書店のサンプル アプリケーション
Bookshop は、さまざまなカテゴリの本を購入し、読んだ本を評価できる仮想オンライン書店アプリケーションです。
アプリケーション開発者ガイドをよりスムーズに読むために、Bookshop アプリケーションのテーブル構造とデータに基づいた SQL ステートメントの例を示します。このドキュメントでは、テーブル構造とデータのインポート方法、およびテーブル構造の定義に焦点を当てています。
テーブル構造とデータをインポートする
Bookshop のテーブル構造とデータをインポートできますTiUP経由またはTiDB Cloudのインポート機能経由 。
方法 1: tiup demo経由
TiDB クラスターがTiUPを使用してデプロイされている場合、または TiDBサーバーに接続できる場合は、次のコマンドを実行して、Bookshop アプリケーションのサンプル データをすばやく生成してインポートできます。
tiup demo bookshop prepare
デフォルトでは、このコマンドはアプリケーションがアドレス127.0.0.1のポート4000に接続できるようにし、パスワードなしでrootユーザーとしてログインできるようにし、 bookshopという名前のデータベースにテーブル構造を作成します。
接続情報の構成
次の表に、接続パラメータを示します。環境に合わせてデフォルト設定を変更できます。
| パラメータ | 略語 | デフォルト値 | 説明 |
|---|---|---|---|
--password | -p | なし | データベース ユーザーのパスワード |
--host | -H | 127.0.0.1 | データベースアドレス |
--port | -P | 4000 | データベース ポート |
--db | -D | bookshop | データベース名 |
--user | -U | root | データベース ユーザー |
たとえば、 TiDB Cloud上のデータベースに接続する場合は、次のように接続情報を指定できます。
tiup demo bookshop prepare -U root -H tidb.xxx.yyy.ap-northeast-1.prod.aws.tidbcloud.com -P 4000 -p
データ量を設定する
次のパラメーターを構成することにより、各データベース テーブルで生成されるデータの量を指定できます。
| パラメータ | デフォルト値 | 説明 |
|---|---|---|
--users | 10000 | usersテーブルに生成するデータの行数 |
--authors | 20000 | authorsテーブルに生成する行数 |
--books | 20000 | booksテーブルに生成するデータの行数 |
--orders | 300000 | ordersテーブルに生成するデータの行数 |
--ratings | 300000 | ratingsテーブルに生成するデータの行数 |
たとえば、次のコマンドを実行して生成します。
--usersパラメータによる 200,000 行のユーザー情報--booksパラメータによる 500,000 行の書籍情報--authorsパラメータによる 100,000 行の著者情報--ratingsパラメータによる 1,000,000 行の評価レコード--ordersパラメータによる 1,000,000 行の注文レコード
tiup demo bookshop prepare --users=200000 --books=500000 --authors=100000 --ratings=1000000 --orders=1000000 --drop-tables
--drop-tablesパラメータを使用して、元のテーブル構造を削除できます。パラメーターの詳細については、 tiup demo bookshop --helpコマンドを実行してください。
方法 2: TiDB Cloudインポート経由
TiDB Cloudのデータベースの詳細ページで、[インポート] ボタンをクリックして、[データのインポート タスク] ページに入ります。このページで、次の手順を実行して Bookshop サンプル データを AWS S3 からTiDB Cloudにインポートします。
次のバケット URLとRole-ARNを対応する入力ボックスにコピーします。
バケット URL :
```
s3://developer.pingcap.com/bookshop/
```
**Role-ARN** :
```
arn:aws:iam::494090988690:role/s3-tidb-cloud-developer-access
```
この例では、次のデータが事前に生成されます。
- 200,000 行のユーザー情報
- 500,000 行の書籍情報
- 100,000 行の著者情報
- 1,000,000 行の評価レコード
- 1,000,000 行の注文レコード
Bucket リージョンにUS West (Oregon)を選択します。
データ形式にTiDB Dumplingを選択します。
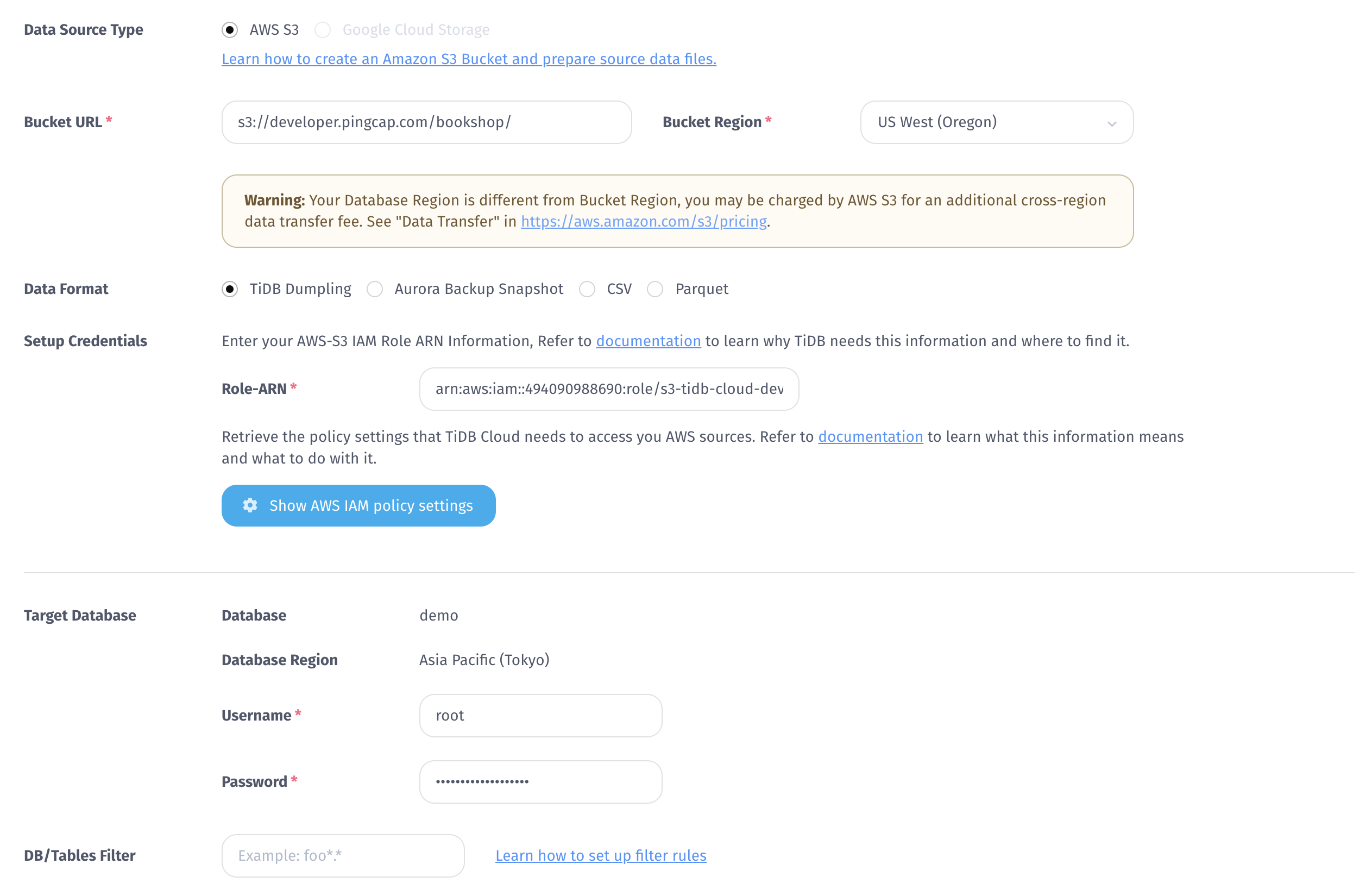
データベースのログイン情報を入力します。
[インポート] ボタンをクリックして、インポートを確認します。
TiDB Cloudがインポートを完了するまで待ちます。
インポート プロセス中に次のエラー メッセージが表示された場合は、
DROP DATABASE bookshop;コマンドを実行して、以前に作成したサンプル データベースをクリアしてから、データを再度インポートします。テーブル [
bookshop.authorsbookshopbook_authorsbookshopbooksbookshopordersbookshopratingsbookshopusers] は空ではありません。
TiDB Cloudの詳細については、 TiDB Cloudのドキュメントを参照してください。
データのインポート ステータスをビューする
インポートが完了したら、次の SQL ステートメントを実行して、各テーブルのデータ ボリューム情報を表示できます。
SELECT
CONCAT(table_schema,'.',table_name) AS 'Table Name',
table_rows AS 'Number of Rows',
CONCAT(ROUND(data_length/(1024*1024*1024),4),'G') AS 'Data Size',
CONCAT(ROUND(index_length/(1024*1024*1024),4),'G') AS 'Index Size',
CONCAT(ROUND((data_length+index_length)/(1024*1024*1024),4),'G') AS 'Total'
FROM
information_schema.TABLES
WHERE table_schema LIKE 'bookshop';
結果は次のとおりです。
+-----------------------+----------------+-----------+------------+---------+
| Table Name | Number of Rows | Data Size | Index Size | Total |
+-----------------------+----------------+-----------+------------+---------+
| bookshop.orders | 1000000 | 0.0373G | 0.0075G | 0.0447G |
| bookshop.book_authors | 1000000 | 0.0149G | 0.0149G | 0.0298G |
| bookshop.ratings | 4000000 | 0.1192G | 0.1192G | 0.2384G |
| bookshop.authors | 100000 | 0.0043G | 0.0000G | 0.0043G |
| bookshop.users | 195348 | 0.0048G | 0.0021G | 0.0069G |
| bookshop.books | 1000000 | 0.0546G | 0.0000G | 0.0546G |
+-----------------------+----------------+-----------+------------+---------+
6 rows in set (0.03 sec)
テーブルの説明
このセクションでは、Bookshop アプリケーションのデータベース テーブルについて詳しく説明します。
booksテーブル
このテーブルには、書籍の基本情報が格納されます。
| フィールド名 | タイプ | 説明 |
|---|---|---|
| ID | bigint(20) | 書籍の一意の ID |
| 題名 | varchar(100) | 本のタイトル |
| タイプ | 列挙 | 書籍の種類 (雑誌、アニメ、教材など) |
| 株式 | bigint(20) | ストック |
| 価格 | 10 進数 (15,2) | 価格 |
| published_at | 日付時刻 | 発行日 |
authors表
このテーブルには、著者の基本情報が格納されます。
| フィールド名 | タイプ | 説明 |
|---|---|---|
| ID | bigint(20) | 著者の一意の ID |
| 名前 | varchar(100) | 著者名 |
| 性別 | tinyint(1) | 生物学的性別 (0: 女性、1: 男性、NULL: 不明) |
| 生年 | smallint(6) | 生年 |
| 死亡年 | smallint(6) | 没年 |
usersテーブル
このテーブルには、Bookshop ユーザーの情報が格納されます。
| フィールド名 | タイプ | 説明 |
|---|---|---|
| ID | bigint(20) | ユーザーの一意の ID |
| 残高 | 10 進数 (15,2) | バランス |
| ニックネーム | varchar(100) | ニックネーム |
ratings表
このテーブルには、書籍に対するユーザーの評価のレコードが格納されます。
| フィールド名 | タイプ | 説明 |
|---|---|---|
| book_id | bigint | 書籍の一意の ID ( 本にリンク) |
| ユーザーID | bigint | ユーザーの一意の識別子 ( ユーザーにリンク) |
| スコア | tinyint | ユーザー評価 (1-5) |
| rating_at | 日付時刻 | 評価時間 |
book_authorsテーブル
著者は複数の本を執筆する場合があり、1 つの本に複数の著者が関与する場合があります。このテーブルには、書籍と著者の間の対応が格納されます。
| フィールド名 | タイプ | 説明 |
|---|---|---|
| book_id | bigint(20) | 書籍の一意の ID ( 本にリンク) |
| author_id | bigint(20) | 著者固有ID( 著者へのリンク) |
orders表
このテーブルには、ユーザーの購入情報が格納されます。
| フィールド名 | タイプ | 説明 |
|---|---|---|
| ID | bigint(20) | 注文の一意の ID |
| book_id | bigint(20) | 書籍の一意の ID ( 本にリンク) |
| ユーザーID | bigint(20) | ユーザー固有の識別子 ( ユーザーに関連付けられている) |
| 量 | tinyint(4) | 購入数量 |
| order_at | 日付時刻 | 購入時期 |
データベース初期化スクリプトdbinit.sql
Bookshop アプリケーションでデータベース テーブル構造を手動で作成する場合は、次の SQL ステートメントを実行します。
CREATE DATABASE IF NOT EXISTS `bookshop`;
DROP TABLE IF EXISTS `bookshop`.`books`;
CREATE TABLE `bookshop`.`books` (
`id` bigint(20) AUTO_RANDOM NOT NULL,
`title` varchar(100) NOT NULL,
`type` enum('Magazine', 'Novel', 'Life', 'Arts', 'Comics', 'Education & Reference', 'Humanities & Social Sciences', 'Science & Technology', 'Kids', 'Sports') NOT NULL,
`published_at` datetime NOT NULL,
`stock` int(11) DEFAULT '0',
`price` decimal(15,2) DEFAULT '0.0',
PRIMARY KEY (`id`) CLUSTERED
) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
DROP TABLE IF EXISTS `bookshop`.`authors`;
CREATE TABLE `bookshop`.`authors` (
`id` bigint(20) AUTO_RANDOM NOT NULL,
`name` varchar(100) NOT NULL,
`gender` tinyint(1) DEFAULT NULL,
`birth_year` smallint(6) DEFAULT NULL,
`death_year` smallint(6) DEFAULT NULL,
PRIMARY KEY (`id`) CLUSTERED
) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
DROP TABLE IF EXISTS `bookshop`.`book_authors`;
CREATE TABLE `bookshop`.`book_authors` (
`book_id` bigint(20) NOT NULL,
`author_id` bigint(20) NOT NULL,
PRIMARY KEY (`book_id`,`author_id`) CLUSTERED
) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
DROP TABLE IF EXISTS `bookshop`.`ratings`;
CREATE TABLE `bookshop`.`ratings` (
`book_id` bigint NOT NULL,
`user_id` bigint NOT NULL,
`score` tinyint NOT NULL,
`rated_at` datetime NOT NULL DEFAULT NOW() ON UPDATE NOW(),
PRIMARY KEY (`book_id`,`user_id`) CLUSTERED,
UNIQUE KEY `uniq_book_user_idx` (`book_id`,`user_id`)
) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
ALTER TABLE `bookshop`.`ratings` SET TIFLASH REPLICA 1;
DROP TABLE IF EXISTS `bookshop`.`users`;
CREATE TABLE `bookshop`.`users` (
`id` bigint AUTO_RANDOM NOT NULL,
`balance` decimal(15,2) DEFAULT '0.0',
`nickname` varchar(100) UNIQUE NOT NULL,
PRIMARY KEY (`id`)
) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
DROP TABLE IF EXISTS `bookshop`.`orders`;
CREATE TABLE `bookshop`.`orders` (
`id` bigint(20) AUTO_RANDOM NOT NULL,
`book_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
`quality` tinyint(4) NOT NULL,
`ordered_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) CLUSTERED,
KEY `orders_book_id_idx` (`book_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin