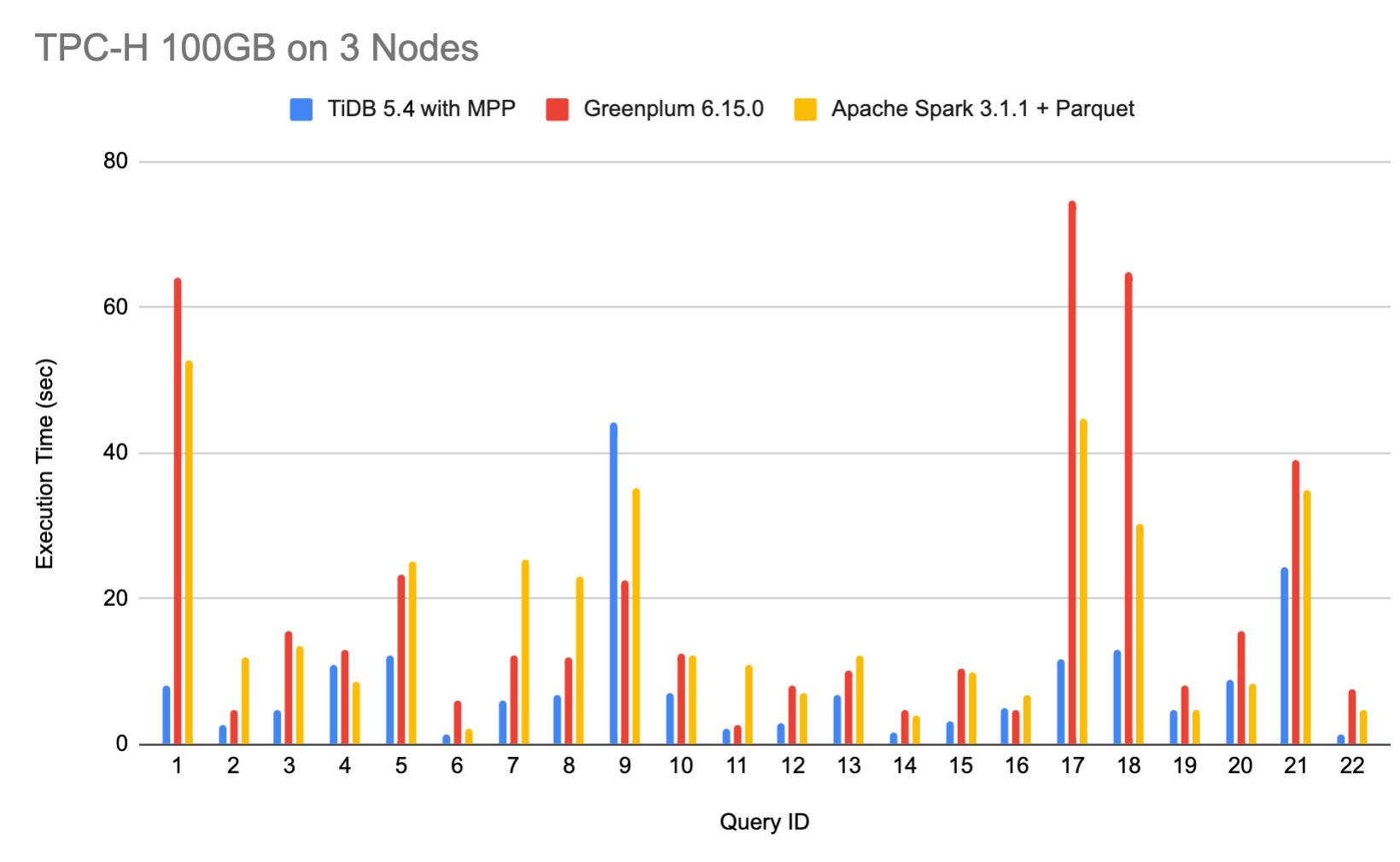
In the performance diagram above:
- Blue lines represent TiDB v5.4;
- Red lines represent Greenplum 6.15.0;
- Yellow lines represent Apache Spark 3.1.1.
- The y-axis represents the execution time of the query. The less the time is, the better the performance is.