ホットスポットの問題のトラブルシューティング
このドキュメントでは、読み取りホットスポットと書き込みホットスポットの問題を特定して解決する方法について説明します。
分散型データベースとして、TiDB には負荷分散メカニズムがあり、アプリケーションの負荷を異なるコンピューティング ノードまたはストレージ ノードにできるだけ均等に分散して、サーバーリソースをより有効に活用します。ただし、特定のシナリオでは、一部のアプリケーションの負荷を適切に分散できず、パフォーマンスに影響を与え、ホットスポットとも呼ばれる単一の高負荷ポイントを形成する可能性があります。
TiDB は、ホットスポットのトラブルシューティング、解決、または回避のための完全なソリューションを提供します。負荷のホットスポットのバランスを取ることで、QPS の向上やレイテンシーの短縮など、全体的なパフォーマンスを向上させることができます。
一般的なホットスポット
このセクションでは、TiDB のエンコード規則、テーブルのホットスポット、およびインデックスのホットスポットについて説明します。
TiDB エンコーディング規則
TiDB は、各テーブルに TableID、各インデックスに IndexID、および各行に RowID を割り当てます。デフォルトでは、テーブルが整数の主キーを使用する場合、主キーの値が RowID として扱われます。これらの ID のうち、TableID はクラスター全体で一意であり、IndexID と RowID はテーブル内で一意です。これらすべての ID の型は int64 です。
データの各行は、次のルールに従ってキーと値のペアとしてエンコードされます。
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]
キーのtablePrefixとrecordPrefixSepは特定の文字列定数で、KV 空間内の他のデータと区別するために使用されます。
インデックス データの場合、キーと値のペアは次の規則に従ってエンコードされます。
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID
索引データには、固有索引と非固有索引の 2 つのタイプがあります。
一意のインデックスの場合、上記のコーディング ルールに従うことができます。
一意でないインデックスの場合、同じインデックスの
tablePrefix{tableID}_indexPrefixSep{indexID}つが同じであり、複数の行のColumnsValueが同じである可能性があるため、このエンコーディングを使用して一意のキーを構築することはできません。一意でないインデックスのエンコード規則は次のとおりです。Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID Value: null
テーブルのホットスポット
TiDB のコーディング規則に従い、同じテーブルのデータは TableID の先頭から始まる範囲にあり、RowID 値の順にデータが配置されます。テーブルの挿入中に RowID 値がインクリメントされると、挿入された行は最後にしか追加できません。 リージョンは、特定のサイズに達すると分割されますが、範囲の最後にのみ追加できます。 INSERT操作は、ホットスポットを形成する 1 つのリージョンでのみ実行できます。
共通の自動インクリメント主キーは順次増加しています。主キーが整数型の場合、デフォルトで主キーの値が RowID として使用されます。このとき、RowID は順次増加しており、多数のINSERT操作が存在すると、テーブルの書き込みホットスポットが形成されます。
一方、TiDB の RowID もデフォルトで順次自動インクリメントされます。主キーが整数型でない場合、書き込みホットスポットの問題が発生する可能性もあります。
さらに、データ書き込み (新しく作成されたテーブルまたはパーティションで) またはデータ読み取り (読み取り専用シナリオでの定期的な読み取りホットスポット) のプロセス中にホットスポットが発生した場合、テーブル属性を使用してリージョンのマージ動作を制御できます。詳細については、 テーブル属性を使用してリージョン結合動作を制御するを参照してください。
インデックスのホットスポット
インデックス ホットスポットは、テーブル ホットスポットに似ています。一般的なインデックス ホットスポットは、時間順に単調に増加するフィールド、または多数の反復値を含むINSERTのシナリオに表示されます。
ホットスポットの問題を特定する
パフォーマンスの問題は必ずしもホットスポットが原因ではなく、複数の要因が原因である可能性があります。問題のトラブルシューティングを行う前に、問題がホットスポットに関連しているかどうかを確認してください。
書き込みホットスポットを判断するには、 TiKV-Trouble-Shootingモニタリング パネルでホット ライトを開き、TiKV ノードの Raftstore CPU メトリック値が他のノードよりも大幅に高いかどうかを確認します。
読み取りホットスポットを判断するには、 TiKV-Detailsモニタリング パネルでThread_CPUを開き、TiKV ノードのコプロセッサ CPU メトリック値が特に高いかどうかを確認します。
TiDB ダッシュボードを使用してホットスポット テーブルを見つける
TiDB ダッシュボードのキー ビジュアライザー機能は、ユーザーがホットスポットのトラブルシューティングの範囲をテーブル レベルに絞り込むのに役立ちます。以下は、 Key Visualizerで表示されるサーマル ダイアグラムの例です。グラフの横軸は時間、縦軸は各種表と指標です。色が明るいほど、負荷が大きくなります。ツールバーで読み取りまたは書き込みフローを切り替えることができます。
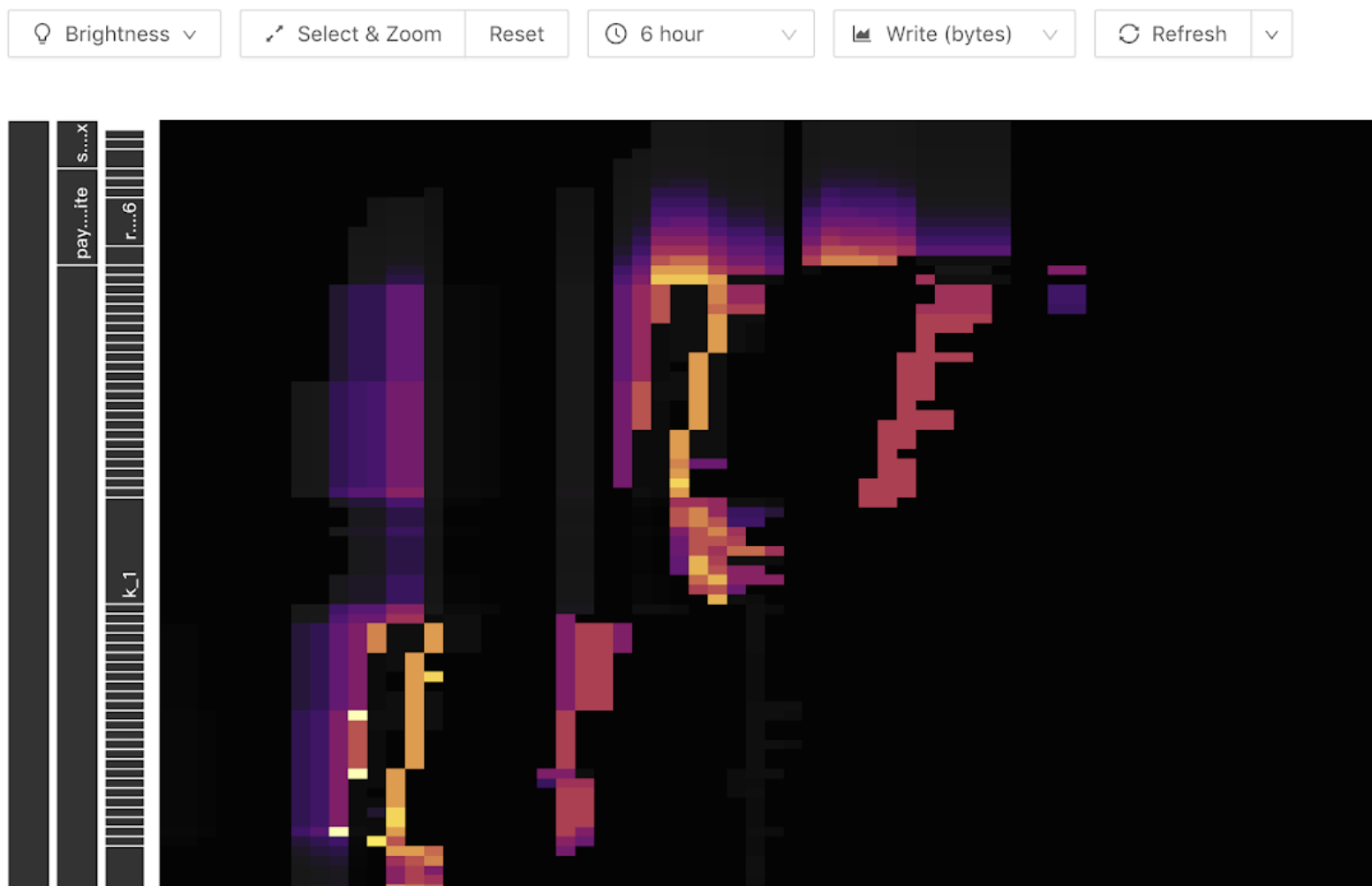
次の明るい斜線 (斜め上または下) は、書き込みフロー グラフに表示されることがあります。書き込みは最後にしか表示されないため、テーブル Region の数が増えるにつれて、はしごのように表示されます。これは、書き込みホットスポットが次の表に示されていることを示しています。

読み取りホットスポットの場合、通常、サーマル ダイアグラムに明るい水平線が表示されます。通常、これらは、次のように、アクセス数が多い小さなテーブルが原因で発生します。

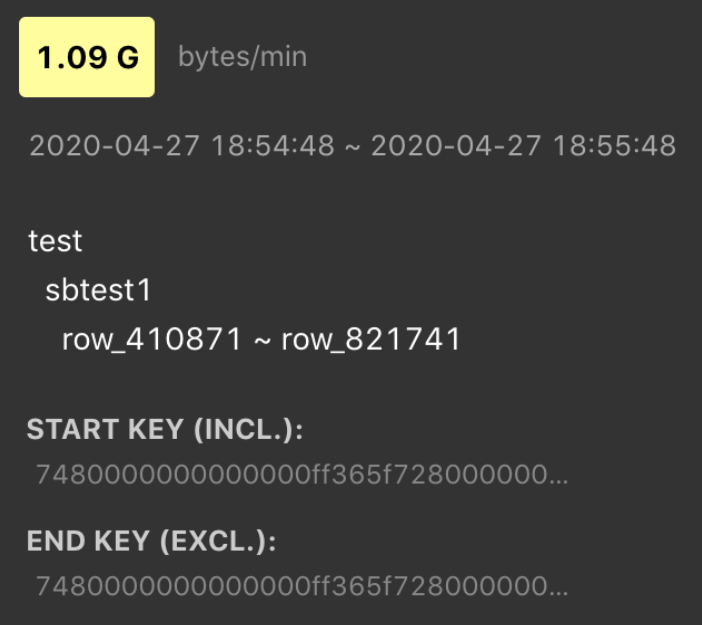
明るいブロックにカーソルを合わせると、どのテーブルまたはインデックスに負荷がかかっているかがわかります。例えば:
SHARD_ROW_ID_BITSを使用してホットスポットを処理する
整数でない主キー、または主キーまたは結合主キーのないテーブルの場合、TiDB は暗黙的な自動インクリメント RowID を使用します。 INSERT操作が多数存在する場合、データは単一のリージョンに書き込まれ、書き込みホットスポットが発生します。
SHARD_ROW_ID_BITSを設定すると、行 ID が分散されて複数のリージョンに書き込まれるため、書き込みホットスポットの問題を軽減できます。
SHARD_ROW_ID_BITS = 4 # Represents 16 shards.
SHARD_ROW_ID_BITS = 6 # Represents 64 shards.
SHARD_ROW_ID_BITS = 0 # Represents the default 1 shard.
ステートメントの例:
CREATE TABLE: CREATE TABLE t (c int) SHARD_ROW_ID_BITS = 4;
ALTER TABLE: ALTER TABLE t SHARD_ROW_ID_BITS = 4;
SHARD_ROW_ID_BITSの値は動的に変更できます。変更された値は、新しく書き込まれたデータに対してのみ有効です。
CLUSTERED型の主キーを持つテーブルの場合、TiDB はテーブルの主キーを RowID として使用します。現時点では、RowID の生成規則が変更されるため、オプションSHARD_ROW_ID_BITSは使用できません。 NONCLUSTERED型の主キーを持つテーブルの場合、TiDB は自動的に割り当てられた 64 ビット整数を RowID として使用します。この場合、 SHARD_ROW_ID_BITS機能を使用できます。 CLUSTEREDタイプの主キーの詳細については、 クラスター化インデックスを参照してください。
次の 2 つの負荷図は、主キーのない 2 つのテーブルがSHARD_ROW_ID_BITSを使用してホットスポットを分散させている場合を示しています。最初の図はホットスポットを分散させる前の状況を示し、2 つ目の図はホットスポットを分散させた後の状況を示しています。
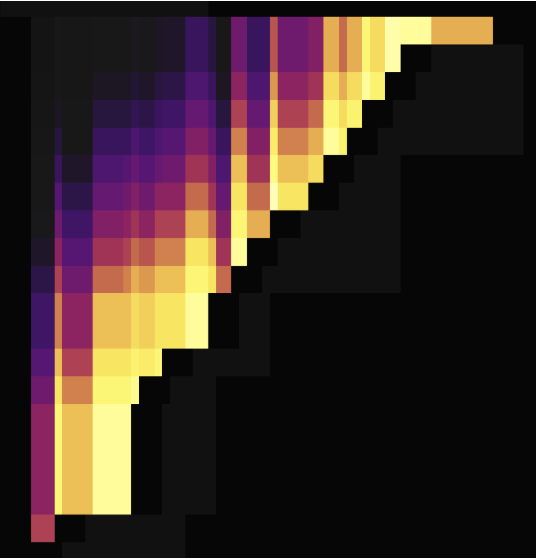
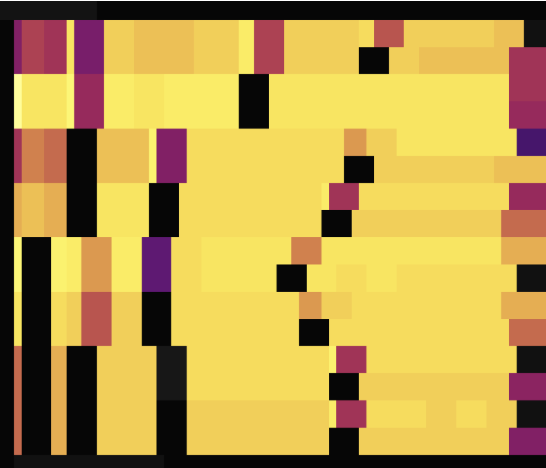
上記の負荷図に示されているように、 SHARD_ROW_ID_BITSを設定する前は、負荷のホットスポットは 1 つのリージョンに集中しています。 SHARD_ROW_ID_BITSを設定すると、負荷のホットスポットが分散します。
AUTO_RANDOMを使用して自動インクリメント主キー ホットスポット テーブルを処理する
自動インクリメント主キーによる書き込みホットスポットを解決するには、 AUTO_RANDOMを使用して、自動インクリメント主キーを持つホットスポット テーブルを処理します。
この機能が有効になっている場合、TiDB はランダムに分散され、繰り返されない (スペースが使い果たされる前に) 主キーを生成して、書き込みホットスポットを分散させるという目的を達成します。
TiDB によって生成された主キーは自動インクリメントの主キーではなくなり、 LAST_INSERT_ID()を使用して前回割り当てられた主キーの値を取得できることに注意してください。
この機能を使用するには、 CREATE TABLEステートメントのAUTO_INCREMENTからAUTO_RANDOMを変更します。この機能は、主キーが一意性のみを保証する必要があるアプリケーション以外のシナリオに適しています。
例えば:
CREATE TABLE t (a BIGINT PRIMARY KEY AUTO_RANDOM, b varchar(255));
INSERT INTO t (b) VALUES ("foo");
SELECT * FROM t;
+------------+---+
| a | b |
+------------+---+
| 1073741825 | b |
+------------+---+
SELECT LAST_INSERT_ID();
+------------------+
| LAST_INSERT_ID() |
+------------------+
| 1073741825 |
+------------------+
次の 2 つの負荷図は、ホットスポットを分散させるためにAUTO_INCREMENTからAUTO_RANDOMを変更する前後の状況を示しています。最初のものはAUTO_INCREMENTを使用し、2 番目のものはAUTO_RANDOMを使用します。
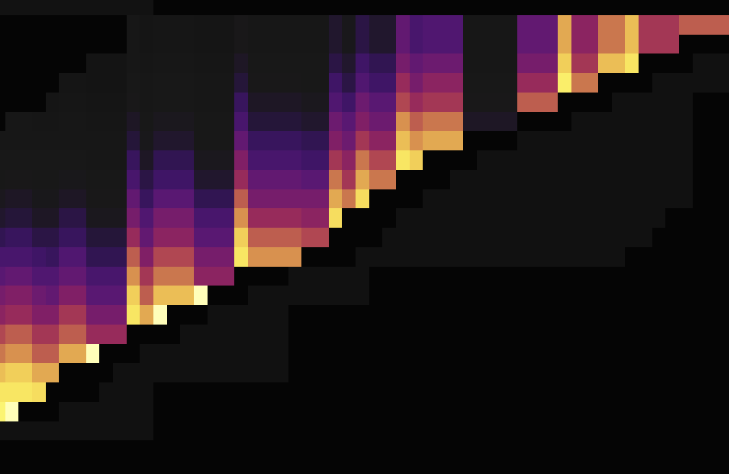

上記の負荷図に示されているように、 AUTO_RANDOMを使用してAUTO_INCREMENTを置き換えると、ホットスポットを分散させることができます。
詳細については、 自動ランダムを参照してください。
小さなテーブルのホットスポットの最適化
TiDB のコプロセッサ キャッシュ機能は、計算結果キャッシュのプッシュ ダウンをサポートしています。この機能を有効にすると、TiDB は TiKV にプッシュされる計算結果をキャッシュします。この機能は、小さなテーブルの読み取りホットスポットに適しています。
詳細については、 コプロセッサ キャッシュを参照してください。
以下も参照してください。