マルチテーブル結合クエリ
多くのシナリオでは、1 つのクエリを使用して複数のテーブルからデータを取得する必要があります。 JOINステートメントを使用して、2 つ以上のテーブルのデータを組み合わせることができます。
結合の種類
このセクションでは、結合の種類について詳しく説明します。
内部結合
内部結合の結合結果は、結合条件に一致する行のみを返します。
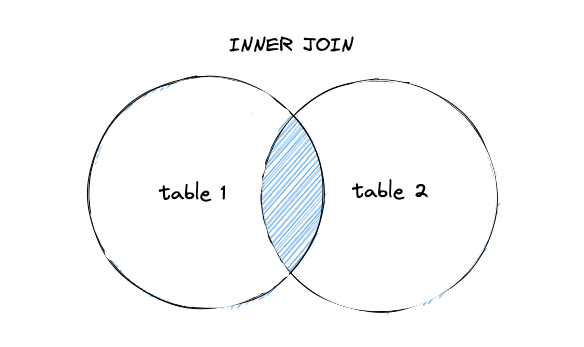
たとえば、最も多作な著者を知りたい場合は、 authorsという名前の author テーブルとbook_authorsという名前の書籍の author テーブルを結合する必要があります。
- SQL
- Java
次の SQL ステートメントでは、キーワードJOINを使用して、左のテーブルauthorsと右のテーブルbook_authorsの行を結合条件a.id = ba.author_idで内部結合として結合することを宣言します。結果セットには、結合条件を満たす行のみが含まれます。著者が本を書いていない場合、テーブルauthorsのレコードは結合条件を満たさないため、結果セットには表示されません。
SELECT ANY_VALUE(a.id) AS author_id, ANY_VALUE(a.name) AS author_name, COUNT(ba.book_id) AS books
FROM authors a
JOIN book_authors ba ON a.id = ba.author_id
GROUP BY ba.author_id
ORDER BY books DESC
LIMIT 10;
クエリ結果は次のとおりです。
+------------+----------------+-------+
| author_id | author_name | books |
+------------+----------------+-------+
| 431192671 | Emilie Cassin | 7 |
| 865305676 | Nola Howell | 7 |
| 572207928 | Lamar Koch | 6 |
| 3894029860 | Elijah Howe | 6 |
| 1150614082 | Cristal Stehr | 6 |
| 4158341032 | Roslyn Rippin | 6 |
| 2430691560 | Francisca Hahn | 6 |
| 3346415350 | Leta Weimann | 6 |
| 1395124973 | Albin Cole | 6 |
| 2768150724 | Caleb Wyman | 6 |
+------------+----------------+-------+
10 rows in set (0.01 sec)
public List<Author> getTop10AuthorsOrderByBooks() throws SQLException {
List<Author> authors = new ArrayList<>();
try (Connection conn = ds.getConnection()) {
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("""
SELECT ANY_VALUE(a.id) AS author_id, ANY_VALUE(a.name) AS author_name, COUNT(ba.book_id) AS books
FROM authors a
JOIN book_authors ba ON a.id = ba.author_id
GROUP BY ba.author_id
ORDER BY books DESC
LIMIT 10;
""");
while (rs.next()) {
Author author = new Author();
author.setId(rs.getLong("author_id"));
author.setName(rs.getString("author_name"));
author.setBooks(rs.getInt("books"));
authors.add(author);
}
}
return authors;
}
左外部結合
左外部結合は、結合条件に一致する、左側のテーブルのすべての行と右側のテーブルの値を返します。右側のテーブルに一致する行がない場合は、 NULLで埋められます。
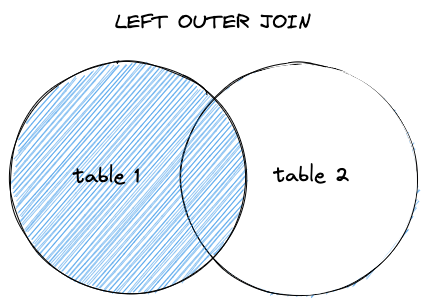
場合によっては、複数のテーブルを使用してデータ クエリを完了したいが、結合条件が満たされていないためにデータ セットが小さくなりすぎないようにしたい場合があります。
たとえば、Bookshop アプリのホームページで、平均評価の新しい本のリストを表示したいとします。この場合、新しい本はまだ誰にも評価されていない可能性があります。内部結合を使用すると、これらの評価されていない書籍の情報が除外されますが、これは予期したことではありません。
- SQL
- Java
次の SQL ステートメントでは、 LEFT JOINキーワードを使用して、左側のテーブルbooksが右側のテーブルratingsに左外部結合で結合されることを宣言し、テーブルbooksのすべての行が確実に返されるようにします。
SELECT b.id AS book_id, ANY_VALUE(b.title) AS book_title, AVG(r.score) AS average_score
FROM books b
LEFT JOIN ratings r ON b.id = r.book_id
GROUP BY b.id
ORDER BY b.published_at DESC
LIMIT 10;
クエリ結果は次のとおりです。
+------------+---------------------------------+---------------+
| book_id | book_title | average_score |
+------------+---------------------------------+---------------+
| 3438991610 | The Documentary of lion | 2.7619 |
| 3897175886 | Torey Kuhn | 3.0000 |
| 1256171496 | Elmo Vandervort | 2.5500 |
| 1036915727 | The Story of Munchkin | 2.0000 |
| 270254583 | Tate Kovacek | 2.5000 |
| 1280950719 | Carson Damore | 3.2105 |
| 1098041838 | The Documentary of grasshopper | 2.8462 |
| 1476566306 | The Adventures of Vince Sanford | 2.3529 |
| 4036300890 | The Documentary of turtle | 2.4545 |
| 1299849448 | Antwan Olson | 3.0000 |
+------------+---------------------------------+---------------+
10 rows in set (0.30 sec)
最近出版された本はすでに多くの評価を得ているようです。上記の方法を確認するために、次の SQL ステートメントを使用してThe Documentary of lionという書籍のすべての評価を削除してみましょう。
DELETE FROM ratings WHERE book_id = 3438991610;
再度クエリします。 The Documentary of lionという本はまだ結果セットに表示されていますが、右側のテーブルratingsのscoreから計算されたaverage_score列はNULLで埋められています。
+------------+---------------------------------+---------------+
| book_id | book_title | average_score |
+------------+---------------------------------+---------------+
| 3438991610 | The Documentary of lion | NULL |
| 3897175886 | Torey Kuhn | 3.0000 |
| 1256171496 | Elmo Vandervort | 2.5500 |
| 1036915727 | The Story of Munchkin | 2.0000 |
| 270254583 | Tate Kovacek | 2.5000 |
| 1280950719 | Carson Damore | 3.2105 |
| 1098041838 | The Documentary of grasshopper | 2.8462 |
| 1476566306 | The Adventures of Vince Sanford | 2.3529 |
| 4036300890 | The Documentary of turtle | 2.4545 |
| 1299849448 | Antwan Olson | 3.0000 |
+------------+---------------------------------+---------------+
10 rows in set (0.30 sec)
INNER JOINを使用するとどうなりますか?試してみるかどうかはあなた次第です。
public List<Book> getLatestBooksWithAverageScore() throws SQLException {
List<Book> books = new ArrayList<>();
try (Connection conn = ds.getConnection()) {
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("""
SELECT b.id AS book_id, ANY_VALUE(b.title) AS book_title, AVG(r.score) AS average_score
FROM books b
LEFT JOIN ratings r ON b.id = r.book_id
GROUP BY b.id
ORDER BY b.published_at DESC
LIMIT 10;
""");
while (rs.next()) {
Book book = new Book();
book.setId(rs.getLong("book_id"));
book.setTitle(rs.getString("book_title"));
book.setAverageScore(rs.getFloat("average_score"));
books.add(book);
}
}
return books;
}
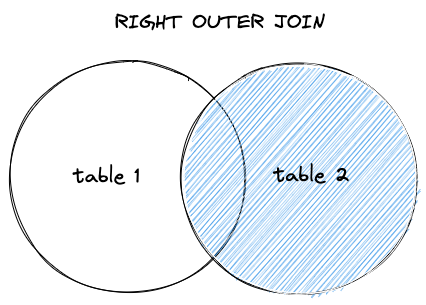
右外部結合
右外部結合は、右側のテーブルのすべてのレコードと、結合条件に一致する左側のテーブルの値を返します。一致する値がない場合は、 NULLで埋められます。
クロスジョイン
結合条件が一定の場合、2 つのテーブル間の内部結合は交差結合と呼ばれます。クロス結合は、左側のテーブルのすべてのレコードを右側のテーブルのすべてのレコードに結合します。左側のテーブルのレコード数がmで、右側のテーブルのレコード数がnの場合、結果セットにはm \* nのレコードが生成されます。
左セミジョイン
TiDB は、SQL 構文レベルでLEFT SEMI JOIN table_nameをサポートしていません。ただし、実行計画レベルでは、 サブクエリ関連の最適化は、書き換えられた同等の JOIN クエリのデフォルトの結合方法としてsemi joinを使用します。
暗黙の結合
結合を明示的に宣言するJOINステートメントが SQL 標準に追加される前は、SQL ステートメントでFROM t1, t2節を使用して 2 つ以上のテーブルを結合し、 WHERE t1.id = t2.id節を使用して結合の条件を指定することができました。内部結合を使用してテーブルを結合する暗黙的な結合として理解できます。
関連するアルゴリズムに参加する
TiDB は、次の一般的なテーブル結合アルゴリズムをサポートしています。
オプティマイザーは、結合されたテーブルのデータ量などの要因に基づいて、実行する適切な結合アルゴリズムを選択します。 EXPLAINステートメントを使用して、クエリが Join に使用するアルゴリズムを確認できます。
TiDB のオプティマイザが最適な結合アルゴリズムに従って実行されない場合は、 オプティマイザーのヒントを使用して、TiDB がより適切な結合アルゴリズムを使用するように強制できます。
たとえば、上記の左結合クエリの例が、オプティマイザによって選択されないハッシュ結合アルゴリズムを使用して高速に実行されると仮定すると、 SELECTキーワードの後にヒント/*+ HASH_JOIN(b, r) */を追加できます。テーブルにエイリアスがある場合は、ヒントでエイリアスを使用することに注意してください。
EXPLAIN SELECT /*+ HASH_JOIN(b, r) */ b.id AS book_id, ANY_VALUE(b.title) AS book_title, AVG(r.score) AS average_score
FROM books b
LEFT JOIN ratings r ON b.id = r.book_id
GROUP BY b.id
ORDER BY b.published_at DESC
LIMIT 10;
結合アルゴリズムに関するヒント:
- MERGE_JOIN(t1_name [, tl_name ...])
- INL_JOIN(t1_name [, tl_name ...])
- INL_HASH_JOIN(t1_name [, tl_name ...])
- HASH_JOIN(t1_name [, tl_name ...])
結合注文
実際のビジネス シナリオでは、複数のテーブルの結合ステートメントは非常に一般的です。ジョインの実行効率は、ジョイン内の各テーブルの順序に関係しています。 TiDB は結合したテーブルの再配置 Reorder アルゴリズムを使用して、複数のテーブルを結合する順序を決定します。
オプティマイザによって選択された結合順序が期待どおりに最適でない場合は、 STRAIGHT_JOINを使用して、 FROM節で使用されるテーブルの順序でクエリを結合するように TiDB を強制できます。
EXPLAIN SELECT *
FROM authors a STRAIGHT_JOIN book_authors ba STRAIGHT_JOIN books b
WHERE b.id = ba.book_id AND ba.author_id = a.id;
この結合したテーブルの再配置アルゴリズムの実装の詳細と制限事項の詳細については、 結合したテーブルの再配置 Algorithm の概要を参照してください。