配置ルール
ノート:
このドキュメントでは、配置Driver(PD) で配置ルールを手動で指定する方法を紹介します。 SQL の配置規則の使用が推奨されるようになりました。これにより、テーブルとパーティションの配置を構成するためのより便利な方法が提供されます。
v5.0 で導入された Placement Rules は、PD がさまざまなタイプのデータに対応するスケジュールを生成するように導くレプリカ ルール システムです。さまざまなスケジューリング ルールを組み合わせることで、レプリカの数、ストレージの場所、ホストの種類、 Raft選出に参加するかどうか、 Raftリーダーとして機能するかどうかなど、連続するデータ範囲の属性を細かく制御できます。
配置ルール機能は、v5.0 以降のバージョンの TiDB ではデフォルトで有効になっています。無効にするには、 配置ルールを無効にするを参照してください。
ルール体系
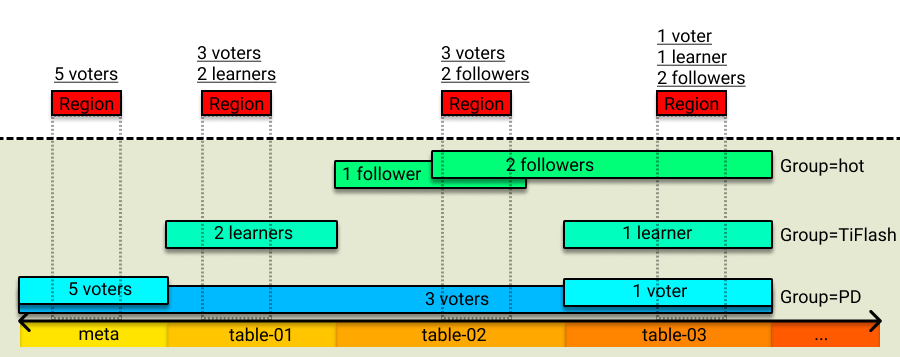
ルールシステム全体の構成は、複数のルールで構成されています。各ルールは、レプリカの数、 Raftロール、配置場所、このルールが有効になるキー範囲などの属性を指定できます。 PD がスケジュールを実行するとき、最初にリージョンのキー範囲に従ってルール システムでリージョンに対応するルールを見つけ、次に対応するスケジュールを生成してリージョンレプリカの配布をルールに準拠させます。
複数のルールのキー範囲は重複する部分を持つことができます。つまり、リージョンは複数のルールに一致する可能性があります。この場合、PD は、ルールの属性に応じて、ルールが相互に上書きされるか、同時に有効になるかを決定します。複数のルールが同時に有効になる場合、PD はルール マッチングのルールの重なり順に従ってスケジュールを順番に生成します。
さらに、異なるソースからのルールを互いに分離するという要件を満たすために、これらのルールをより柔軟な方法で編成できます。そこで「グループ」という概念を導入。一般に、ユーザーはさまざまなソースに従ってさまざまなグループにルールを配置できます。
ルール フィールド
次の表は、ルールの各フィールドの意味を示しています。
| フィールド名 | 種類と制限 | 説明 |
|---|---|---|
GroupID | string | ルールのソースをマークするグループ ID。 |
ID | string | グループ内のルールの一意の ID。 |
Index | int | グループ内のルールのスタック シーケンス。 |
Override | true / false | インデックスが小さいルールを (グループ内で) 上書きするかどうか。 |
StartKey | string 、16 進形式 | 範囲の開始キーに適用されます。 |
EndKey | string 、16 進形式 | 範囲の終了キーに適用されます。 |
Role | string | リーダー/フォロワー/学習者を含むレプリカの役割。 |
Count | int 、正の整数 | レプリカの数。 |
LabelConstraint | []Constraint | ラベルに基づいてノードをフィルタリングします。 |
LocationLabels | []string | 物理的な分離に使用されます。 |
IsolationLevel | string | 最小の物理的分離レベルを設定するために使用されます |
LabelConstraintは、次の 4 つのプリミティブ ( in 、 notIn 、 exists 、およびnotExists ) に基づいてラベルをフィルタリングする Kubernetes の関数に似ています。これら 4 つのプリミティブの意味は次のとおりです。
in: 指定されたキーのラベル値が指定されたリストに含まれます。notIn: 指定されたキーのラベル値は、指定されたリストに含まれていません。exists: 指定されたラベル キーを含めます。notExists: 指定されたラベル キーを含めません。
LocationLabelsの意味と機能は、v4.0 より前のものと同じです。たとえば、3 層トポロジーを定義する[zone,rack,host]をデプロイした場合: クラスターには複数のゾーン (アベイラビリティーゾーン) があり、各ゾーンには複数のラックがあり、各ラックには複数のホストがあります。スケジュールを実行するとき、PD は最初にリージョンのピアを異なるゾーンに配置しようとします。この試行が失敗した場合 (レプリカが 3 つあるのに合計で 2 つのゾーンしかないなど)、PD はこれらのレプリカを異なるラックに配置することを保証します。ラックの数が分離を保証するのに十分でない場合、PD はホスト レベルの分離を試みます。
IsolationLevelの意味と機能はクラスタトポロジ構成で詳述されています。たとえば、 LocationLabelsで 3 層トポロジを定義する[zone,rack,host]をデプロイし、 IsolationLevelをzoneに設定した場合、PD は、スケジューリング中に各リージョンのすべてのピアが異なるゾーンに配置されるようにします。 IsolationLevelの最小分離レベル制限を満たすことができない場合 (たとえば、3 つのレプリカが構成されているが、合計で 2 つのデータ ゾーンしかない場合)、PD はこの制限を満たすために補おうとはしません。デフォルト値のIsolationLevelは空の文字列で、無効になっていることを意味します。
ルール グループのフィールド
次の表に、ルール グループの各フィールドの説明を示します。
| フィールド名 | 種類と制限 | 説明 |
|---|---|---|
ID | string | ルールのソースをマークするグループ ID。 |
Index | int | 異なるグループのスタック シーケンス。 |
Override | true / false | より小さいインデックスでグループをオーバーライドするかどうか。 |
ルールを構成する
このセクションの操作はpd-ctlに基づいており、操作に含まれるコマンドは HTTP API 経由の呼び出しもサポートしています。
配置ルールを有効にする
配置ルール機能は、v5.0 以降のバージョンの TiDB ではデフォルトで有効になっています。無効にするには、 配置ルールを無効にするを参照してください。この機能を無効にした後で有効にするには、クラスターを初期化する前に PD 構成ファイルを次のように変更します。
[replication]
enable-placement-rules = true
このように、クラスターが正常にブートストラップされた後、PD はこの機能を有効にし、 max-replicasとlocation-labelsの構成に従って対応するルールを生成します。
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3,
"location_labels": ["zone", "rack", "host"],
"isolation_level": ""
}
ブートストラップされたクラスターの場合、pd-ctl を使用して配置ルールをオンラインで有効にすることもできます。
pd-ctl config placement-rules enable
PD は、 max-replicasとlocation-labelsの構成に基づいてデフォルトのルールも生成します。
ノート:
配置ルールを有効にすると、以前に構成した
max-replicasとlocation-labelsは無効になります。レプリカ ポリシーを調整するには、配置ルールに関連するインターフェイスを使用します。
配置ルールを無効にする
pd-ctl を使用して配置ルール機能を無効にし、以前のスケジューリング戦略に切り替えることができます。
pd-ctl config placement-rules disable
ノート:
配置ルールを無効にした後、PD は元の
max-replicasとlocation-labelsの構成を使用します。ルールを変更しても (配置ルールが有効になっている場合)、これら 2 つの構成はリアルタイムで更新されません。さらに、構成されたすべてのルールは PD に残り、次に配置ルールを有効にするときに使用されます。
pd-ctl を使用してルールを設定する
ノート:
ルールの変更は、PD スケジューリングにリアルタイムで影響します。ルールの設定が不適切な場合、レプリカが少なくなり、システムの高可用性に影響を与える可能性があります。
pd-ctl は、次のメソッドを使用してシステム内のルールを表示することをサポートしており、出力は JSON 形式のルールまたはルール リストです。
- すべてのルールのリストを表示するには:
```bash
pd-ctl config placement-rules show
```
- PD グループ内のすべてのルールのリストを表示するには:
```bash
pd-ctl config placement-rules show --group=pd
```
- グループ内の特定の ID のルールを表示するには:
```bash
pd-ctl config placement-rules show --group=pd --id=default
```
- リージョンに一致するルール リストを表示するには:
```bash
pd-ctl config placement-rules show --region=2
```
上記の例では、 `2`がリージョンID です。
ルールの追加とルールの編集は似ています。対応するルールをファイルに書き込んでから、 saveコマンドを使用してルールを PD に保存する必要があります。
cat > rules.json <<EOF
[
{
"group_id": "pd",
"id": "rule1",
"role": "voter",
"count": 3,
"location_labels": ["zone", "rack", "host"]
},
{
"group_id": "pd",
"id": "rule2",
"role": "voter",
"count": 2,
"location_labels": ["zone", "rack", "host"]
}
]
EOF
pd-ctl config placement save --in=rules.json
上記の操作により、PD にrule1とrule2が書き込まれます。同じGroupID + IDのルールがシステムに既に存在する場合、このルールは上書きされます。
ルールを削除するには、ルールのcountを0に設定するだけで、同じGroupID + IDのルールが削除されます。次のコマンドは、 pd / rule2ルールを削除します。
cat > rules.json <<EOF
[
{
"group_id": "pd",
"id": "rule2"
}
]
EOF
pd-ctl config placement save --in=rules.json
pd-ctl を使用してルール グループを構成する
- すべてのルール グループのリストを表示するには:
```bash
pd-ctl config placement-rules rule-group show
```
- 特定の ID のルール グループを表示するには:
```bash
pd-ctl config placement-rules rule-group show pd
```
- ルール グループの
indexとoverrideの属性を設定するには、次のようにします。
```bash
pd-ctl config placement-rules rule-group set pd 100 true
```
- ルール グループの構成を削除するには (グループにルールがある場合は、既定のグループ構成を使用します):
```bash
pd-ctl config placement-rules rule-group delete pd
```
pd-ctl を使用して、グループとグループ内のルールをバッチ更新します
ルール グループとグループ内のすべてのルールを同時に表示および変更するには、 rule-bundleサブコマンドを実行します。
このサブコマンドでは、グループを照会するためにget {group_id}が使用され、出力結果にはルール グループとグループのルールがネストされた形式で表示されます。
pd-ctl config placement-rules rule-bundle get pd
上記のコマンドの出力:
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3
}
]
}
出力をファイルに書き込むには、 --out引数をrule-bundle getサブコマンドに追加します。これは、その後の変更と保存に便利です。
pd-ctl config placement-rules rule-bundle get pd --out="group.json"
変更が完了したら、 rule-bundle setサブコマンドを使用して、ファイル内の構成を PDサーバーに保存できます。 pd-ctl を使用してルールを設定するで説明されているsaveコマンドとは異なり、このコマンドはサーバー側でこのグループのすべてのルールを置き換えます。
pd-ctl config placement-rules rule-bundle set pd --in="group.json"
pd-ctl を使用して、すべての構成を表示および変更します
pd-ctl を使用して、すべての構成を表示および変更することもできます。これを行うには、すべての構成をファイルに保存し、構成ファイルを編集してから、ファイルを PDサーバーに保存して、以前の構成を上書きします。この操作もrule-bundleサブコマンドを使用します。
たとえば、すべての設定をrules.jsonのファイルに保存するには、次のコマンドを実行します。
pd-ctl config placement-rules rule-bundle load --out="rules.json"
ファイルを編集したら、次のコマンドを実行して構成を PDサーバーに保存します。
pd-ctl config placement-rules rule-bundle save --in="rules.json"
tidb-ctl を使用してテーブル関連のキー範囲をクエリする
メタデータまたは特定のテーブルに特別な構成が必要な場合は、 keyrangeコマンド in tidb-ctlを実行して関連するキーをクエリできます。コマンドの最後に--encodeを忘れずに追加してください。
tidb-ctl keyrange --database test --table ttt --encode
global ranges:
meta: (6d00000000000000f8, 6e00000000000000f8)
table: (7400000000000000f8, 7500000000000000f8)
table ttt ranges: (NOTE: key range might be changed after DDL)
table: (7480000000000000ff2d00000000000000f8, 7480000000000000ff2e00000000000000f8)
table indexes: (7480000000000000ff2d5f690000000000fa, 7480000000000000ff2d5f720000000000fa)
index c2: (7480000000000000ff2d5f698000000000ff0000010000000000fa, 7480000000000000ff2d5f698000000000ff0000020000000000fa)
index c3: (7480000000000000ff2d5f698000000000ff0000020000000000fa, 7480000000000000ff2d5f698000000000ff0000030000000000fa)
index c4: (7480000000000000ff2d5f698000000000ff0000030000000000fa, 7480000000000000ff2d5f698000000000ff0000040000000000fa)
table rows: (7480000000000000ff2d5f720000000000fa, 7480000000000000ff2e00000000000000f8)
ノート:
DDL およびその他の操作によってテーブル ID が変更される可能性があるため、対応するルールを同時に更新する必要があります。
一般的な使用シナリオ
このセクションでは、配置ルールの一般的な使用シナリオを紹介します。
シナリオ 1: 通常のテーブルに 3 つのレプリカを使用し、メタデータに 5 つのレプリカを使用してクラスターの耐災害性を向上させる
キー範囲をメタデータの範囲に制限するルールを追加し、 countから5の値を設定するだけです。このルールの例を次に示します。
{
"group_id": "pd",
"id": "meta",
"index": 1,
"override": true,
"start_key": "6d00000000000000f8",
"end_key": "6e00000000000000f8",
"role": "voter",
"count": 5,
"location_labels": ["zone", "rack", "host"]
}
シナリオ 2: 3 つのデータ センターに 5 つのレプリカを 2:2:1 の比率で配置し、リーダーは 3 番目のデータ センターに配置しない
3 つのルールを作成します。レプリカの数をそれぞれ2 、 2 、および1に設定します。レプリカを、各ルールでlabel_constraintsまでの対応するデータ センターに制限します。さらに、リーダーを必要としないデータセンターの場合は、 roleをfollowerに変更します。
[
{
"group_id": "pd",
"id": "zone1",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 2,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone1"]}
],
"location_labels": ["rack", "host"]
},
{
"group_id": "pd",
"id": "zone2",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 2,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone2"]}
],
"location_labels": ["rack", "host"]
},
{
"group_id": "pd",
"id": "zone3",
"start_key": "",
"end_key": "",
"role": "follower",
"count": 1,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone3"]}
],
"location_labels": ["rack", "host"]
}
]
シナリオ 3: テーブルに 2 つの TiFlash レプリカを追加する
テーブルの行キーに別のルールを追加し、 count ~ 2に制限します。 label_constraintsを使用して、レプリカがengine = tiflashのノードで生成されるようにします。ここでは、このルールがシステム内の他のソースからのルールと重複または競合しないように、別のgroup_idが使用されていることに注意してください。
{
"group_id": "tiflash",
"id": "learner-replica-table-ttt",
"start_key": "7480000000000000ff2d5f720000000000fa",
"end_key": "7480000000000000ff2e00000000000000f8",
"role": "learner",
"count": 2,
"label_constraints": [
{"key": "engine", "op": "in", "values": ["tiflash"]}
],
"location_labels": ["host"]
}
シナリオ 4: 高性能ディスクを備えた北京ノードのテーブルに 2 つのフォロワー レプリカを追加する
次の例は、より複雑なlabel_constraints構成を示しています。このルールでは、レプリカはbj1またはbj2のマシン ルームに配置する必要があり、ディスク タイプはssdであってはなりません。
{
"group_id": "follower-read",
"id": "follower-read-table-ttt",
"start_key": "7480000000000000ff2d00000000000000f8",
"end_key": "7480000000000000ff2e00000000000000f8",
"role": "follower",
"count": 2,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["bj1", "bj2"]},
{"key": "disk", "op": "notIn", "values": ["ssd"]}
],
"location_labels": ["host"]
}
シナリオ 5: テーブルを TiFlash クラスターに移行する
シナリオ 3 とは異なり、このシナリオでは、既存の構成に基づいて新しいレプリカを追加するのではなく、データ範囲の他の構成を強制的にオーバーライドします。したがって、既存のルールをオーバーライドするには、ルール グループの設定で十分な大きさのindex値を指定し、 override ~ trueを設定する必要があります。
ルール:
{
"group_id": "tiflash-override",
"id": "learner-replica-table-ttt",
"start_key": "7480000000000000ff2d5f720000000000fa",
"end_key": "7480000000000000ff2e00000000000000f8",
"role": "voter",
"count": 3,
"label_constraints": [
{"key": "engine", "op": "in", "values": ["tiflash"]}
],
"location_labels": ["host"]
}
ルール グループ:
{
"id": "tiflash-override",
"index": 1024,
"override": true,
}