大規模なリージョンでの TiKV性能チューニングのベスト プラクティス
TiDB では、データはリージョンに分割され、それぞれが特定のキー範囲のデータを格納します。これらのリージョンは、複数の TiKV インスタンスに分散されています。データがクラスターに書き込まれると、数百万または数千万のリージョンが作成されます。 1 つの TiKV インスタンスにリージョンが多すぎると、クラスターに大きな負荷がかかり、パフォーマンスに影響を与える可能性があります。
このドキュメントでは、Raftstore (TiKV のコア モジュール) のワークフローを紹介し、大量のリージョンがパフォーマンスに影響を与える理由を説明し、TiKV のパフォーマンスを調整する方法を提供します。
ラフトストアのワークフロー
TiKV インスタンスには複数のリージョンがあります。 Raftstore モジュールはRaftステート マシンを駆動してリージョンメッセージを処理します。これらのメッセージには、リージョンでの読み取りまたは書き込みリクエストの処理、 Raftログの永続化または複製、およびRaftハートビートの処理が含まれます。ただし、リージョンの数が増えると、クラスター全体のパフォーマンスに影響を与える可能性があります。これを理解するには、以下に示す Raftstore のワークフローを学ぶ必要があります。
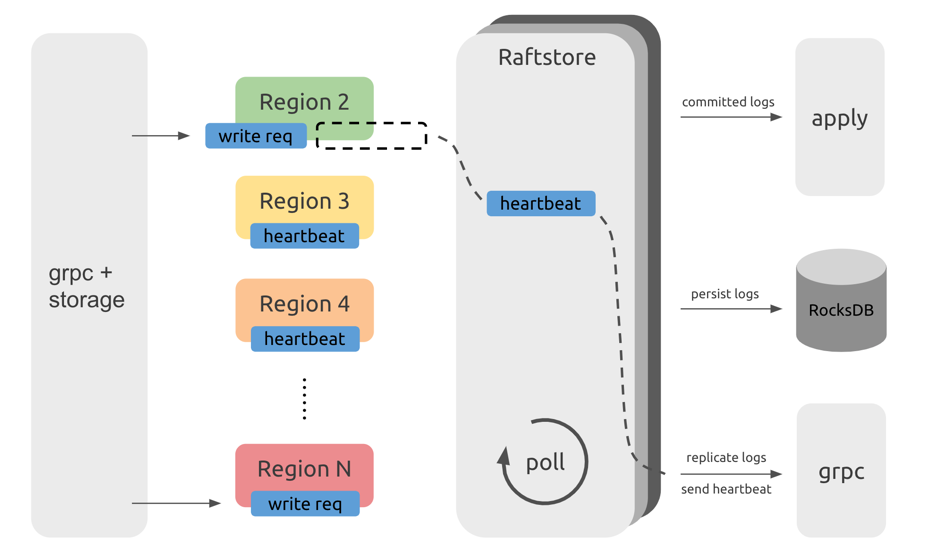
ノート:
この図は、Raftstore のワークフローを示しているだけで、実際のコード構造を表しているわけではありません。
上記の図から、TiDB サーバーからのリクエストは、gRPC とストレージ モジュールを通過した後、KV (key-value) の読み書きメッセージになり、対応するリージョンに送信されることがわかります。これらのメッセージはすぐには処理されず、一時的に保存されます。 Raftstore は、各リージョンに処理するメッセージがあるかどうかを確認するためにポーリングします。リージョンに処理するメッセージがある場合、Raftstore はこのリージョンのRaftステート マシンを駆動してこれらのメッセージを処理し、これらのメッセージの状態変化に従って後続の操作を実行します。たとえば、書き込みリクエストが来ると、 Raftステート マシンはログをディスクに保存し、ログを他のリージョンレプリカに送信します。ハートビート間隔に達すると、 Raftステート マシンはハートビート情報を他のリージョンレプリカに送信します。
パフォーマンスの問題
Raftstore ワークフロー図から、各リージョンのメッセージが 1 つずつ処理されます。多数のリージョンが存在する場合、Raftstore がこれらのリージョンのハートビートを処理するのに時間がかかり、遅延が発生する可能性があります。その結果、一部の読み取りおよび書き込み要求が時間内に処理されません。読み取りと書き込みの負荷が高い場合、Raftstore スレッドの CPU 使用率がボトルネックになりやすく、遅延がさらに増加し、パフォーマンスに影響を与えます。
通常、読み込んだ Raftstore の CPU 使用率が 85% 以上になると、Raftstore がビジー状態になり、ボトルネックになります。同時に、 propose wait durationは数百ミリ秒にもなることがあります。
ノート:
- 上記の Raftstore の CPU 使用率については、Raftstore はシングルスレッドです。 Raftstore がマルチスレッドの場合、CPU 使用率のしきい値 (85%) を比例して増やすことができます。
- Raftstore スレッドには I/O 操作が存在するため、CPU 使用率が 100% に達することはありません。
パフォーマンス監視
Grafana のTiKV ダッシュボードで、次のモニタリング メトリックを確認できます。
スレッド CPUパネルの
Raft store CPU参考値:
raftstore.store-pool-size * 85%未満。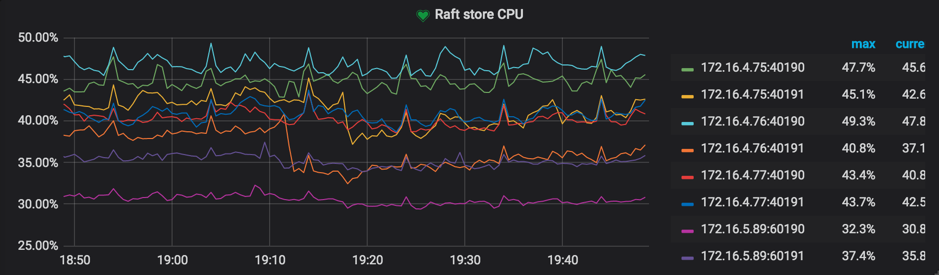
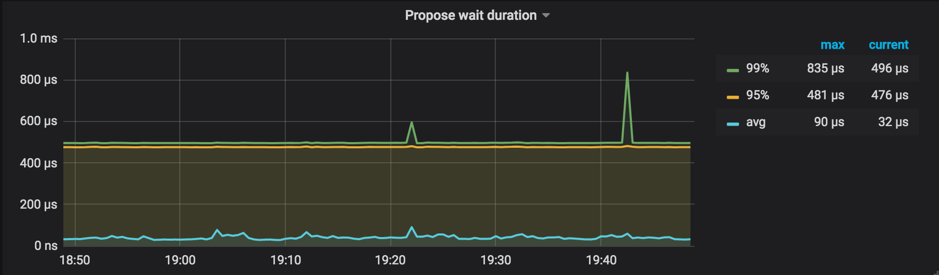
Raft Proposeパネルの
Propose wait durationPropose wait durationは、リクエストが Raftstore に送信されてから Raftstore が実際にリクエストの処理を開始するまでの遅延です。長い遅延は、Raftstore がビジーであるか、追加ログの処理に時間がかかり、Raftstore が時間内にリクエストを処理できないことを意味します。参考値:クラスタサイズに応じて50~100ミリ秒未満
パフォーマンス チューニング方法
パフォーマンスの問題の原因を突き止めたら、次の 2 つの側面から解決を試みます。
- 単一の TiKV インスタンスでリージョンの数を減らす
- 1 つのリージョンのメッセージ数を減らす
方法 1: Raftstore の同時実行数を増やす
Raftstore は TiDB v3.0 以降、マルチスレッド モジュールにアップグレードされており、Raftstore スレッドがボトルネックになる可能性が大幅に減少しています。
デフォルトでは、TiKV ではraftstore.store-pool-sizeが2に設定されています。 Raftstore でボトルネックが発生した場合、状況に応じてこの構成項目の値を適切に増やすことができます。ただし、不要なスレッド切り替えのオーバーヘッドが発生しないようにするには、この値をあまり高く設定しないことをお勧めします。
方法 2: 休止リージョンを有効にする
実際の状況では、読み取りおよび書き込みリクエストはすべてのリージョンに均等に分散されていません。代わりに、それらはいくつかの地域に集中しています。次に、Hibernate リージョンの機能である、一時的にアイドル状態のリージョンのRaftリーダーとフォロワーの間のメッセージの数を最小限に抑えることができます。この機能では、必要がない場合、Raftstore はアイドル状態のリージョンのRaftステート マシンにティック メッセージを送信します。その後、これらのRaftステート マシンはトリガーされてハートビート メッセージを生成しなくなり、Raftstore のワークロードを大幅に削減できます。
TiKVマスターでは、Hibernate リージョンがデフォルトで有効になっています。この機能は、必要に応じて構成できます。詳細は休止リージョンの構成を参照してください。
方法 3: Region Merge有効にする
ノート:
TiDB v3.0 以降、デフォルトで
Region Mergeが有効になっています。
Region Mergeを有効にすることで、リージョンの数を減らすこともできます。 Region Splitとは逆に、 Region Mergeはスケジューリングによって隣接する小さなリージョンをマージするプロセスです。データをドロップするか、 Drop TableまたはTruncate Tableステートメントを実行した後、小さなリージョンまたは空のリージョンをマージして、リソースの消費を減らすことができます。
次のパラメータを設定してRegion Mergeを有効にします。
config set max-merge-region-size 20
config set max-merge-region-keys 200000
config set merge-schedule-limit 8
詳細については、 リージョンマージおよび 3 の次のPD 構成ファイルつの構成パラメーターを参照してください。
Region Mergeパラメータのデフォルト設定はかなり保守的です。 PD スケジューリングのベスト プラクティスで提供されている方法を参照すると、 Region Mergeのプロセスを高速化できます。
方法 4: TiKV インスタンスの数を増やす
I/O リソースと CPU リソースが十分であれば、単一のマシンに複数の TiKV インスタンスをデプロイして、単一の TiKV インスタンスのリージョン数を減らすことができます。または、TiKV クラスター内のマシンの数を増やすことができます。
方法 5: raft-base-tick-interval調整する
リージョンの数を減らすことに加えて、単位時間内の各リージョンのメッセージ数を減らすことで、Raftstore へのプレッシャーを軽減することもできます。たとえば、 raft-base-tick-intervalの構成アイテムの値を適切に増やすことができます。
[raftstore]
raft-base-tick-interval = "2s"
上記の設定では、 raft-base-tick-intervalは Raftstore が各リージョンのRaftステート マシンを駆動する時間間隔です。つまり、この時間間隔で Raftstore はRaftステート マシンにティック メッセージを送信します。この間隔を長くすると、Raftstore からのメッセージの数を効果的に減らすことができます。
この tick メッセージ間の間隔は、 election timeoutとheartbeatの間の間隔も決定することに注意してください。次の例を参照してください。
raft-election-timeout = raft-base-tick-interval * raft-election-timeout-ticks
raft-heartbeat-interval = raft-base-tick-interval * raft-heartbeat-ticks
リージョンフォロワーがraft-election-timeout間隔内にリーダーからハートビートを受信しなかった場合、これらのフォロワーはリーダーが失敗したと判断し、新しい選挙を開始します。 raft-heartbeat-intervalは、リーダーがフォロワーにハートビートを送信する間隔です。したがって、 raft-base-tick-intervalの値を増やすと、 Raftステート マシンから送信されるネットワーク メッセージの数を減らすことができますが、 Raftステート マシンがリーダーの障害を検出する時間が長くなります。
方法 6:リージョンサイズを調整する
リージョンのデフォルト サイズは 96 MiB であり、リージョンをより大きなサイズに設定することで、リージョンの数を減らすことができます。詳細については、 リージョンのパフォーマンスを調整するを参照してください。
その他の問題と解決策
このセクションでは、その他の問題と解決策について説明します。
PD リーダーの切り替えが遅い
PD は、PD リーダー ノードを切り替えた後、PD がリージョンルーティング サービスの提供を迅速に再開できるように、リージョンメタ情報を etcd に保持する必要があります。リージョンの数が増えると、etcd のパフォーマンスの問題が発生し、PD がリーダーを切り替えるときに PD が etcd からリージョンメタ情報を取得するのが遅くなります。何百万ものリージョンがあると、etcd からメタ情報を取得するのに 10 秒以上、場合によっては数十秒かかる場合があります。
この問題に対処するために、TiDB v3.0 以降の PD ではデフォルトでuse-region-storageが有効になっています。この機能を有効にすると、PD はリージョンメタ情報をローカルの LevelDB に保存し、他のメカニズムを通じて PD ノード間で情報を同期します。
PD ルーティング情報の更新が間に合わない
TiKV では、pd-worker が定期的にリージョン Meta 情報を PD に報告します。 TiKV が再起動されるか、リージョンリーダーが切り替えられると、PD は統計を通じてリージョンのapproximate size / keysを再計算する必要があります。したがって、リージョン数が多いと、シングルスレッドの pd-worker がボトルネックになり、タスクが積み重なって時間内に処理されない可能性があります。この状況では、PD は特定のリージョンメタ情報を時間内に取得できないため、ルーティング情報が時間内に更新されません。この問題は実際の読み取りと書き込みには影響しませんが、PD スケジューリングが不正確になり、TiDB がリージョンキャッシュを更新するときに数回のラウンド トリップが必要になる可能性があります。
TiKV Grafanaパネルの[タスク] でワーカーの保留中のタスクを確認して、pd-worker にタスクが積み上げられているかどうかを判断できます。一般に、 pending tasksは比較的低い値に維持する必要があります。
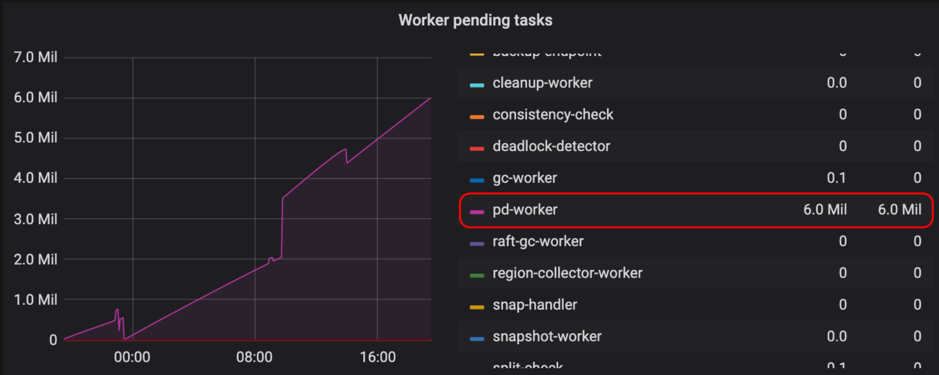
pd-worker はv3.0.5以降、パフォーマンスを向上させるために最適化されています。同様の問題が発生した場合は、最新バージョンにアップグレードすることをお勧めします。
Prometheus によるメトリクスのクエリが遅い
大規模なクラスターでは、TiKV インスタンスの数が増えると、Prometheus がメトリックをクエリするプレッシャーが大きくなり、Grafana がこれらのメトリックを表示するのが遅くなります。この問題を緩和するために、v3.0 以降、メトリクスの事前計算が構成されています。