Highly Concurrent Write Best Practices
This document describes best practices for handling highly-concurrent write-heavy workloads in TiDB, which can help to facilitate your application development.
Target audience
This document assumes that you have a basic understanding of TiDB. It is recommended that you first read the following three blog articles that explain TiDB fundamentals, and TiDB Best Practices:
Highly-concurrent write-intensive scenario
The highly concurrent write scenario often occurs when you perform batch tasks in applications, such as clearing, settlement and so on. This scenario has the following features:
- A huge volume of data
- The need to import historical data into database in a short time
- The need to read a huge volume of data from database in a short time
These features pose these challenges to TiDB:
- The write or read capacity must be linearly scalable.
- Database performance is stable and does not decrease as a huge volume of data is written concurrently.
For a distributed database, it is important to make full use of the capacity of all nodes and to prevent a single node from becoming the bottleneck.
Data distribution principles in TiDB
To address the above challenges, it is necessary to start with the data segmentation and scheduling principle of TiDB. Refer to Scheduling for more details.
TiDB splits data into Regions, each representing a range of data with a size limit of 96M by default. Each Region has multiple replicas, and each group of replicas is called a Raft Group. In a Raft Group, the Region Leader executes the read and write tasks within the data range. The Region Leader is automatically scheduled by the Placement Driver (PD) component to different physical nodes evenly to distribute the read and write pressure.
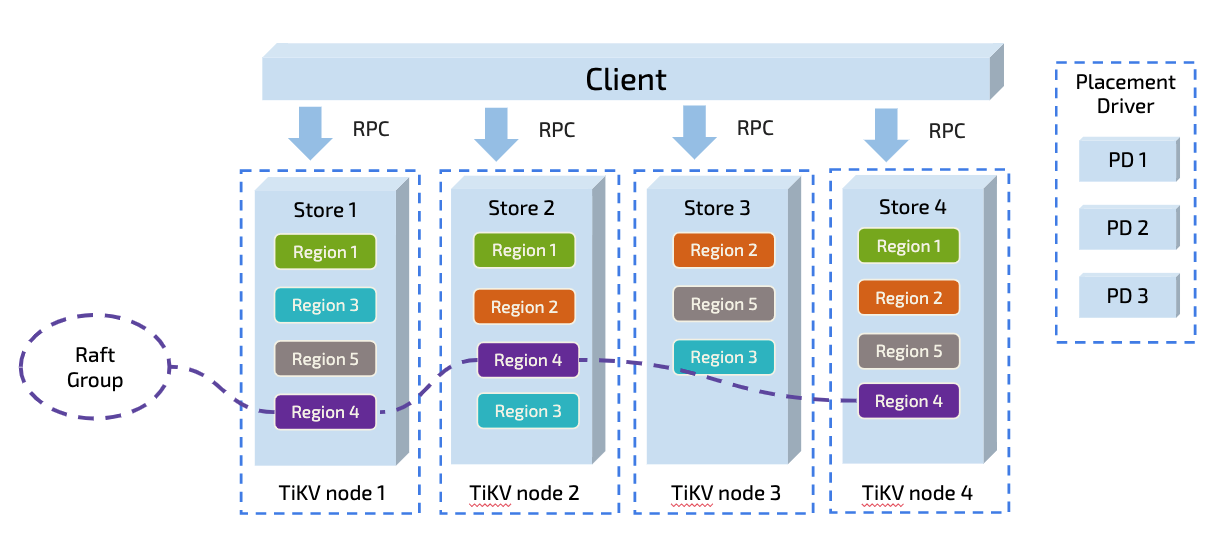
In theory, by the virtue of this architecture, TiDB can linearly scale its read and write capacities and make full use of the distributed resources so long as there is no AUTO_INCREMENT primary key in the write scenario, or there is no monotonically increasing index. From this point of view, TiDB is especially suitable for the highly-concurrent and write-intensive scenario. However, the actual situation often differs from the theoretical assumption.
Hotspot case
The following case explains how a hotspot is generated. Take the table below as an example:
CREATE TABLE IF NOT EXISTS TEST_HOTSPOT(
id BIGINT PRIMARY KEY,
age INT,
user_name VARCHAR(32),
email VARCHAR(128)
)
This table is simple in structure. In addition to id as the primary key, no secondary index exists. Execute the following statement to write data into this table. id is discretely generated as a random number.
INSERT INTO TEST_HOTSPOT(id, age, user_name, email) values(%v, %v, '%v', '%v');
The load comes from executing the above statement intensively in a short time.
In theory, the above operation seems to comply with the TiDB best practices, and no hotspot is caused in the application. The distributed capacity of TiDB can be fully used with adequate machines. To verify whether it is truly in line with the best practices, a test is conducted in the experimental environment, which is described as follows:
For the cluster topology, 2 TiDB nodes, 3 PD nodes and 6 TiKV nodes are deployed. Ignore the QPS performance, because this test is to clarify the principle rather than for benchmark.
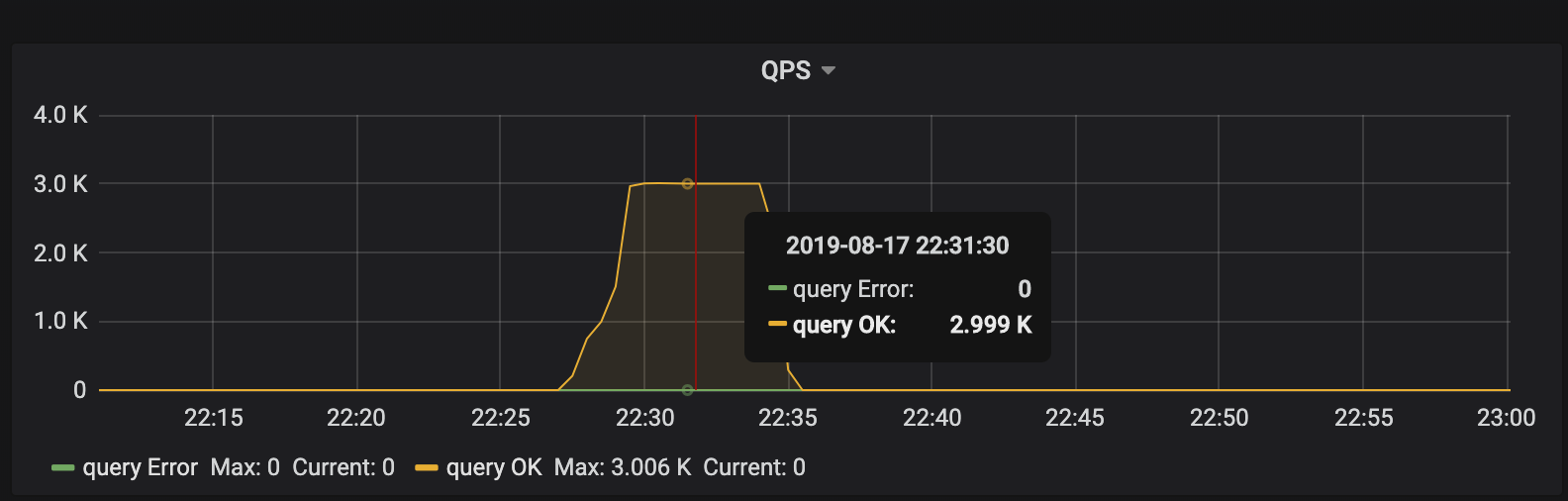
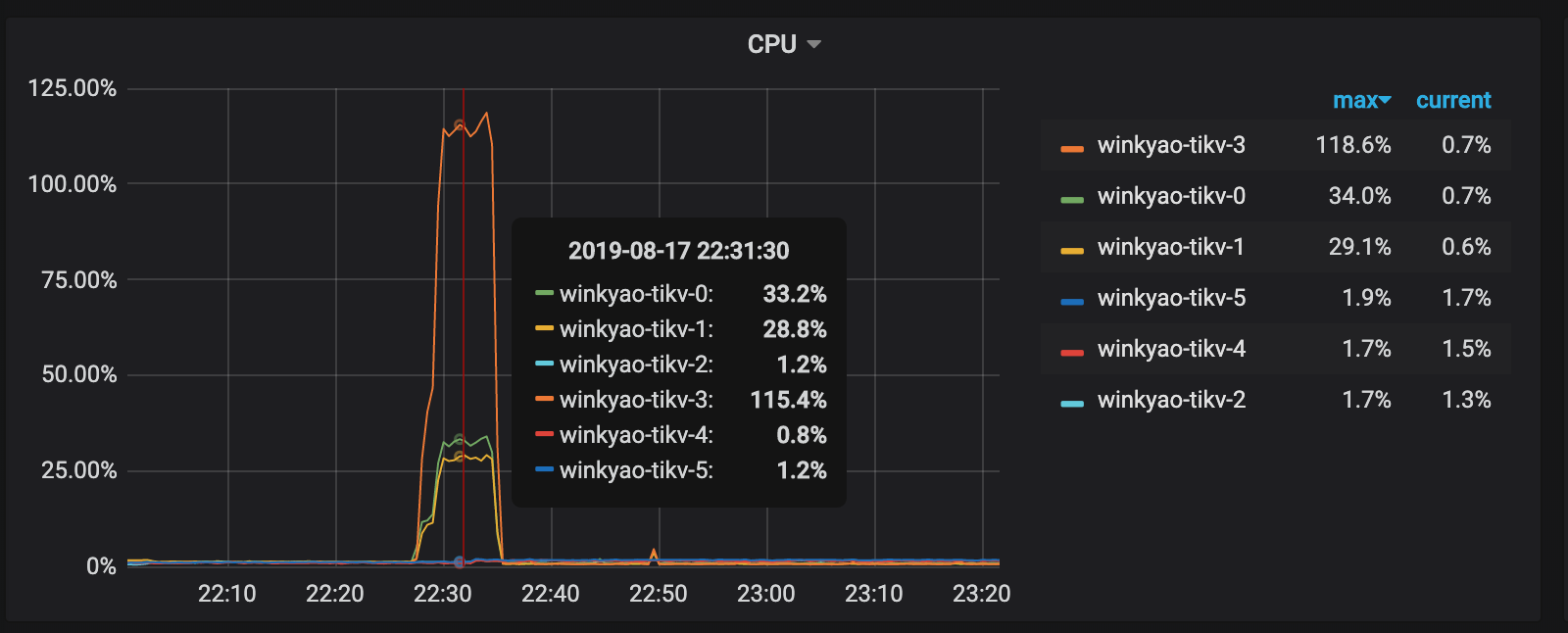
The client starts "intensive" write requests in a short time, which is 3K QPS received by TiDB. In theory, the load pressure should be evenly distributed to 6 TiKV nodes. However, from the CPU usage of each TiKV node, the load distribution is uneven. The tikv-3 node is the write hotspot.
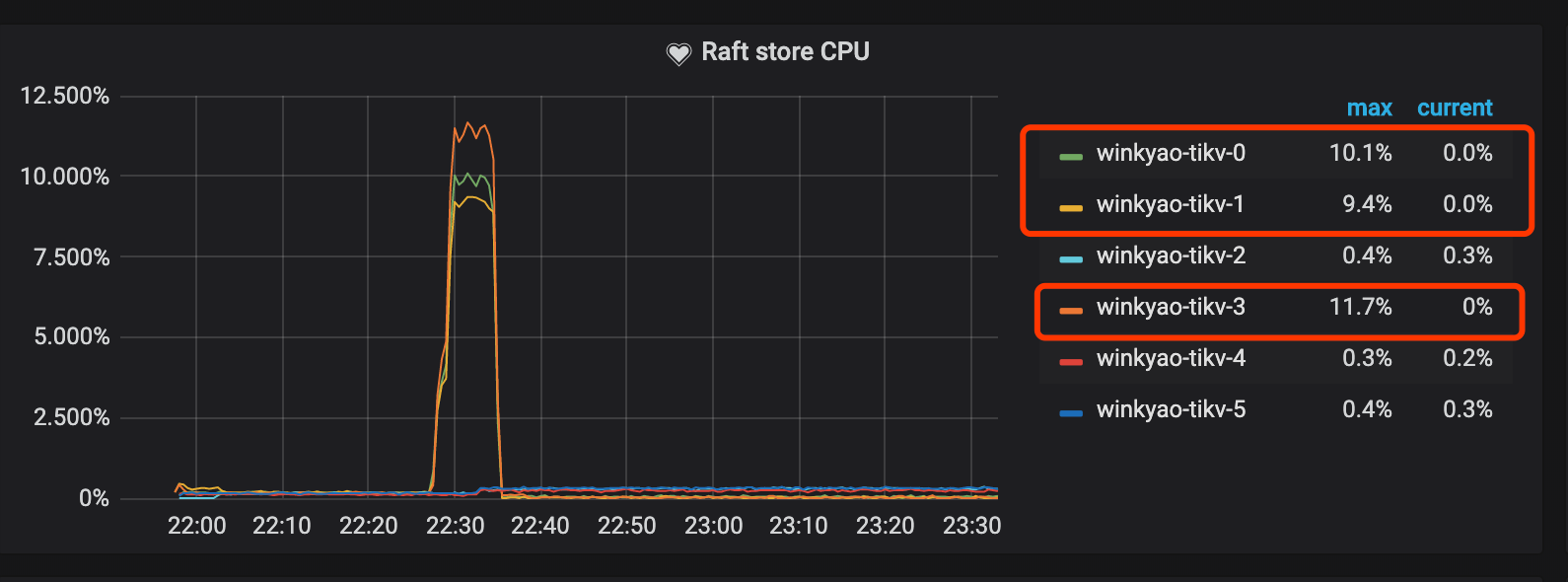
Raft store CPU is the CPU usage rate for the raftstore thread, usually representing the write load. In this scenario, tikv-3 is the Leader of this Raft Group; tikv-0 and tikv-1 are the followers. The loads of other nodes are almost empty.
The monitoring metrics of PD also confirms that hotspot has been caused.
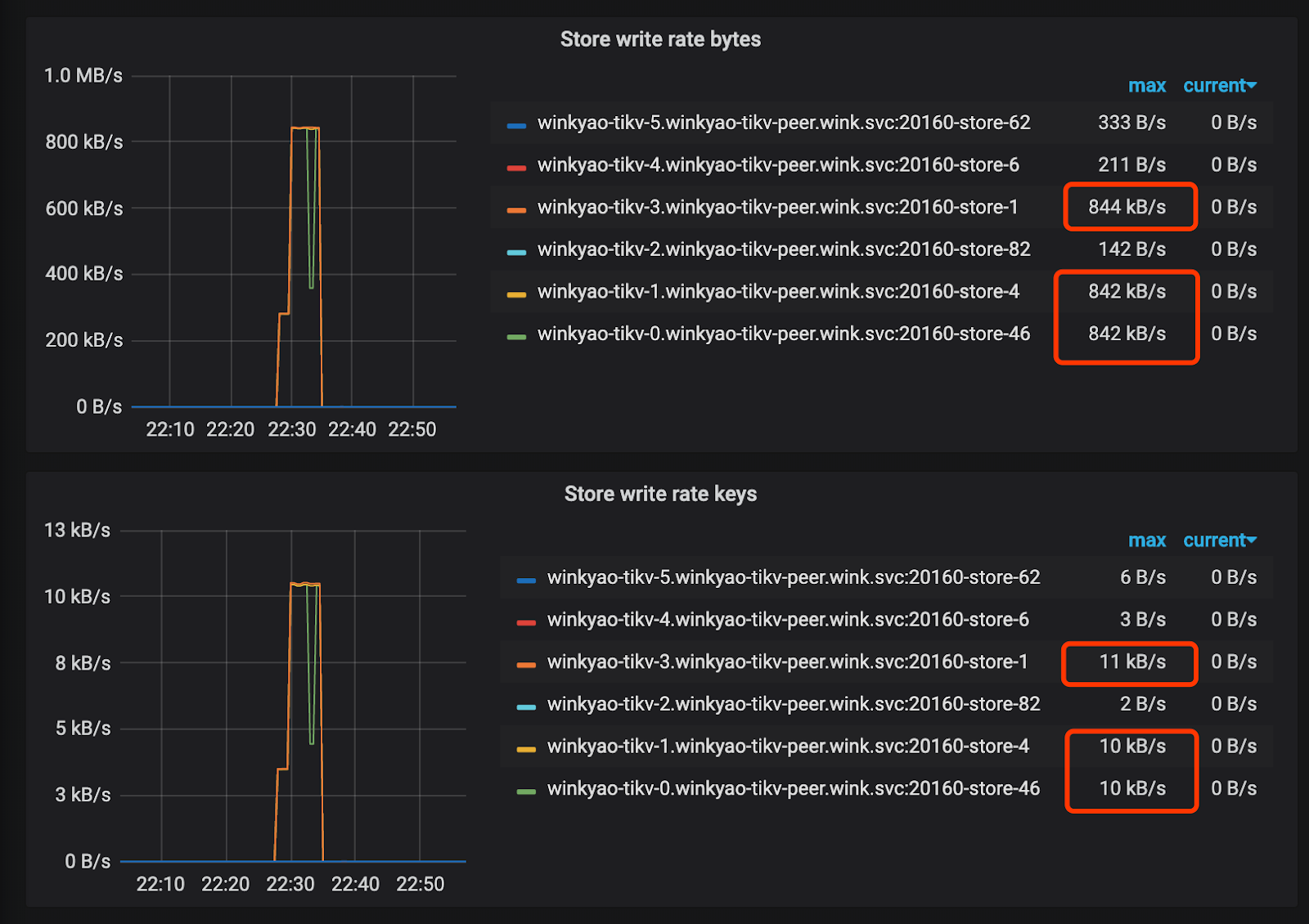
Hotspot causes
In the above test, the operation does not reach the ideal performance expected in the best practices. This is because only one Region is split by default to store the data of each newly created table in TiDB, with the following data range:
[CommonPrefix + TableID, CommonPrefix + TableID + 1)
In a short period of time, a huge volume of data is continuously written to the same Region.
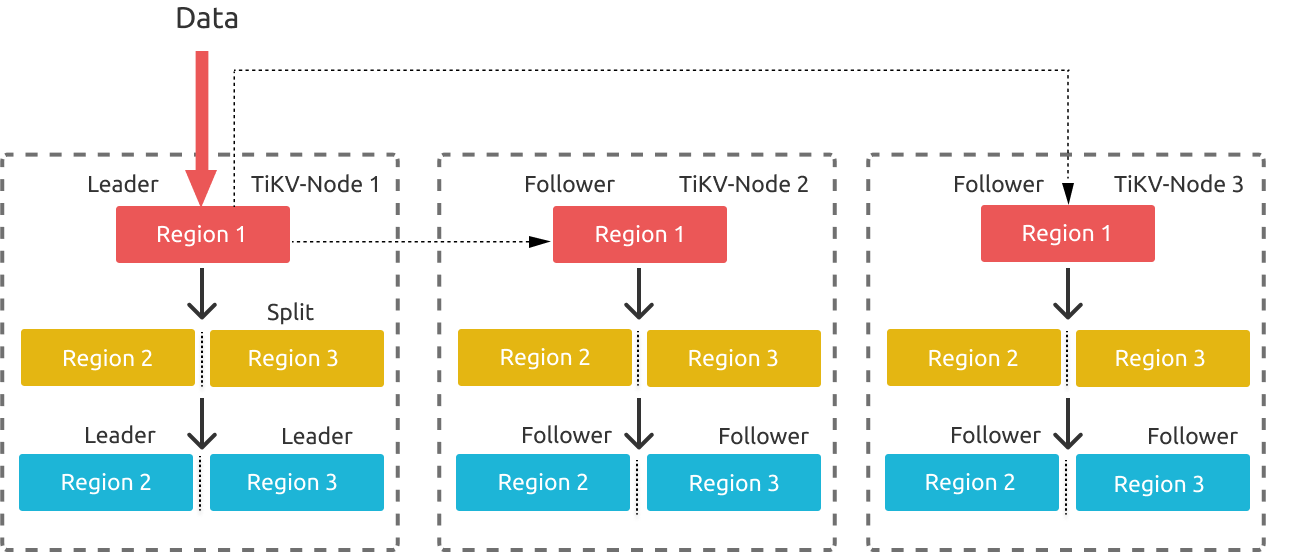
The above diagram illustrates the Region splitting process. As data is continuously written into TiKV, TiKV splits a Region into multiple Regions. Because the leader election is started on the original store where the Region Leader to be split is located, the leaders of the two newly split Regions might be still on the same store. This splitting process might also happen on the newly split Region 2 and Region 3. In this way, write pressure is concentrated on TiKV-Node 1.
During the continuous write process, after finding that hotspot is caused on Node 1, PD evenly distributes the concentrated Leaders to other nodes. If the number of TiKV nodes is more than the number of Region replicas, TiKV will try to migrate these Regions to idle nodes. These two operations during the write process are also reflected in the PD's monitoring metrics:
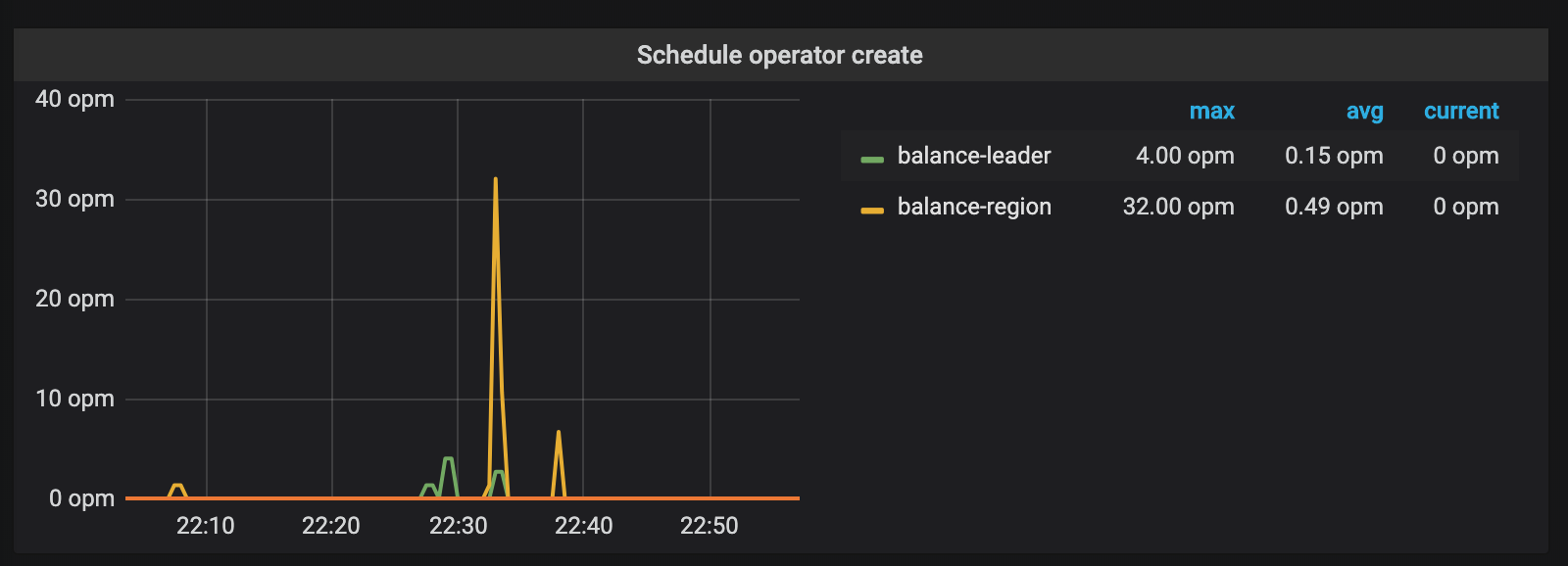
After a period of continuous writes, PD automatically schedules the entire TiKV cluster to a state where pressure is evenly distributed. By that time, the capacity of the whole cluster can be fully used.
In most cases, the above process of causing a hotspot is normal, which is the Region warm-up phase of database. However, you need to avoid this phase in highly-concurrent write-intensive scenarios.
Hotspot solution
To achieve the ideal performance expected in theory, you can skip the warm-up phase by directly splitting a Region into the desired number of Regions and scheduling these Regions in advance to other nodes in the cluster.
In v3.0.x, v2.1.13 and later versions, TiDB supports a new feature called Split Region. This new feature provides the following new syntaxes:
SPLIT TABLE table_name [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num
SPLIT TABLE table_name [INDEX index_name] BY (value_list) [, (value_list)]
However, TiDB does not automatically perform this pre-split operation. The reason is related to the data distribution in TiDB.
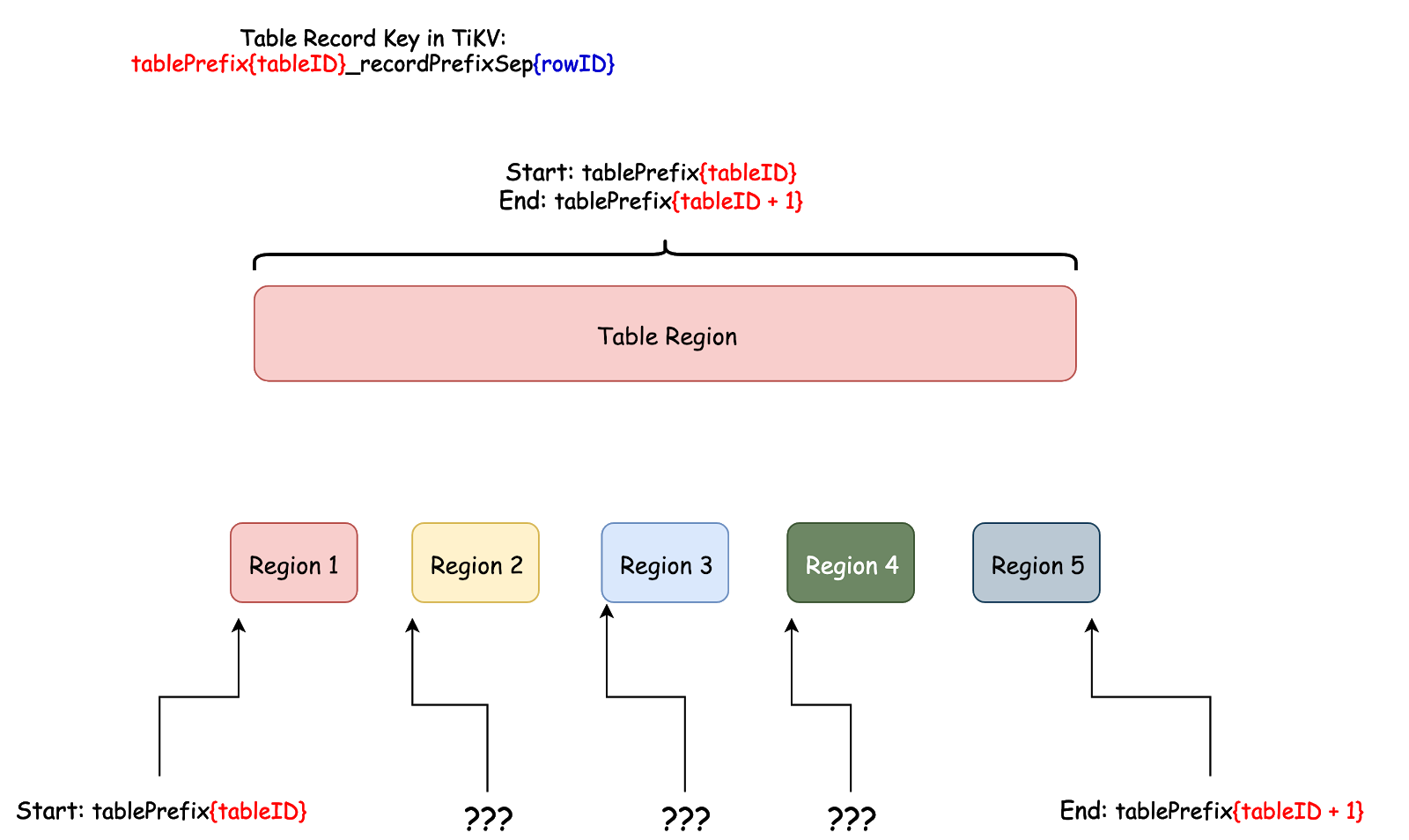
From the diagram above, according to the encoding rule of a row's key, the rowID is the only variable part. In TiDB, rowID is an Int64 integer. However, you might not need to evenly split the Int64 integer range to the desired number of ranges and then to distribute these ranges to different nodes, because Region split must also be based on the actual situation.
If the write of rowID is completely discrete, the above method will not cause hotspots. If the row ID or index has a fixed range or prefix (for example, discretely insert data into the range of [2000w, 5000w)), no hotspot will be caused either. However, if you split a Region using the above method, data might still be written to the same Region at the beginning.
TiDB is a database for general usage and does not make assumptions about the data distribution. So it uses only one Region at the beginning to store the data of a table and automatically splits the Region according to the data distribution after real data is inserted.
Given this situation and the need to avoid the hotspot problem, TiDB offers the Split Region syntax to optimize performance for the highly-concurrent write-heavy scenario. Based on the above case, now scatter Regions using the Split Region syntax and observe the load distribution.
Because the data to be written in the test is entirely discrete within the positive range, you can use the following statement to pre-split the table into 128 Regions within the range of minInt64 and maxInt64:
SPLIT TABLE TEST_HOTSPOT BETWEEN (0) AND (9223372036854775807) REGIONS 128;
After the pre-split operation, execute the SHOW TABLE test_hotspot REGIONS; statement to check the status of Region scattering. If the values of the SCATTERING column are all 0, the scheduling is successful.
You can also check the Region distribution using the table-regions.py script. Currently, the Region distribution is relatively even:
[root@172.16.4.4 scripts]# python table-regions.py --host 172.16.4.3 --port 31453 test test_hotspot
[RECORD - test.test_hotspot] - Leaders Distribution:
total leader count: 127
store: 1, num_leaders: 21, percentage: 16.54%
store: 4, num_leaders: 20, percentage: 15.75%
store: 6, num_leaders: 21, percentage: 16.54%
store: 46, num_leaders: 21, percentage: 16.54%
store: 82, num_leaders: 23, percentage: 18.11%
store: 62, num_leaders: 21, percentage: 16.54%
Then operate the write load again:
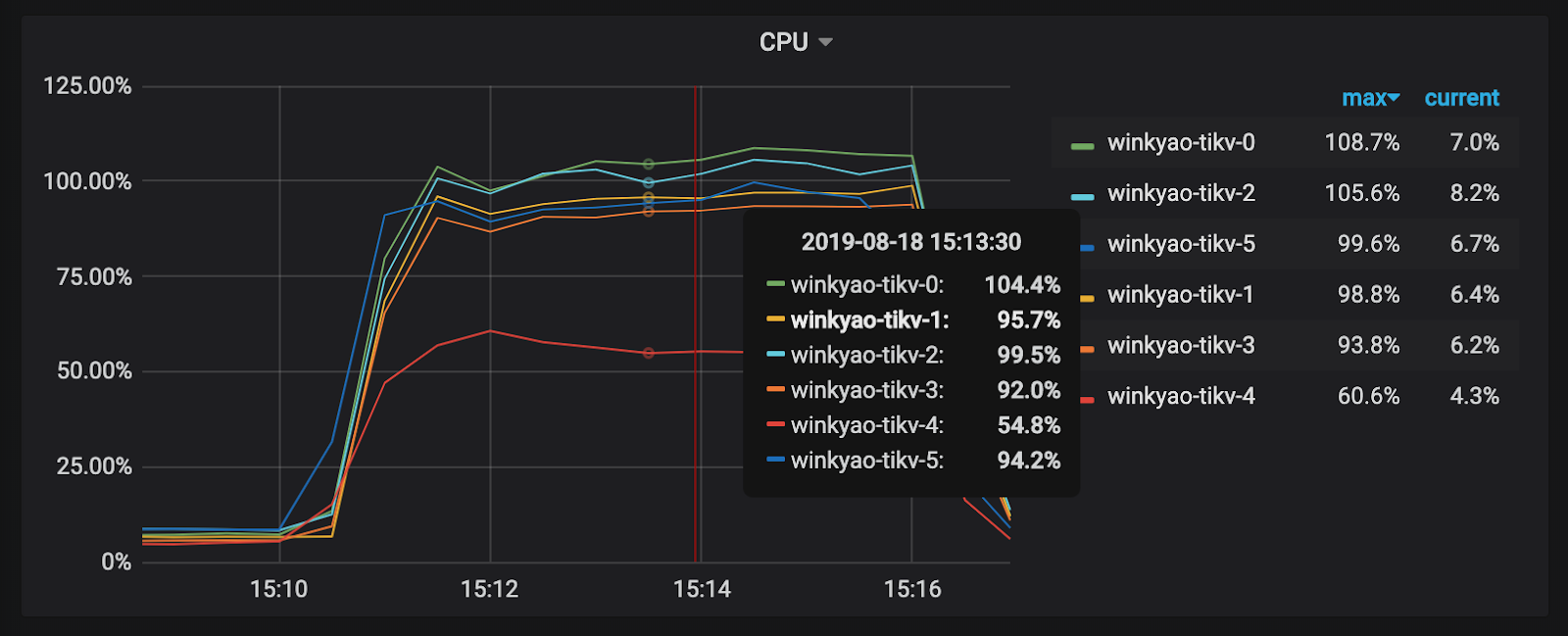
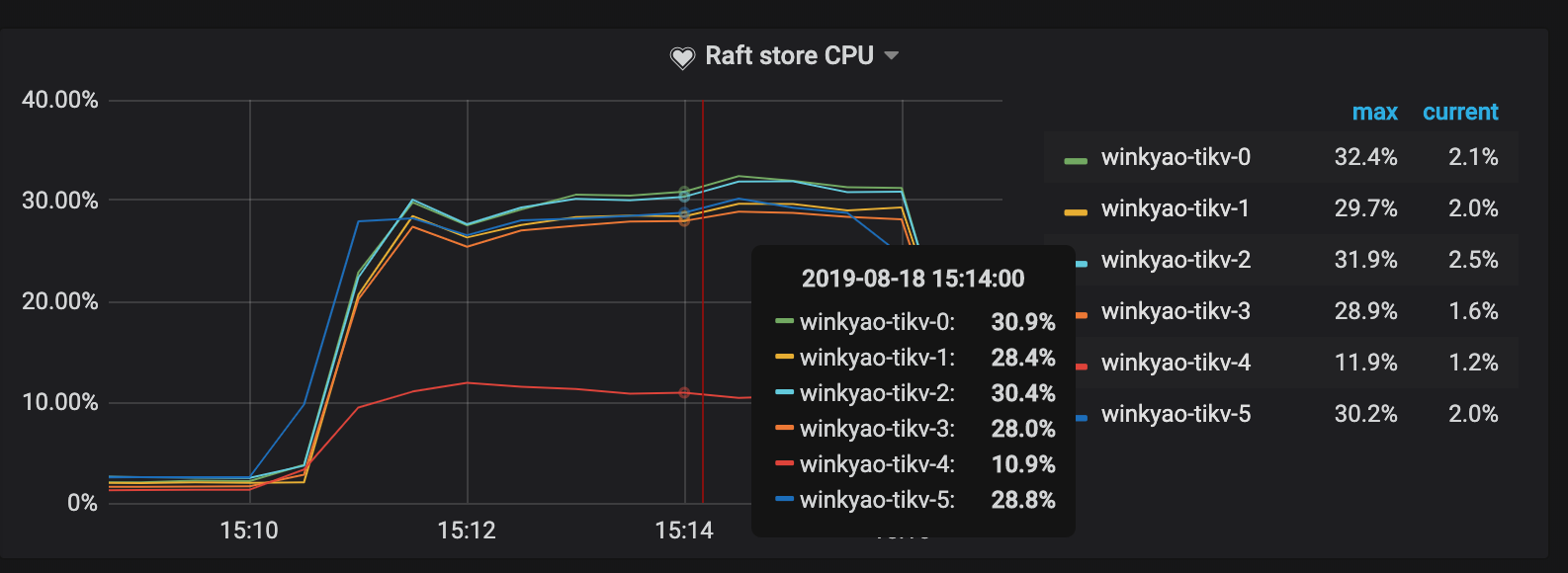
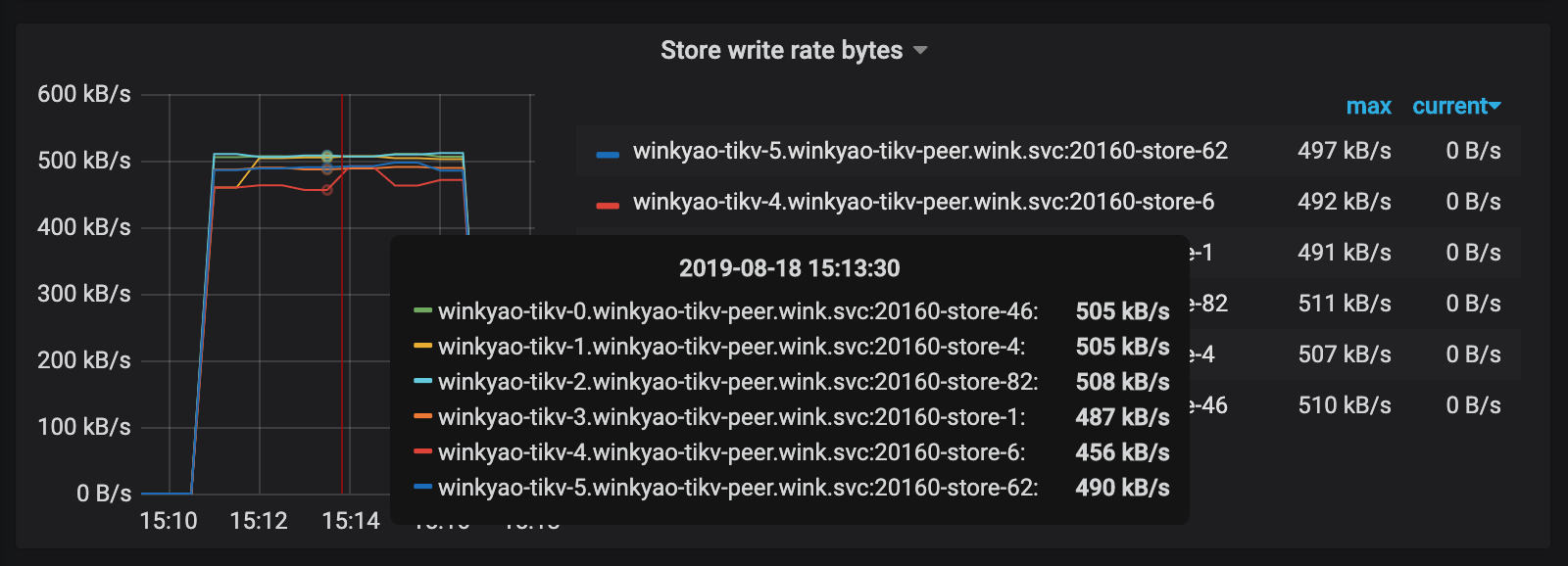
You can see that the apparent hotspot problem has been resolved now.
In this case, the table is simple. In other cases, you might also need to consider the hotspot problem of index. For more details on how to pre-split the index Region, refer to Split Region.
Complex hotspot problems
Problem one:
If a table does not have a primary key, or the primary key is not the Int type and you do not want to generate a randomly distributed primary key ID, TiDB provides an implicit _tidb_rowid column as the row ID. Generally, when you do not use the SHARD_ROW_ID_BITS parameter, the values of the _tidb_rowid column are also monotonically increasing, which might causes hotspots too. Refer to SHARD_ROW_ID_BITS description for more details.
To avoid the hotspot problem in this situation, you can use SHARD_ROW_ID_BITS and PRE_SPLIT_REGIONS when creating a table. For more details about PRE_SPLIT_REGIONS, refer to Pre-split Regions.
SHARD_ROW_ID_BITS is used to randomly scatter the row ID generated in the _tidb_rowid column. PRE_SPLIT_REGIONS is used to pre-split the Region after a table is created.
This variable controls whether to wait for Regions to be pre-split and scattered before returning results after the table creation. If there are intensive writes after creating the table, you need to set the value of this variable to 1, then TiDB will not return the results to the client until all the Regions are split and scattered. Otherwise, TiDB writes data before the scattering is completed, which will have a significant impact on write performance.
Example:
create table t (a int, b int) SHARD_ROW_ID_BITS = 4 PRE_SPLIT_REGIONS=3;
SHARD_ROW_ID_BITS = 4means that the values oftidb_rowidwill be randomly distributed into 16 (16=2^4) ranges.PRE_SPLIT_REGIONS=3means that the table will be pre-split into 8 (2^3) Regions after it is created.
When data starts to be written into table t, the data is written into the pre-split 8 Regions, which avoids the hotspot problem that might be caused if only one Region exists after table creation.
Problem two:
If a table's primary key is an integer type, and if the table uses AUTO_INCREMENT to ensure the uniqueness of the primary key (not necessarily continuous or incremental), you cannot use SHARD_ROW_ID_BITS to scatter the hotspot on this table because TiDB directly uses the row values of the primary key as _tidb_rowid.
To address the problem in this scenario, you can replace AUTO_INCREMENT with AUTO_RANDOM (a column attribute) when inserting data. Then TiDB automatically assigns values to the integer primary key column, which eliminates the continuity of the row ID and scatters the hotspot.
Parameter configuration
In v2.1, the latch mechanism is introduced in TiDB to identify transaction conflicts in advance in scenarios where write conflicts frequently appear. The aim is to reduce the retry of transaction commits in TiDB and TiKV caused by write conflicts. Generally, batch tasks use the data already stored in TiDB, so the write conflicts of transaction do not exist. In this situation, you can disable the latch in TiDB to reduce memory allocation for small objects:
[txn-local-latches]
enabled = false