TiDB クラスター間の双方向レプリケーション
このドキュメントでは、2 つの TiDB クラスター間の双方向レプリケーション、レプリケーションのしくみ、有効にする方法、および DDL 操作をレプリケートする方法について説明します。
ユーザーシナリオ
2 つの TiDB クラスターでデータの変更を相互に交換したい場合は、TiDB Binlogを使用してそれを行うことができます。たとえば、クラスタ A とクラスタ B が相互にデータをレプリケートするとします。
ノート:
これら 2 つのクラスターに書き込まれるデータは、競合がないようにする必要があります。つまり、2 つのクラスターで、同じ主キーまたはテーブルの一意のインデックスを持つ行を変更してはなりません。
ユーザー シナリオを以下に示します。
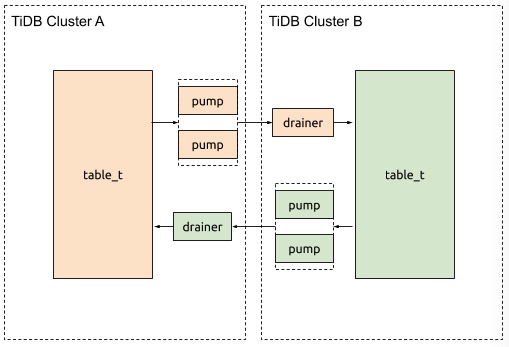
実装の詳細
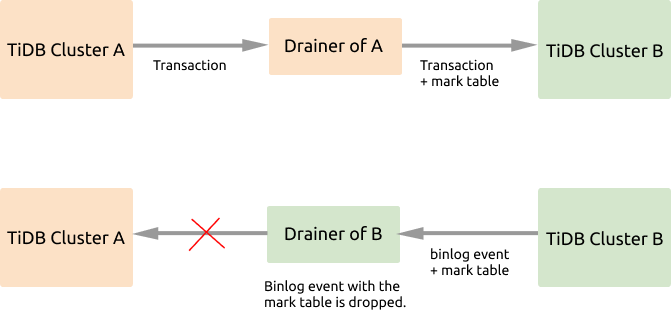
クラスタ A とクラスタ B の間で双方向のレプリケーションが有効になっている場合、クラスタ A に書き込まれたデータはクラスタ B にレプリケートされ、次にこれらのデータの変更がクラスタ A にレプリケートされるため、レプリケーションの無限ループが発生します。上の図から、データ レプリケーション中にDrainerがバイナリログ イベントをマークし、マークされたイベントを除外して、このようなレプリケーション ループを回避することがわかります。
詳細な実装は次のように説明されています。
- 2 つのクラスターのそれぞれに対して TiDB Binlogレプリケーション プログラムを開始します。
- レプリケートされるトランザクションがクラスタ A のDrainerを通過すると、このDrainerはトランザクションに
_drainer_repl_markテーブルを追加し、この DML イベントの更新をマーク テーブルに書き込み、このトランザクションをクラスタ B にレプリケートします。 - クラスタB は、
_drainer_repl_markのマーク テーブルを含む binlog イベントをクラスター A に返します。クラスター B のDrainerは、binlog イベントを解析するときに DML イベントを含むマーク テーブルを識別し、この binlog イベントをクラスター A にレプリケートすることを断念します。
クラスタ B からクラスタ A へのレプリケーション プロセスは、上記と同じです。 2 つのクラスターは、互いのアップストリームとダウンストリームになることができます。
ノート:
_drainer_repl_markマーク テーブルを更新する場合、バイナリログを生成するにはデータの変更が必要です。- DDL 操作はトランザクションではないため、一方向のレプリケーション方法を使用して DDL 操作をレプリケートする必要があります。詳細はDDL 操作をレプリケートするを参照してください。
Drainerは、競合を回避するために、ダウンストリームへの接続ごとに一意の ID を使用できます。 channel_idは、双方向レプリケーションのチャネルを示すために使用されます。 2 つのクラスターは、同じchannel_id構成 (同じ値) を持つ必要があります。
アップストリームで列を追加または削除すると、ダウンストリームにレプリケートされるデータの余分な列または欠落している列が存在する可能性があります。 Drainerは、余分な列を無視するか、欠落している列にデフォルト値を挿入することで、この状況を可能にします。
マークテーブル
_drainer_repl_markマーク テーブルの構造は次のとおりです。
CREATE TABLE `_drainer_repl_mark` (
`id` bigint(20) NOT NULL,
`channel_id` bigint(20) NOT NULL DEFAULT '0',
`val` bigint(20) DEFAULT '0',
`channel_info` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`,`channel_id`)
);
Drainerは次の SQL ステートメントを使用して_drainer_repl_markを更新します。これにより、データの変更と binlog の生成が保証されます。
update drainer_repl_mark set val = val + 1 where id = ? && channel_id = ?;
DDL 操作をレプリケートする
Drainerはマーク テーブルを DDL 操作に追加できないため、DDL 操作をレプリケートするには一方向のレプリケーション方法しか使用できません。
たとえば、クラスタ A からクラスタ B への DDL レプリケーションが有効になっている場合、クラスタ B からクラスタ A へのレプリケーションは無効になります。これは、すべての DDL 操作がクラスタ A で実行されることを意味します。
ノート:
DDL 操作は、2 つのクラスターで同時に実行できません。 DDL 操作の実行時に、DML 操作が同時に実行されている場合、または DML バイナリログが複製されている場合、DML 複製の上流と下流のテーブル構造が一致しない可能性があります。
双方向レプリケーションを構成して有効にする
クラスター A とクラスター B 間の双方向レプリケーションの場合、すべての DDL 操作がクラスター A で実行されると想定します。クラスター A からクラスター B へのレプリケーション パスで、次の構成をDrainerに追加します。
[syncer]
loopback-control = true
channel-id = 1 # Configures the same ID for both clusters to be replicated.
sync-ddl = true # Enables it if you need to perform DDL replication.
[syncer.to]
# 1 means SyncFullColumn and 2 means SyncPartialColumn.
# If set to SyncPartialColumn, Drainer allows the downstream table
# structure to have more or fewer columns than the data to be replicated
# And remove the STRICT_TRANS_TABLES of the SQL mode to allow fewer columns, and insert zero values to the downstream.
sync-mode = 2
# Ignores the checkpoint table.
[[syncer.ignore-table]]
db-name = "tidb_binlog"
tbl-name = "checkpoint"
クラスター B からクラスター A へのレプリケーション パスで、次の構成をDrainerに追加します。
[syncer]
loopback-control = true
channel-id = 1 # Configures the same ID for both clusters to be replicated.
sync-ddl = false # Disables it if you do not need to perform DDL replication.
[syncer.to]
# 1 means SyncFullColumn and 2 means SyncPartialColumn.
# If set to SyncPartialColumn, Drainer allows the downstream table
# structure to have more or fewer columns than the data to be replicated
# And remove the STRICT_TRANS_TABLES of the SQL mode to allow fewer columns, and insert zero values to the downstream.
sync-mode = 2
# Ignores the checkpoint table.
[[syncer.ignore-table]]
db-name = "tidb_binlog"
tbl-name = "checkpoint"