TiSpark ユーザーガイド
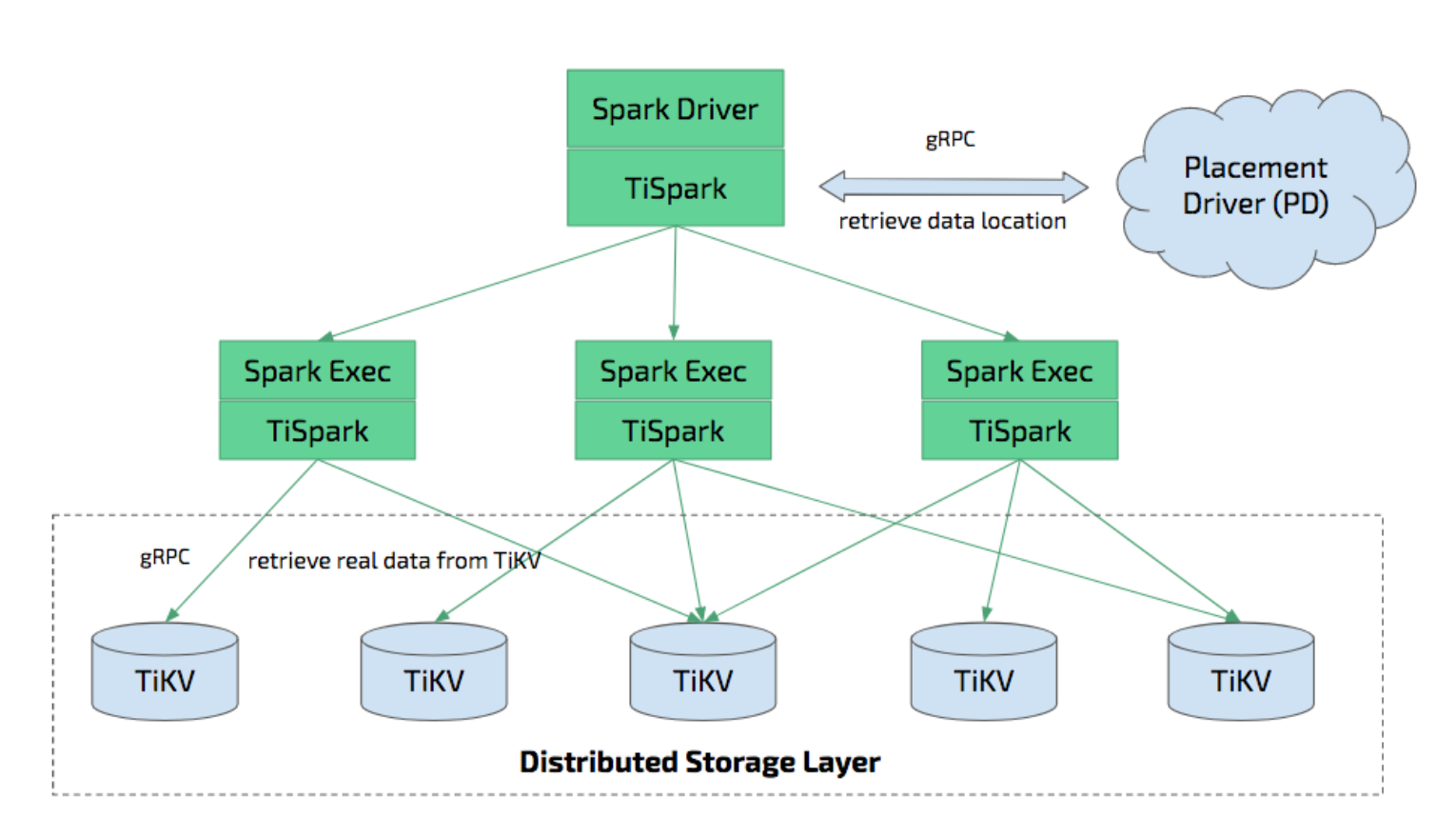
ティスパークは、TiDB/TiKV 上で Apache Spark を実行して複雑な OLAP クエリに応答するために構築されたシンレイヤーです。 Spark プラットフォームと分散 TiKV クラスターの両方を利用し、分散 OLTP データベースである TiDB にシームレスに接着して、ハイブリッド トランザクション/分析処理 (HTAP) ソリューションを提供し、オンライン トランザクションと分析の両方のワンストップ ソリューションとして機能します。 .
ティフラッシュは、HTAP を有効にする別のツールです。 TiFlash と TiSpark の両方で、複数のホストを使用して OLTP データに対して OLAP クエリを実行できます。 TiFlash はデータを列形式で格納するため、より効率的な分析クエリが可能になります。 TiFlash と TiSpark は併用できます。
TiSpark は、TiKV クラスターと PD クラスターに依存します。また、Spark クラスターをセットアップする必要があります。このドキュメントでは、TiSpark のセットアップ方法と使用方法を簡単に紹介します。 Apache Spark の基本的な知識が必要です。詳細については、 アパッチスパークのウェブサイトを参照してください。
Spark Catalyst Engine と緊密に統合された TiSpark は、コンピューティングを正確に制御します。これにより、Spark は TiKV から効率的にデータを読み取ることができます。 TiSpark は、高速なポイント クエリを可能にするインデックス シークもサポートしています。
TiSpark は、コンピューティングを TiKV にプッシュすることでデータ クエリを高速化し、Spark SQL によって処理されるデータの量を削減します。一方、TiSpark は TiDB の組み込み統計を使用して、最適なクエリ プランを選択できます。
TiSpark と TiDB を使用すると、ETL を構築して維持することなく、トランザクションと分析の両方のタスクを同じプラットフォームで実行できます。これにより、システムアーキテクチャが簡素化され、メンテナンスのコストが削減されます。
TiDB でのデータ処理には、Spark エコシステムのツールを使用できます。
- TiSpark: データ分析と ETL
- TiKV: データ検索
- スケジューリング システム: レポート生成
また、TiSpark は TiKV への分散書き込みをサポートしています。 Spark および JDBC を使用した TiDB への書き込みと比較して、TiKV への分散書き込みはトランザクションを実装でき (すべてのデータが正常に書き込まれるか、すべての書き込みが失敗する)、書き込みが高速になります。
環境設定
次の表に、サポートされている TiSpark バージョンの互換性情報を示します。必要に応じて TiSpark のバージョンを選択できます。
| TiSpark バージョン | TiDB、TiKV、および PD バージョン | スパークバージョン | Scala バージョン |
|---|---|---|---|
| 2.4.x-scala_2.11 | 5.x、4.x | 2.3.x、2.4.x | 2.11 |
| 2.4.x-scala_2.12 | 5.x、4.x | 2.4.x | 2.12 |
| 2.5.x | 5.x、4.x | 3.0.x、3.1.x | 2.12 |
| 3.0.x | 5.x、4.x | 3.0.x、3.1.x、3.2.x | 2.12 |
TiSpark は、YARN、Mesos、スタンドアロンなどの任意の Spark モードで実行されます。
推奨構成
このセクションでは、TiKV と TiSpark の独立した展開、Spark と TiSpark の独立した展開、および TiKV と TiSpark の共同展開の推奨構成について説明します。
TiUP を使用して TiSpark をデプロイする方法の詳細については、 TiSpark 導入トポロジも参照してください。
TiKV と TiSpark の独立した展開のConfiguration / コンフィグレーション
TiKV と TiSpark を個別に展開するには、次の推奨事項を参照することをお勧めします。
- ハードウェア構成
- 一般的な目的については、TiDB および TiKV ハードウェア構成推奨事項を参照してください。
- 分析シナリオにより重点を置いて使用する場合は、TiKV ノードのメモリを少なくとも 64G に増やすことができます。
Spark と TiSpark の独立した展開のConfiguration / コンフィグレーション
詳細なハードウェアの推奨事項については、 スパーク公式サイトを参照してください。以下は、TiSpark 構成の簡単な概要です。
Spark に 32G メモリを割り当て、オペレーティング システムとバッファ キャッシュ用に少なくとも 25% のメモリを確保することをお勧めします。
Spark のマシンごとに、少なくとも 8 から 16 のコアをプロビジョニングすることをお勧めします。最初に、すべての CPU コアを Spark に割り当てることができます。
共同展開された TiKV と TiSpark のConfiguration / コンフィグレーション
TiKV と TiSpark を共同展開するには、TiSpark に必要なリソースを TiKV の予約済みリソースに追加し、システムにメモリの 25% を割り当てます。
TiSpark クラスターをデプロイ
TiSpark の jar パッケージここをダウンロードし、 $SPARKPATH/jarsフォルダーに配置します。
ノート:
TiSpark v2.1.x 以前のバージョンのファイル名は
tispark-core-2.1.9-spark_2.4-jar-with-dependencies.jarのようになります。必要なバージョンの正確なファイル名については、 GitHub のリリース ページを確認してください。
以下は、TiSpark v2.4.1 のインストール方法の簡単な例です。
wget https://github.com/pingcap/tispark/releases/download/v2.4.1/tispark-assembly-2.4.1.jar
mv tispark-assembly-2.4.1.jar $SPARKPATH/jars/
spark-defaults.conf.templateファイルからspark-defaults.confをコピーします。
cp conf/spark-defaults.conf.template conf/spark-defaults.conf
spark-defaults.confファイルに、次の行を追加します。
spark.tispark.pd.addresses $pd_host:$pd_port
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addressesの構成では、複数の PD サーバーを配置できます。それぞれのポート番号を指定します。たとえば、ポート 2379 の10.16.20.1,10.16.20.2,10.16.20.3に複数の PD サーバーがある場合は、 10.16.20.1:2379,10.16.20.2:2379,10.16.20.3:2379とします。
ノート:
TiSpark が適切に通信できなかった場合は、ファイアウォールの構成を確認してください。ファイアウォール ルールを調整するか、必要に応じて無効にすることができます。
TiSpark を既存の Spark クラスターにデプロイ
既存の Spark クラスターで TiSpark を実行する場合、クラスターを再起動する必要はありません。 Spark の--jarsパラメータを使用して、TiSpark を依存関係として導入できます。
spark-shell --jars $TISPARK_FOLDER/tispark-${name_with_version}.jar
Spark クラスターなしで TiSpark をデプロイ
Spark クラスターがない場合は、スタンドアロン モードを使用することをお勧めします。詳細については、 Spark スタンドアロンを参照してください。問題が発生した場合は、 スパーク公式サイトを参照してください。 GitHub の問題を提出するへようこそ。
Spark Shell と Spark SQL を使用する
上記のように TiSpark クラスターを正常に開始したと仮定します。以下では、 tpchデータベース内のlineitemという名前のテーブルで OLAP 分析に Spark SQL を使用する方法について説明します。
192.168.1.101で利用可能な TiDBサーバー経由でテスト データを生成するには:
tiup bench tpch prepare --host 192.168.1.101 --user root
PD ノードが192.168.1.100 、ポート2379にあると仮定して、次のコマンドを$SPARK_HOME/conf/spark-defaults.confに追加します。
spark.tispark.pd.addresses 192.168.1.100:2379
spark.sql.extensions org.apache.spark.sql.TiExtensions
Spark シェルを開始します。
./bin/spark-shell
次に、ネイティブ Apache Spark の場合と同様に、Spark シェルで次のコマンドを入力します。
spark.sql("use tpch")
spark.sql("select count(*) from lineitem").show
結果は次のとおりです。
+-------------+
| Count (1) |
+-------------+
| 2000 |
+-------------+
Spark Shell の他に、Spark SQL も利用できます。 Spark SQL を使用するには、次を実行します。
./bin/spark-sql
同じクエリを実行できます。
use tpch;
select count(*) from lineitem;
結果は次のとおりです。
2000
Time taken: 0.673 seconds, Fetched 1 row(s)
ThriftServer で JDBC サポートを使用する
JDBC サポートなしで Spark Shell または Spark SQL を使用できます。ただし、beeline などのツールには JDBC サポートが必要です。 JDBC サポートは、Thriftサーバーによって提供されます。 Spark の Thriftサーバーを使用するには、次を実行します。
./sbin/start-thriftserver.sh
JDBC を Thriftサーバーに接続するには、beeline などの JDBC 対応ツールを使用できます。
たとえば、ビーラインで使用するには:
./bin/beeline jdbc:hive2://localhost:10000
次のメッセージが表示されれば、ビーラインは正常に有効化されています。
Beeline version 1.2.2 by Apache Hive
次に、クエリ コマンドを実行できます。
1: jdbc:hive2://localhost:10000> use testdb;
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (0.013 seconds)
select count(*) from account;
+-----------+--+
| count(1) |
+-----------+--+
| 1000000 |
+-----------+--+
1 row selected (1.97 seconds)
TiSpark を Hive と共に使用する
TiSpark は Hive と一緒に使用できます。 Spark を開始する前に、環境変数HADOOP_CONF_DIRを Hadoop 構成フォルダーに設定し、 hive-site.xmlをspark/confフォルダーにコピーする必要があります。
val tisparkDF = spark.sql("select * from tispark_table").toDF
tisparkDF.write.saveAsTable("hive_table") // save table to hive
spark.sql("select * from hive_table a, tispark_table b where a.col1 = b.col1").show // join table across Hive and Tispark
TiSpark を使用して DataFrame を TiDB にバッチ書き込みする
v2.3 以降、TiSpark は TiDB クラスターへの DataFrame のバッチ書き込みをネイティブでサポートしています。この書き込みモードは、TiKV の 2 フェーズ コミット プロトコルによって実装されます。
Spark + JDBC による書き込みと比較して、TiSpark バッチ書き込みには次の利点があります。
| 比較する側面 | TiSpark バッチ書き込み | Spark + JDBC 書き込み |
|---|---|---|
| 原子性 | DataFrame はすべて正常に書き込まれるか、すべて書き込みに失敗します。 | 書き込み処理中に Spark タスクが失敗して終了した場合、データの一部が正常に書き込まれる可能性があります。 |
| 隔離 | 書き込みプロセス中、書き込まれるデータは他のトランザクションから見えません。 | 書き込みプロセス中に、正常に書き込まれたデータの一部が他のトランザクションから見えるようになります。 |
| エラー回復 | バッチ書き込みが失敗した場合は、Spark を再実行するだけで済みます。 | 冪等性を実現するには、アプリケーションが必要です。たとえば、バッチ書き込みが失敗した場合、正常に書き込まれたデータの一部をクリーンアップして、Spark を再実行する必要があります。タスクのリトライによるデータの重複を防ぐために、 spark.task.maxFailures=1を設定する必要があります。 |
| スピード | データは TiKV に直接書き込まれるため、高速です。 | データは TiDB を介して TiKV に書き込まれるため、速度に影響します。 |
次の例は、scala API 経由で TiSpark を使用してデータをバッチ書き込みする方法を示しています。
// select data to write
val df = spark.sql("select * from tpch.ORDERS")
// write data to tidb
df.write.
format("tidb").
option("tidb.addr", "127.0.0.1").
option("tidb.port", "4000").
option("tidb.user", "root").
option("tidb.password", "").
option("database", "tpch").
option("table", "target_orders").
mode("append").
save()
書き込むデータ量が多く、書き込み時間が 10 分を超える場合は、GC 時間が書き込み時間より長くなるようにする必要があります。
UPDATE mysql.tidb SET VARIABLE_VALUE="6h" WHERE VARIABLE_NAME="tikv_gc_life_time";
詳細はこのドキュメントを参照してください。
JDBC を使用して Spark Dataframe を TiDB にロードする
TiSpark を使用して DataFrame を TiDB クラスターにバッチ書き込みするだけでなく、Spark のネイティブ JDBC サポートをデータ書き込みに使用することもできます。
import org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions
val customer = spark.sql("select * from customer limit 100000")
// You might repartition the source to make it balance across nodes
// and increase the concurrency.
val df = customer.repartition(32)
df.write
.mode(saveMode = "append")
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
// Replace the host and port with that of your own and be sure to use the rewrite batch
.option("url", "jdbc:mysql://127.0.0.1:4000/test?rewriteBatchedStatements=true")
.option("useSSL", "false")
// As tested, 150 is good practice
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE, 150)
.option("dbtable", s"cust_test_select") // database name and table name here
.option("isolationLevel", "NONE") // recommended to set isolationLevel to NONE if you have a large DF to load.
.option("user", "root") // TiDB user here
.save()
TiDB OOM につながる可能性のある大規模な単一トランザクションを回避するために、 isolationLevelからNONEに設定することをお勧めします。
ノート:
JDBC を使用する場合、デフォルト値の
isolationLevelはREAD_UNCOMMITTEDであり、サポートされていない分離レベル トランザクションのエラーが発生します。isolationLevel~NONEの値を設定することをお勧めします。
統計情報
TiSpark は、次の項目について TiDB 統計情報を使用します。
- 推定コストが最も低いクエリ プランでどのインデックスを使用するかを決定します。
- 効率的なブロードキャスト参加を可能にする小さなテーブル ブロードキャスト。
TiSpark で統計情報を使用する場合は、まず、関連するテーブルが既に分析されていることを確認する必要があります。 テーブルを分析する方法についてもっと読む。
TiSpark 2.0 から、統計情報はデフォルトで自動ロードされます。
安全
TiSpark v2.5.0 以降のバージョンを使用している場合は、TiDB を使用して TiSpark ユーザーを認証および承認できます。
認証および承認機能は、デフォルトでは無効になっています。これを有効にするには、次の構成を Spark 構成ファイルに追加しますspark-defaults.conf 。
// Enable authentication and authorization
spark.sql.auth.enable true
// Configure TiDB information
spark.sql.tidb.addr $your_tidb_server_address
spark.sql.tidb.port $your_tidb_server_port
spark.sql.tidb.user $your_tidb_server_user
spark.sql.tidb.password $your_tidb_server_password
詳細については、 TiDBサーバーによる承認と認証を参照してください。
ノート:
認証および承認機能を有効にすると、TiSpark Spark SQL は TiDB のみをデータ ソースとして使用できるため、他のデータ ソース (Hive など) に切り替えると、テーブルが非表示になります。
TiSpark FAQ
Q: 既存の Spark / Hadoop クラスターとの共有リソースとは対照的に、独立したデプロイの長所と短所は何ですか?
A: 別のデプロイを行わなくても既存の Spark クラスターを使用できますが、既存のクラスターがビジー状態の場合、TiSpark は目的の速度を達成できません。
Q: Spark と TiKV を混在させることはできますか?
A: TiDB と TiKV が過負荷になり、重要なオンライン タスクを実行する場合は、TiSpark を個別に展開することを検討してください。また、OLTP のネットワーク リソースが危険にさらされたり、オンライン ビジネスに影響を与えたりしないように、別の NIC の使用を検討する必要があります。オンライン ビジネス要件が高くない場合、または負荷が十分に大きくない場合は、TiSpark と TiKV 展開を混在させることを検討できます。
Q: TiSpark を使用して SQL ステートメントを実行したときにwarning: WARN ObjectStore:568 - Failed to get databaseが返された場合、どうすればよいですか?
A: この警告は無視してかまいません。これは、Spark がそのカタログに存在しない 2 つのデータベース ( defaultおよびglobal_temp ) をロードしようとするために発生します。この警告をミュートするには、 tispark/confのlog4jファイルにlog4j.logger.org.apache.hadoop.hive.metastore.ObjectStore=ERRORを追加してlog4jを変更します。パラメータは、Spark の下のconfigのlog4jファイルに追加できます。接尾辞がtemplateの場合、 mvコマンドを使用してpropertiesに変更できます。
Q: TiSpark を使用して SQL ステートメントを実行したときにjava.sql.BatchUpdateException: Data Truncatedが返された場合、どうすればよいですか?
A: このエラーは、書き込まれたデータの長さがデータベースで定義されているデータ型の長さを超えているために発生します。フィールドの長さを確認し、それに応じて調整できます。
Q: TiSpark はデフォルトで Hive メタデータを読み取りますか?
A: デフォルトでは、TiSpark は hive-site の Hive メタデータを読み取って Hive データベースを検索します。検索タスクが失敗した場合、代わりに TiDB メタデータを読み取って TiDB データベースを検索します。
このデフォルトの動作が必要ない場合は、hive-site で Hive メタデータを構成しないでください。
Q: TiSpark が Spark タスクを実行しているときにError: java.io.InvalidClassException: com.pingcap.tikv.region.TiRegion; local class incompatible: stream classdesc serialVersionUID ...が返された場合、どうすればよいですか?
A: エラー メッセージにはserialVersionUIDの競合が表示されます。これは、異なるバージョンのclassとTiRegionを使用したために発生します。 TiRegionは TiSpark にのみ存在するため、TiSpark パッケージの複数のバージョンが使用される場合があります。このエラーを修正するには、TiSpark 依存関係のバージョンがクラスター内のすべてのノード間で一貫していることを確認する必要があります。