RocksDB の概要
RocksDBは、キー値ストアと読み取り/書き込み関数を提供する LSM ツリー ストレージ エンジンです。これは Facebook によって開発され、LevelDB に基づいています。ユーザーによって書き込まれたキーと値のペアは、最初に Write Ahead Log (WAL) に挿入され、次にメモリ内の SkipList (MemTable と呼ばれるデータ構造) に書き込まれます。 LSM ツリー エンジンは、ランダムな変更 (挿入) を WAL ファイルへの順次書き込みに変換するため、B ツリー エンジンよりも優れた書き込みスループットを提供します。
メモリ内のデータが一定のサイズに達すると、RocksDB はコンテンツをディスク内のソート済み文字列テーブル (SST) ファイルにフラッシュします。 SST ファイルは複数のレベルで編成されています (デフォルトは最大 6 レベルです)。レベルの合計サイズがしきい値に達すると、RocksDB は SST ファイルの一部を選択し、それらを次のレベルにマージします。後続の各レベルは前のレベルの 10 倍であるため、データの 90% は最後のレイヤーに格納されます。
RocksDB では、ユーザーは複数のカラムファミリー (CF) を作成できます。 CF には独自の SkipList ファイルと SST ファイルがあり、同じ WAL ファイルを共有します。このように、異なる CF は、アプリケーションの特性に応じて異なる設定を持つことができます。同時に WAL への書き込み数を増やすことはありません。
TiKVアーキテクチャ
TiKV のアーキテクチャを以下に示します。
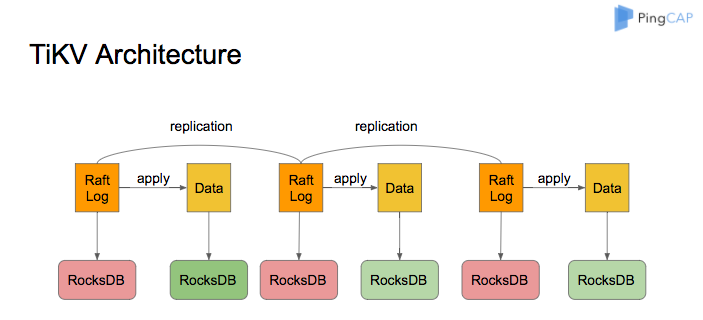
TiKV のストレージ エンジンとして、 Raftログとユーザー データを保存するために RocksDB が使用されます。 TiKV ノード内のすべてのデータは、2 つの RocksDB インスタンスを共有します。 1 つはRaftログ (多くの場合 raftdb と呼ばれます) 用で、もう 1 つはユーザー データと MVCC メタデータ (多くの場合 kvdb と呼ばれます) 用です。 kvdb には、raft、lock、default、および write の 4 つの CF があります。
- raft CF: 各リージョンのメタデータを格納します。占有するスペースはごくわずかで、ユーザーは気にする必要はありません。
- lock CF: 悲観的トランザクションの悲観的ロックと、分散トランザクションの事前書き込みロックを格納します。トランザクションがコミットされた後、ロック CF 内の対応するデータはすぐに削除されます。したがって、通常、ロック CF 内のデータのサイズは非常に小さくなります (1 GB 未満)。ロック CF 内のデータが大幅に増加する場合は、多数のトランザクションがコミットされるのを待っており、システムにバグまたは障害が発生していることを意味します。
- write CF: ユーザーの実際の書き込みデータと MVCC メタデータ (データが属するトランザクションの開始タイムスタンプとコミット タイムスタンプ) を保存します。ユーザーが 1 行のデータを書き込むと、データ長が 255 バイト未満の場合、データは書き込み CF に格納されます。それ以外の場合は、デフォルトの CF に保管されます。 TiDB では、非一意インデックスに格納された値は空であり、一意インデックスに格納された値は主キー インデックスであるため、セカンダリ インデックスは書き込み CF のスペースのみを占有します。
- デフォルト CF: 255 バイトを超えるデータを格納します。
RocksDB のメモリ使用量
読み取りパフォーマンスを向上させ、ディスクへの読み取り操作を減らすために、RocksDB はディスクに保存されているファイルを特定のサイズ (デフォルトは 64 KB) に基づいてブロックに分割します。ブロックを読み取るとき、データがメモリ内の BlockCache に既に存在するかどうかを最初に確認します。 true の場合、ディスクにアクセスせずにメモリから直接データを読み取ることができます。
BlockCache は、LRU アルゴリズムに従って、使用頻度の最も低いデータを破棄します。デフォルトでは、TiKV はシステム メモリの 45% を BlockCache に割り当てます。ユーザーは、自分でstorage.block-cache.capacity構成を適切な値に変更することもできます。ただし、合計システム メモリの 60% を超えることはお勧めしません。
RocksDB に書き込まれたデータは、最初に MemTable に書き込まれます。 MemTable のサイズが 128 MB を超えると、新しい MemTable に切り替わります。 TiKV には 2 つの RocksDB インスタンスがあり、合計 4 つの CF があります。各 CF の 1 つの MemTable のサイズ制限は 128 MB です。同時に存在できる MemTable は最大 5 つです。それ以外の場合、フォアグラウンド書き込みはブロックされます。この部分が占有するメモリは最大で 2.5 GB (4 x 5 x 128 MB) です。メモリの消費が少ないため、この制限を変更することはお勧めしません。
RocksDB スペース使用量
- マルチバージョン: RocksDB は LSM ツリー構造のキー値ストレージ エンジンであるため、MemTable のデータは最初に L0 にフラッシュされます。ファイルは生成順に並べられているため、L0 での海面水温の範囲が重複する場合があります。その結果、同じキーが L0 に複数のバージョンを持つ場合があります。ファイルが L0 から L1 にマージされると、特定のサイズ (デフォルトは 8 MB) で複数のファイルに分割されます。同じレベルの各ファイルのキー範囲は互いに重複しないため、L1 以降のレベルでは各キーに対して 1 つのバージョンのみが存在します。
- スペースの増幅: 各レベルのファイルの合計サイズは、前のレベルの x (デフォルトは 10) 倍であるため、データの 90% が最後のレベルに保存されます。これは、RocksDB の空間増幅が 1.11 を超えないことも意味します (L0 はデータが少なく、無視できます)。
- TiKV の空間増幅: TiKV には独自の MVCC 戦略があります。ユーザーがキーを書き込むと、RocksDB に書き込まれる実際のデータはキー + commit_ts になります。つまり、更新と削除によって新しいキーも RocksDB に書き込まれます。 TiKV は古いバージョンのデータを一定間隔で (RocksDB の削除インターフェイスを介して) 削除するため、ユーザーが TiKV に保存したデータの実際の容量は、過去 10 分間に書き込まれたデータに 1.11 を加えたものに拡大されていると見なすことができます。 (TiKV が古いデータを迅速にクリーンアップすると仮定します)。
RocksDB バックグラウンド スレッドとコンパクション
RocksDB では、MemTable の SST ファイルへの変換や、さまざまなレベルでの SST ファイルのマージなどの操作は、バックグラウンド スレッド プールで実行されます。バックグラウンド スレッド プールのデフォルト サイズは 8 です。マシンの CPU 数が 8 以下の場合、バックグラウンド スレッド プールのデフォルト サイズは CPU 数から 1 を引いた値になります。
通常、ユーザーはこの構成を変更する必要はありません。ユーザーがマシンに複数の TiKV インスタンスをデプロイする場合、またはマシンの読み取り負荷が比較的高く、書き込み負荷が低い場合は、必要に応じてrocksdb/max-background-jobs ~ 3 または 4 を調整できます。
書き込みストール
RocksDB の L0 は、他のレベルとは異なります。 L0 の SST は、世代順に並べられています。 SST 間のキー範囲はオーバーラップできます。したがって、L0 内の各 SST は、クエリが実行されるときに順番にクエリされる必要があります。クエリのパフォーマンスに影響を与えないようにするために、L0 にファイルが多すぎると WriteStall がトリガーされて書き込みがブロックされます。
書き込み遅延が急激に増加した場合は、まず、Grafana RocksDB KV パネルでWriteStall Reasonメトリックを確認できます。 L0 ファイルが多すぎるために発生した WriteStall である場合は、次の構成を 64 に調整できます。
rocksdb.defaultcf.level0-slowdown-writes-trigger
rocksdb.writecf.level0-slowdown-writes-trigger
rocksdb.lockcf.level0-slowdown-writes-trigger
rocksdb.defaultcf.level0-stop-writes-trigger
rocksdb.writecf.level0-stop-writes-trigger
rocksdb.lockcf.level0-stop-writes-trigger