TiKVの概要
TiKV は分散型のトランザクション キー値データベースであり、 ACID準拠のトランザクション API を提供します。 RocksDB に格納されたRaftコンセンサスアルゴリズムおよびコンセンサス状態の実装により、TiKV は複数のレプリカ間のデータの一貫性と高可用性を保証します。 TiDB 分散データベースのストレージレイヤーとして、TiKV は読み取りおよび書き込みサービスを提供し、アプリケーションから書き込まれたデータを永続化します。また、TiDB クラスターの統計データも格納します。
アーキテクチャの概要
TiKV は、Google Spanner の設計に基づいて、マルチラフト グループ レプリカ メカニズムを実装します。リージョンは、キーと値のデータ移動の基本単位であり、ストア内のデータ範囲を参照します。各リージョンは複数のノードに複製されます。これらの複数のレプリカがRaftグループを形成します。リージョンのレプリカはピアと呼ばれます。通常、 リージョンには 3 つのピアがあります。それらの 1 つはリーダーであり、読み取りおよび書き込みサービスを提供します。 PD コンポーネントは、すべてのリージョンのバランスを自動的に調整して、TiKV クラスター内のすべてのノード間で読み取りと書き込みのスループットのバランスがとれるようにします。 PD と慎重に設計されたRaftグループにより、TiKV は水平方向のスケーラビリティに優れ、100 TB を超えるデータを格納するように簡単に拡張できます。
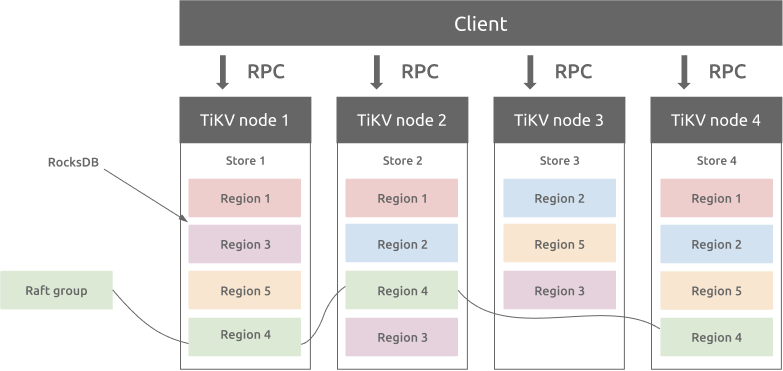
リージョンと RocksDB
各ストア内には RocksDB データベースがあり、データはローカル ディスクに保存されます。すべてのリージョンデータは、各ストアの同じ RocksDB インスタンスに保存されます。 Raftコンセンサス アルゴリズムに使用されるすべてのログは、各 Store の別の RocksDB インスタンスに保存されます。これは、シーケンシャル I/O のパフォーマンスがランダム I/O よりも優れているためです。 raft ログとリージョンデータを格納するさまざまな RocksDB インスタンスを使用して、TiKV は raft ログと TiKV リージョンのすべてのデータ書き込み操作を 1 つの I/O 操作に結合して、パフォーマンスを向上させます。
リージョンとRaftのコンセンサスアルゴリズム
リージョンのレプリカ間のデータの一貫性は、 Raftコンセンサス アルゴリズムによって保証されます。 リージョンのリーダーのみが書き込みサービスを提供でき、データがリージョンの大部分のレプリカに書き込まれた場合にのみ、書き込み操作が成功します。
リージョンのサイズがしきい値 (デフォルトでは 144 MB) を超えると、TiKV はリージョンを 2 つ以上のリージョンに分割します。この操作により、クラスター内のすべてのリージョンのサイズがほぼ同じになることが保証され、PD コンポーネントが TiKV クラスター内のノード間でリージョンのバランスを取るのに役立ちます。 リージョンのサイズがしきい値よりも小さい場合、TiKV は 2 つの小さい隣接する Region を 1 つのリージョンにマージします。
PD がレプリカを 1 つの TiKV ノードから別のノードに移動する場合、まずターゲット ノードに学習者レプリカを追加します。学習者レプリカのデータがリーダー レプリカのデータとほぼ同じになった後、PD はそれをフォロワー レプリカに変更し、削除します。ソース ノードのフォロワー レプリカ。
あるノードから別のノードへのリーダー レプリカの移動には、同様のメカニズムがあります。違いは、ラーナー レプリカがフォロワー レプリカになった後、フォロワー レプリカが自身をリーダーとして選択するための選択を積極的に提案する「リーダー転送」操作があることです。最後に、新しいリーダーはソース ノードの古いリーダー レプリカを削除します。
分散トランザクション
TiKV は分散トランザクションをサポートしています。ユーザー (または TiDB) は、同じリージョンに属しているかどうかを気にすることなく、複数のキーと値のペアを書き込むことができます。 TiKV は 2 フェーズ コミットを使用してACID制約を実現します。詳細はTiDB 楽観的トランザクション モデルを参照してください。
TiKV コプロセッサー
TiDB は、一部のデータ計算ロジックを TiKV Coprocessor にプッシュします。 TiKV Coprocessor は、各リージョンの計算を処理します。 TiKV Coprocessor に送信される各リクエストには、1 つのリージョンのデータのみが含まれます。